

Successfully moving changes between environments doesn’t happen by accident. It takes time and planning and perhaps more than one attempt at deployment. Deployments don’t always succeed, and one of the most frustrating issues can be unravelling what the message(s) returned by the Metadata API really mean when it comes to deployment.
I want to take a look at how you can find information about issues with your deployments, how to identify what failure messages are actually telling you, walk through some common deployment errors and share some useful patterns for structuring your deployments.
Where do failures show up?
The best place to look for errors (and the quality of the messages you’ll find) depends on what mechanism you’re using to deploy your changes. In every Salesforce environment (think scratch org, sandbox, production) you can get an overview of that org’s deployment history under Setup > Deployment Status.
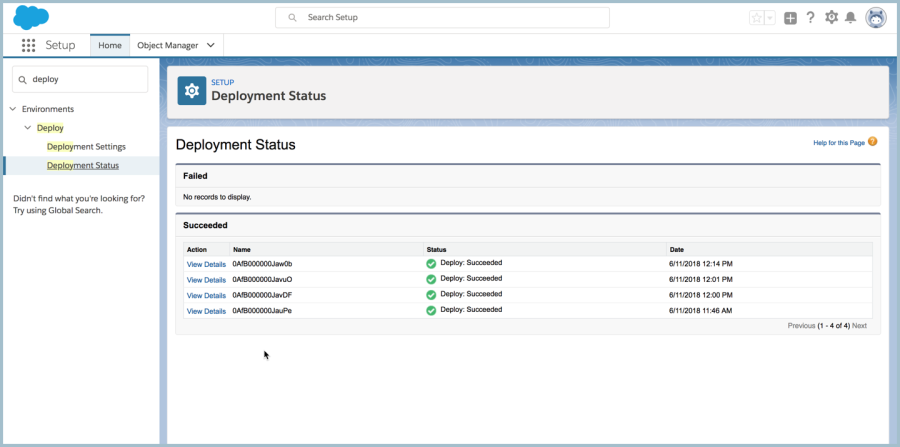
However, the amount of detail available under ‘View Details’ can be very limited, depending on your deployment method.
If you’re using Change Sets to deploy your changes, you get a bit more detail here than other kinds of deployments get. But this will also be the only place you can find error messages related to your change set deployment. (Clicking Setup > Inbound Change Sets > Whatever Change Set Name > View Details takes you to the same data/screen as clicking Deployment Status > View Details.)
If you’re deploying directly with the Metadata API, you’ll see almost no meaningful details in this part of Setup. Depending on your IDE, you may find details about your deployments in your IDE logs, or your IDE may have a dedicated UI for working with your deployments where you can see some error messages.
Using the Salesforce CLI and VS Code, you can get information about your deployment by adding the -w and --json parameters when you attempt sfdx force:mdapi:deploy.

This format can be difficult to parse when dealing with a long series of messages.
