Oh, that error….
Perhaps you’ve seen it before: “Unable to process request: Concurrent requests limit exceeded”. This is the Apex concurrency limiter giving you a “speeding ticket”.
 Believe it or not, the Apex concurrency limit is your friend. It isolates several failure scenarios and contains them from propagation across the Salesforce App Cloud, which might otherwise simultaneously impact thousands of customers; including you.
Believe it or not, the Apex concurrency limit is your friend. It isolates several failure scenarios and contains them from propagation across the Salesforce App Cloud, which might otherwise simultaneously impact thousands of customers; including you.
While you may not have seen the warning screen, many have, and all too often the “go to” response is to suspect the problem lies in the platform. Not so fast! If I’m being honest (I am, promise), the limit is a necessary evil, and, when an org gets hit with the error, it’s often because of factors that lie outside of the platform.
Think of it like this: We don’t like issuing speeding tickets and you don’t like receiving them. So, the intent of this document is to dig into one common factor and equip you with knowledge to insulate your org from further impact.
Sound familiar?
In this case, I’m referring to synchronous callouts. When it’s necessary to integrate with an external service, synchronous callouts are widely used because the implementation is simple; you send the request, block the thread, and wait for the response. Furthermore, synchronous callouts often go to services which make additional callouts in a chain. Callouts of this nature are notoriously fragile due to the unpredictable nature of WAN latency, remote systems and their subsequent dependency’s performance profiles. Consequently, one of the key risks in this style of integration is that of cascading failure.
Additionally, all the response times in the chain are cumulative, which can quickly grow and degrade the user experience!
For example, a callout from a Visualforce page to your middleware app A to backend B to cache C to database D can, at any point during the chain, hang waiting for a response to the next downstream service because of <insert any of a million reasons here>.
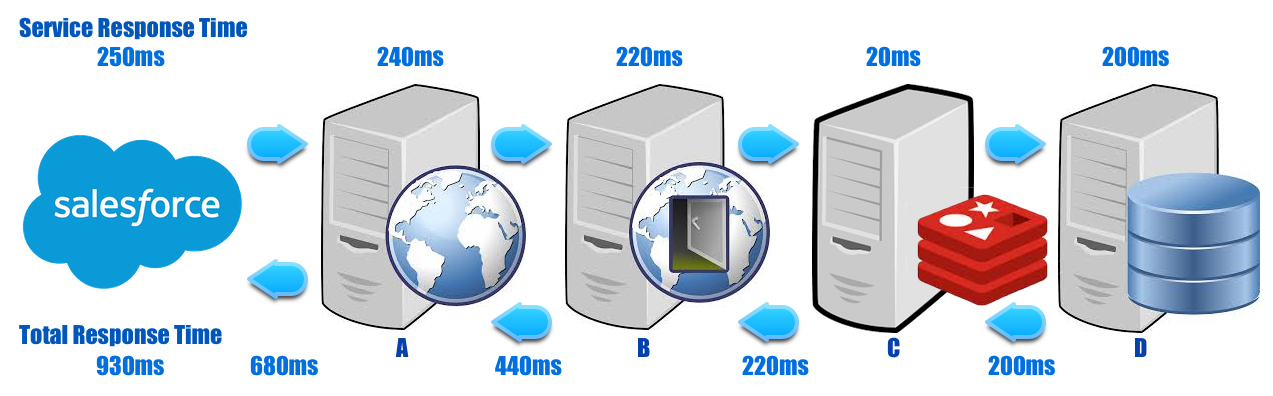
Naturally, these are highly transactional services, so those stuck threads pile up fast and exhaust the service resources. At that point, subsequent requests begin to see “Server too busy” errors or hang, waiting for an available request handler thread. Worse still, assuming this started with the database, D, the error then moves upwards from C, to B, to A and finally, the platform. Without defensive engineering, everything clogs up along the chain.