In my experience, the easiest place to view granular messages when working with Metadata API deployments is Workbench. The results of an identical deployment to the one above, handled via Workbench, looks like this:
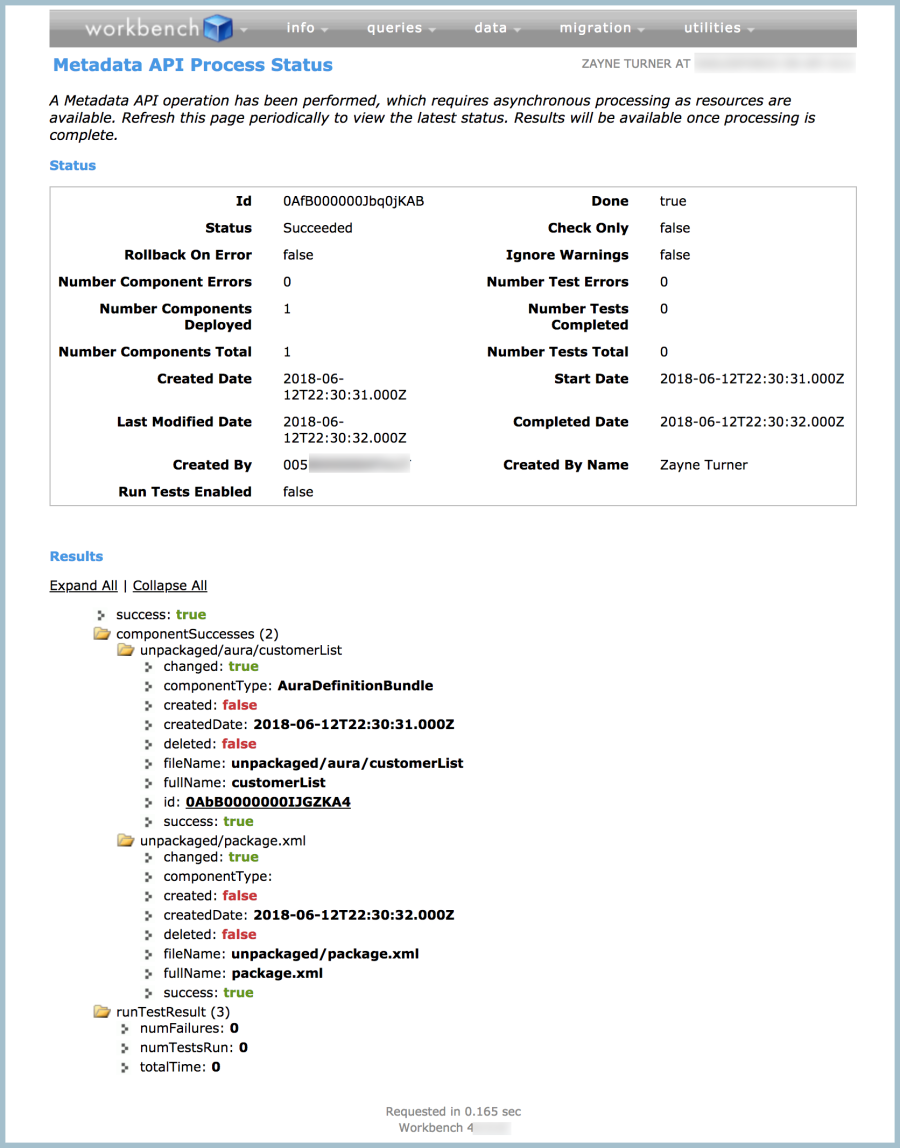
Here, we’re seeing the same details as in the output of the Salesforce CLI. But it’s easier to understand the details and easier to track the deployment status and details for every item in my deployment. These details are crucial when you’re unravelling issues with a deployment.
Understanding Metadata API failure messages
The key to understanding what the Metadata API can tell you about your deployments is learning to distinguish what’s actually meaningful information and what’s just noise.
The stream of information returned by the Metadata API during a deployment is really that: a stream. It’s a feed of everything that’s happening during a deployment attempt. A giant list of errors doesn’t necessarily translate into a giant list of issues that need to be corrected with your deployment.
If you see that you have errors in your deployment, you’ll have to determine the list of things that are actually wrong by yourself. The errors sent back by the Metadata API will help you do this.
To understand what actually happened during your deployment, you need to work backwards through the messages.
Let’s look at an example using the Easy Spaces sample app. I pulled together most of the metadata from the app into an unmanaged package, which I named ‘Test’. I used the Salesforce CLI to grab my ‘Test’ package (using sfdx force:mdapi:retrieve), and when I unzipped the retrieved metadata, this was the package.xml:
1<?xml version="1.0" encoding="UTF-8"?>
2<Package xmlns="http://soap.sforce.com/2006/04/metadata">
3 <fullName>Test</fullName>
4 <types>
5 <members>customerServices</members>
6 <members>customerServicesTest</members>
7 <members>marketServices</members>
8 <members>marketServicesTest</members>
9 <members>reservationManagerController</members>
10 <members>reservationManagerControllerTest</members>
11 <members>testDataFactory</members>
12 <name>ApexClass</name>
13 </types>
14 <types>
15 <members>AppPage_2column</members>
16 <members>contactPicklistPath</members>
17 <members>customerDetails</members>
18 <members>customerList</members>
19 <members>customerService</members>
20 <members>customerTile</members>
21 <members>defaultTokens</members>
22 <members>galleryTile</members>
23 <members>marketService</members>
24 <members>muteTiles</members>
25 <members>openRecordAction</members>
26 <members>pill</members>
27 <members>pillDeselect</members>
28 <members>pillSelect</members>
29 <members>pillTile</members>
30 <members>reservationHelper</members>
31 <members>reservationList</members>
32 <members>reservationPicklistPath</members>
33 <members>reservationTile</members>
34 <members>selectChange</members>
35 <members>selectObject</members>
36 <members>smartGallery</members>
37 <members>spaceDesigner</members>
38 <members>spacesGallery</members>
39 <name>AuraDefinitionBundle</name>
40 </types>
41 <types>
42 <members>Space_Management</members>
43 <name>CustomApplication</name>
44 </types>
45 <types>
46 <members>Contact.Reservation_Status__c</members>
47 <name>CustomField</name>
48 </types>
49 <types>
50 <members>Customer_Fields.Contact_Customer_Fields</members>
51 <members>Customer_Fields.Lead_Customer_Fields</members>
52 <name>CustomMetadata</name>
53 </types>
54 <types>
55 <members>Customer_Fields__mdt</members>
56 <members>Market__c</members>
57 <members>Reservation__c</members>
58 <members>Space__c</members>
59 <name>CustomObject</name>
60 </types>
61 <types>
62 <members>Contact_Record_Page</members>
63 <members>Market_Record_Page</members>
64 <members>Reservation_Manager</members>
65 <members>Reservation_Record_Page</members>
66 <members>Space_Management_UtilityBar</members>
67 <members>Spaces_Designer</members>
68 <name>FlexiPage</name>
69 </types>
70 <version>43.0</version>
71</Package>I then created a scratch org, set a password for the default user, and logged into Workbench using my scratch org credentials.