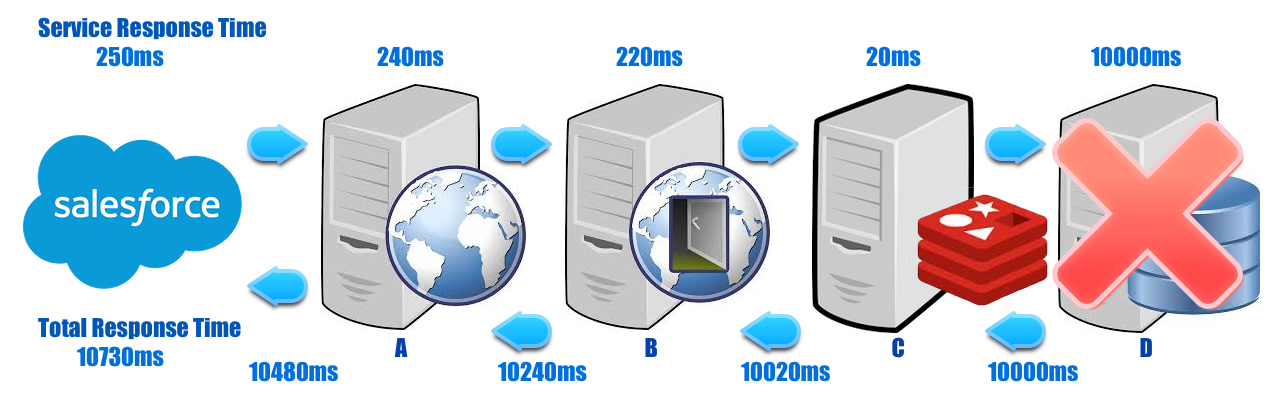
Defensive strategies exist for this scenario, and others like it! Owners of these disparate services should implement some mechanism to prevent cascading failure such as “Fail Fast”, “Circuit Breakers”, etc (outlined later on this post). However, this is often not done. Thus, the failure cascades into the platform and we “pull you over” to stop accepting further requests from your org until the number of waiting requests is reduced.
Hmph, familiar. So now what?
Whether or not you can build resiliency into those downstream services, (you should if you can!) there are steps that should be taken to minimize the effects of slow synchronous callouts in your Salesforce application. The platform has callout features you can adapt to your use case, and reduce hitting the Apex concurrency limit error.
As discussed elsewhere, the Apex concurrency limit is a fixed number of concurrent requests that an org is allowed to have running past a certain duration threshold. For the purposes of this doc, we’ll assume it’s 10 requests at 5 seconds each.
Doesn’t sound like much? Perhaps it would help to know that there are customers with millions of requests with callouts that, every day, somehow managed to avoid hitting the limit! I will show you how to do just that.
Why so synchronous? The suboptimal approach
To better illustrate how best to implement callout behavior, let’s take a closer look at the suboptimal approach, which we can then juxtapose to the alternatives. Take, for example, a simple Visualforce page that makes a callout to
an external service which is either slow or susceptible to the aforementioned millions of performance fluctuations.

This is risky! If the service takes longer than 5 seconds (someday it will) to respond and there are more than 10 of these page requests in-flight, you are susceptible to Apex concurrency limit errors from all your Visualforce pages, SOAP requests, REST requests, etc., not just those pages that are currently long-running!
Synchronous callout example
To illustrate, I’m using a homegrown Node.js app on Heroku which takes a duration parameter and essentially ‘sleeps’ before returning the response. As you can see in the code examples below, the page makes a synchronous callout to an HTTP URL and waits for the response which is then displayed in the page messages.
Does the following look familiar? Granted, many of you have wrapped the HttpRequest bits into a helper class, but it’s essentially the same pattern:
Synchronous Visualforce page code
Synchronous controller code
But I learned this by watching you!
Fine, there is plenty of documentation that models this approach yet doesn’t subject you to reams of diatribe on how to implement safe, synchronous callouts. Also, other sites <cough>Sourceforge</ cough> have sprinklings of good advice which usually falls prey to the TL;DR filter. Ultimately, there is too much adoption of “the wrong way”, which is why I wrote this document.
Thus, I submit to you: “Making a synchronous callout the right way”:
Single continuation example: an optimized approach
This case uses the asynchronous callout framework in the platform to perform long running (up to 60 seconds each) callouts without tying up the application server thread and prevents being counted against the Apex concurrency limit.

You’ll notice three key changes from the Synchronous example:
- Added JavaScript to the Visualforce page to disable the submit button and update the label to ‘Submitted…’ and
- Moved the response handling logic to a separate callback handler method.
- Added a ‘reRender’ target to the submit button.
The reason for #1 is because, once submitted, the browser shows no indication of a page load. No spinny icons, no animations, etc. This is due to how continuation works under the hood; The page request is submitted to the server while JavaScript in the page polls for a response.
The reason, of course, for #2 is because without a callback handler method we wouldn’t be able to update the page with success/error results.
Third, #3 is added because without it, the callback method will not be invoked and your results will not be displayed in the page.
Here’s the code:
Single continuation Visualforce page code
Single continuation controller code
I want to affirm some of the key take aways from this pattern:
- It effectively eliminates the need for synchronous callouts in Visualforce pages. Stop using them or use “Fail Fast” or both (see below).