I then used Workbench to run a ‘check only’ deployment:
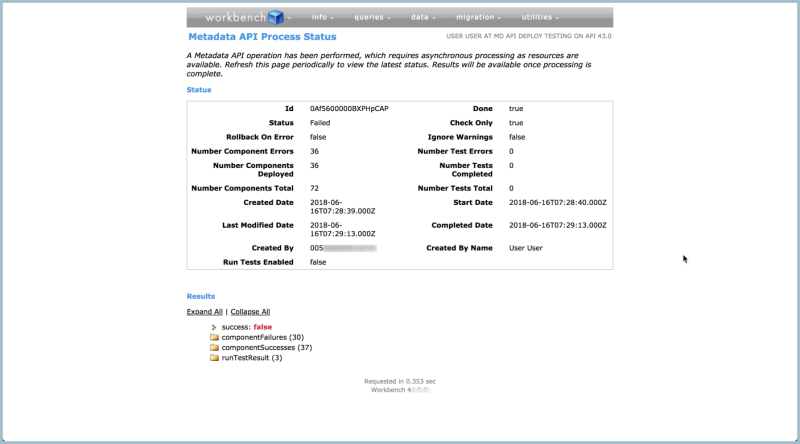
And as you can see, I ran into more than one or two errors:
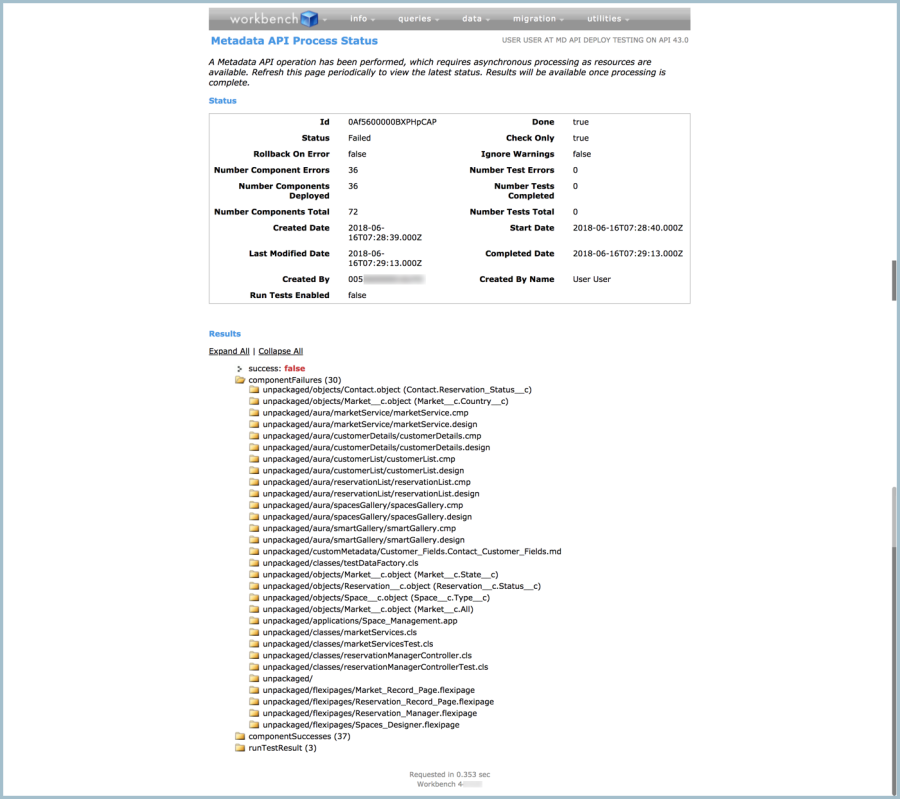
So how can you start to zero in on the really important error(s)? When you look at the list of issues, begin by:
- Looking at the metadata types involved (also referred to as the component or entity type: object, auraDefinitionBundle, class, flexipage, etc.)
- Prioritizing errors related to metadata types with fewer dependencies before more complex entities
If you’re not sure what kinds of metadata have fewer dependencies, look at the xml definition files for the metadata types you’re working with. (Or if you’re working with a Visualforce page, Apex class or Lightning bundle, look at the markup.) If a file references something else, that “something else” better be there.
Let’s look at an example, using the ‘Spaces_Designer.flexipage’, which was one of the pieces that failed to deploy in my package. Here’s the xml for that flexipage:
1<?xml version="1.0" encoding="UTF-8"?>
2<FlexiPage xmlns="http://soap.sforce.com/2006/04/metadata">
3 <flexiPageRegions>
4 <componentInstances>
5 <componentName>reservationList</componentName>
6 </componentInstances>
7 <name>leftColumn</name>
8 <type>Region</type>
9 </flexiPageRegions>
10 <flexiPageRegions>
11 <componentInstances>
12 <componentName>spaceDesigner</componentName>
13 </componentInstances>
14 <name>rightColumn</name>
15 <type>Region</type>
16 </flexiPageRegions>
17 <masterLabel>Spaces Designer</masterLabel>
18 <template>
19 <name>AppPage_2column</name>
20 </template>
21 <type>AppPage</type>
22</FlexiPage>This flexipage has 3 different dependencies: the reservationList component, the spaceDesigner component, and the AppPage_2column custom page template. If any of those pieces of metadata aren’t in my package, then this flexipage could cause some deployment problems.
Looking back at the list of errors, you can see that the reservationList component also had a problem with deploying. If we look at the component markup for the reservationList, here’s what you’ll find:
1<aura:component implements="flexipage:availableForAllPageTypes" controller="reservationManagerController" access="global">
2 <aura:attribute name="reservationList" type="Object[]"/>
3
4 <aura:handler name="init" value="{!this}" action="{!c.onInit}"/>
5
6 <div>
7 <span>Open Reservations</span>
8 <ul>
9 <aura:iteration items="{!v.reservationList}" var="res">
10 <li>
11 <c:reservationTile reservation="{!res}"/>
12 </li>
13 </aura:iteration>
14 </ul>
15
16 </div>
17</aura:component>Here we see more dependencies:
- Line 1: Dependency on the reservationManagerController Apex class.
- Line 11: Dependency on reservationTile, which is another Lightning component.
But before we go look at more component markup or Apex code, we need to go back to the keys I laid out before: prioritize errors related to simpler metadata types before more complex ones.
So we shouldn’t start our investigation with a flexipage, which is a piece of metadata with multiple dependencies.
In general, the root of all dependencies will be your data model. So if you’re seeing errors related to objects and fields, you should start there.
Let’s start with the errors related to objects:
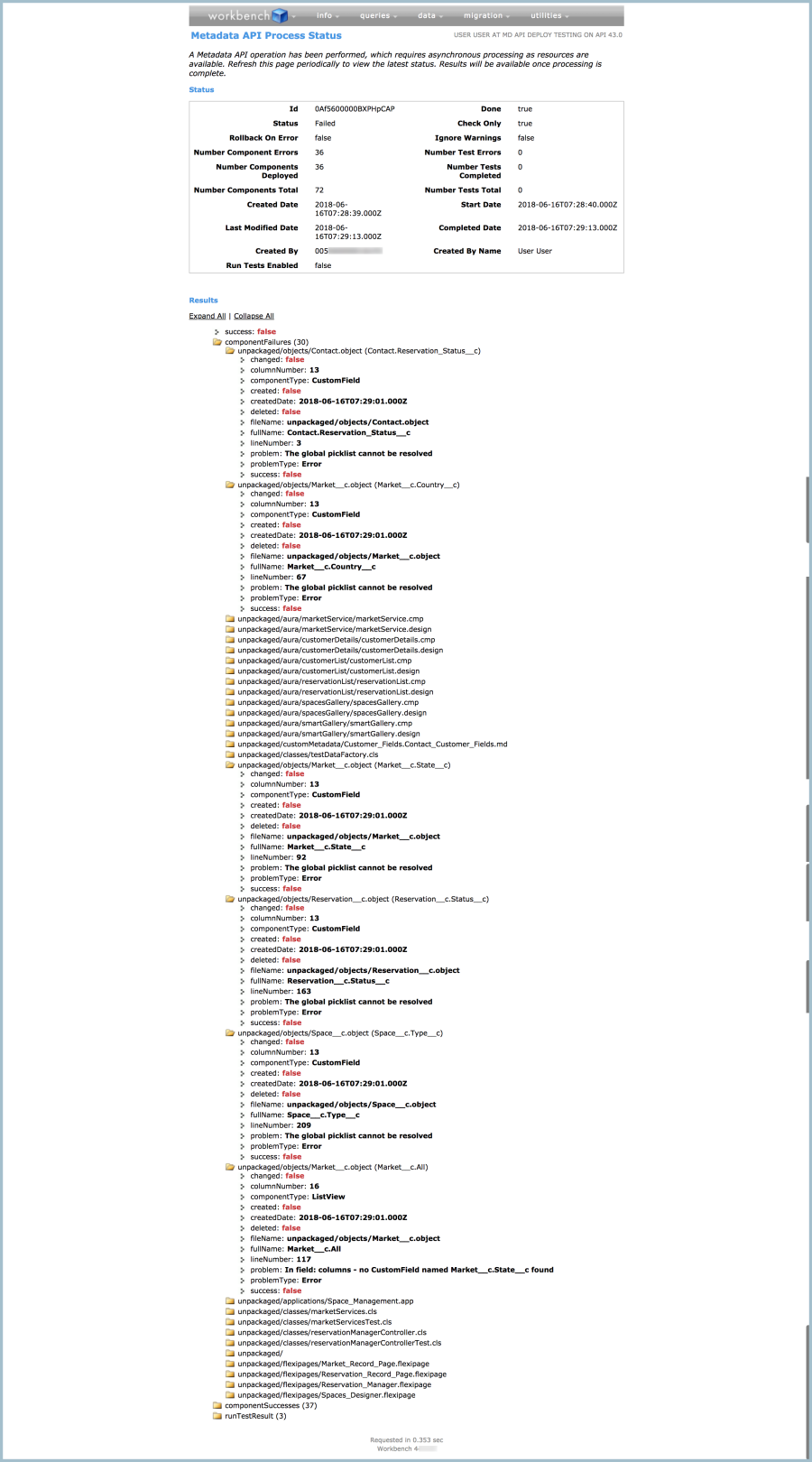
A common error is apparent: “The global picklist cannot be resolved.” Each field with that error, like the ‘Reservation_Status__c’ field on the Contact object, is based on a global picklist, and I didn’t put any ‘GlobalValueSet’ metadata (which is the metadata entity for global picklists) into my package.xml.