- You can bundle up to three requests in a single continuation object and they will all be processed in parallel! (Note: if they need to be done in order, use “chain continuation” – see below).
Also, you should read the “Know thy limits” section further down as they apply to both single and chained continuation implementations.
Please, sir, may I have some more?
While replacing synchronous callouts with the continuation pattern will solve a lot of the world’s problems (the world of sync callouts hitting concurrency limits, that is), it doesn’t solve them all.
Take for example the ubiquitous case of making multiple requests in serial. Say you need to authenticate, request data, and submit changes in that order. In this case, we have orchestration of three individual requests that need to be made where the subsequent requests are dependent on the results of the previous.
Good news! We support this and it is called “continuation chaining”:
Chain continuation: another optimized approach
This example describes how to chain three sets of synchronous service calls together and includes one set where three are executed in parallel.
 Some of the key differences between this example versus the previous, Single continuation example are:
Some of the key differences between this example versus the previous, Single continuation example are:
- The aggregate wait time across all three continuation batches must not exceed 180 seconds.
- Tracking the response label, a unique identifier, is crucial to retrieving the response object for a particular callout from the Continuation object.
- Instead of returning ‘null’ or a new PageReference from the response handler method, you return the next Continuation object.
- Messages added to the page are displayed from the last response handler method only. To avoid this, the messages are stored on the controller.
- The ApexPages.message object is not serializable. The type and value, however, are serializable. To maintain simplicity, a separate class was created to store type and message in a list.
Chain Continuation Visualforce page code
Chain continuation controller code
Key takeaways for the chain callout example:
- You get up to three requests per Continuation and up to three Continuations can be chained.
- All requests in a Continuation are made in parallel but the response handler is called only when all requests in the Continuation are completed.
- Be sure to track response labels carefully to ensure retrieval of the intended response objects.
Know thy limits..
While Continuation gives you a lot more rope with which to play, it’s not a blank check. Try to keep the following details in mind:

- As of the Summer 2016 release, Named Credentials work with Continuations (see the Named Credential Sample below for some sample code). Now that Continuations support Named Credentials, you can eliminate one step in the chain, and reducing aggregate wait time.
- For previous releases, or cases where Named Credentials cannot be leveraged, continue considering alternative patterns. For example, you can use the Chained continuation example just covered, which uses Custom Settings and Platform Cache to orchestrate authentication, fetch, and push across several callouts.
- You get up to sixty (120) seconds per callout in a Continuation regardless of the number of callouts in that Continuation; i.e., each individual callout in the continuation can take up to 120 seconds to respond. The upside, of course, is that they are run in parallel which reduces the aggregate response time.
- You can have up to three (3) Continuations in a chain. With each Continuation allowing for three parallel callouts. This allows for the potential total of 360 seconds in running time across all three Continuations. Note that VF pages using Continuation are not subject to the 120 second page timeout.
For example, a Continuation with three callouts where one takes 5 seconds, the second takes 3 seconds and the third taking 10 seconds would take 18 seconds if executed serially. However, Continuation callouts run in parallel, so the running time will be that of the longest running callout, or 10 seconds, leaving 50 seconds remaining of the Continuation timeout limit.
You forgot X, Y or Z!
By now, an astute reader such as yourself is asking “What about REST or SOAP services written in Apex that make callouts?” or “What if I need more than three chains or three requests in a chain?”.
Admittedly, continuation doesn’t handle every case and is currently limited to making calls from Visualforce page and Visualforce Remote controllers. For Continuation from SOAP/REST Apex services, there is an internal discussion about support but no current plans. And, while increasing the limits is possible in a future release, it would require making a strong case to the Development team to raise them for your org.
Fortunately, there are a few remaining suggestions to help with these and other cases:
Bundling
Making many (5+) service requests from any type of synchronous request/response framework is going to involve perceptible delays. Consider that each request has at least 100-150ms in round trip time (SSL,Ping,etc.) before adding in server runtime which is anywhere from 30-3000ms. When invoked in serial it’s impractical to expect aggregate response times less than 5 seconds and, when in the wild, they can take 10 seconds or more.
One suggestion is to find a way to bundle these requests into a single request. The Mediator pattern, from the Enterprise Integration Patterns repertoire, could take a combined payload and fan out the requests in parallel and return an aggregate response payload.
You could easily build one on Heroku but this is beyond the scope of this doc. Stay tuned!
Circuit Breakers
This is one of my favorite system integration pattern fail-safes. It’s a more intelligent version of “Fail Fast” (see below), but, essentially, circuit breakers are a software version of the same thing you have in your home. However, instead of tripping when you stick a fork in an outlet (do not try this!), it trips when certain runtime criteria are met.
One way to implement circuit breakers is similar to what the Salesforce App Cloud does with the Apex limiters: use the Platform Cache feature to keep track of callouts to certain remote systems or endpoints. And, when you start seeing N failures or timeouts, you block/queue/whatever subsequent calls to that endpoint and stop failure from cascading.
Similar to “Fail Fast”, one of the key elements of this defense pattern is communicating to end users and thinking through your use case. Make sure the handling is graceful, and, where possible, resume work as seamlessly as possible.
Not to be a tease, but building circuit breakers into your Salesforce application is out of scope for this doc. Stay tuned.
When all else fails.. FAIL FAST!
Last but not least, consider that when you allow dynamic factors (such as internet latency) to impact your application’s stability, you are allowing for some amount of inevitable downtime. Do not, then, be surprised (or upset!) when the inevitable happens.
It was planned, right? No? Read on.
There’s a mantra in integrated systems design which applies directly to this problem: take the problem head on and build it into the system’s behavior. We know it’s going to fail/slow down/hiccup/barf, it’s just a matter of “when”, so Fail Fast.
The difference between taking this approach and leaving the problem to someone else (i.e. the Apex limiters) is that, when it does hit the fan, you can do it with style and panache that may make your users happy instead of leaving them reaching for their pitchforks.
So, in Apex, whenever you make a callout, take the extra effort to code in some limits of your own and tie it into the application experience. It’s more work but it pays off:
Fail Fast example
Here we’re not doing anything fancy, really. We just make sure the request will never go longer than 5 seconds.
 When the timeout is hit, you catch the exception and notify the users that the remote server is not responding within your tight SLA’s and do one of many things:
When the timeout is hit, you catch the exception and notify the users that the remote server is not responding within your tight SLA’s and do one of many things:
- Give them control of the page after a few seconds (So they don’t spam the reload button!)
- Retry programmatically (with automated decay)
- Queue and poll
- etc.
Granted, some of these options can be complex to implement, but the key benefit is that you can explain to the users what the problem is (the Apex concurrency limit error is vague and indiscriminate!). Communicate what their next course of action should be and do it in a way that is integrated with your applications’ look-and-feel.
Fail Fast example Visualforce page code
Fail Fast example controller code
The key difference between this example and the synchronous pattern is that we set the timeout to something ‘tight’, like 5 seconds. Then, catch the CalloutException, confirm it matches the “Read timed out” value, and add a message to the page. Review of your use case should readily offer up one or more behaviors that occur when you start hitting timeouts. All of which should certainly be preferable to hitting the Apex concurrency limit.
And Now, Named Credentials, Too!
As of the Summer 2016 release, Continuations support Named Credentials. With Named Credentials, the platform takes steps for authentication and caching of auth tokens, etc. This effectively eliminates the need to use one chain in a Chained Continuation to auth and store the token in the cache like we did in the example above.
While configuring a Named Credential is beyond the scope of this post, the code changes to the Continuation examples are relatively straightforward. Named Credentials are invoked by prefixing the endpoint URL in the format “callout:<NamedCredential>”. In this case, our Named Credential is called “NA16” and would thusly be invoked via the prefix “callout:NA16”.
The following shows the how you can change the Chain Continuation example presented above to leverage the NA16 Named Credential:
ChainContinuationCalloutPageController
Static Declarations
Before:
After:
Submit Method
Before:
After:
Process Auth Response Method
Removed.
That’s it. This now frees the Chain Continuation for one more chain of up to three parallel service calls! Very useful!
About the Author
Scott Mikolaitis is a Technical Enablement Architect within the Technical Enablement team of the Salesforce Customer-Centric Engineering group. He has 18 years of industry experience with focus on system architecture and software integration to curate and evangelize best practices. The team’s mission is to help customers understand how to implement technically sound Salesforce solutions. Check out all of the resources that this team maintains on the Architect Core Resources page of Developer Force.
Related Resources
- Designing Force.com Applications That Avoid Hitting Concurrent Request Limits
- Using Request Apex
- Apex Continuations
- Put Your Code To Sleep with Salesforce Asynchronous Callouts
- Architect Core Resources
- Secure Coding Storing Secrets
- Continuation Class – Force.com Apex Developer’s Guide
- Making an Asynchronous Callout from an Imported WSDL
- Remote Process Invocation – Continuations