I can clearly see this error repeated in this view in Workbench. But if I were using another tool and reading error messages one-by-one, this discovery lets me know that any objects with global picklists in this deployment ran into the same trouble. I also know that any metadata in this deployment that is dependent on those objects and fields also had problems, and metadata dependent on that metadata also had problems, and so on. That is why I got a whole list of errors, and why you don’t want to start your troubleshooting with errors related to complex metadata types.
So when I added GlobalValueSets to my package and tried deploying again, everything was OK, right? Not quite:
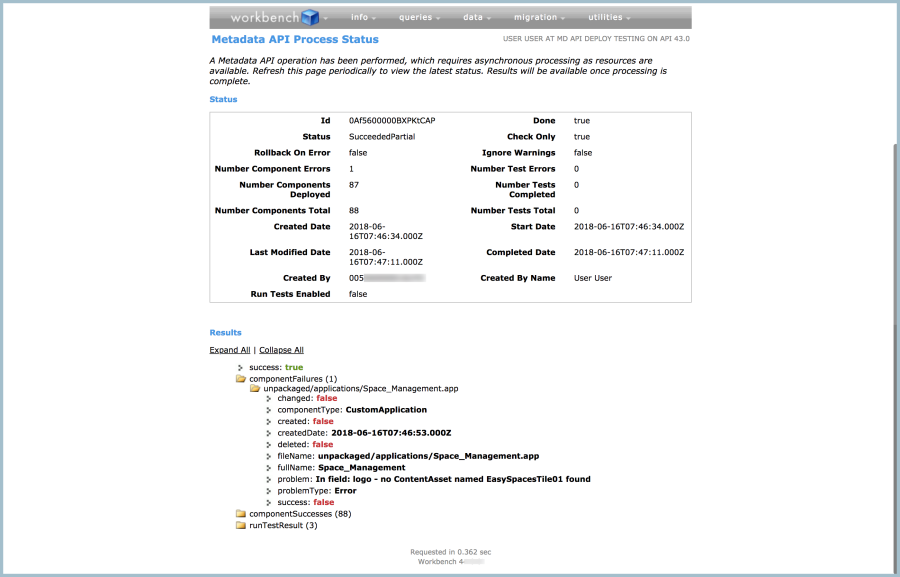
But at least this time, I only had ONE error and it was also pretty straightforward: I’d also forgotten to add in the ContentAsset file for my app. (The picture that appears as an app’s icon in the App Launcher.)
This is another reality to keep in mind: working with Metadata API deployment can be like peeling an onion made of Rubik’s cubes. Deployments are like puzzles and you sometimes can only reveal new pieces by going through some layers. But deployments are puzzles with logic — and that logic is based on dependencies.
How to think about structuring your deployments
When you give the platform a bundle of metadata to deploy, the platform will try to deploy your metadata in an order that respects dependencies within that bundle. But the larger the bundle you try to deploy and the more kinds of dependencies you put within a bundle, then you’re increasing the risk of running into a deployment that’s even more complicated to troubleshoot than my example above.
I generally prefer to split my deployments into smaller, staggered units. I find that it decreases the amount of time spent troubleshooting, makes complex deployments more reliable across environments, and increases a team’s ability to focus on important pre- and post-deployment steps.
So how can you start to figure out how to manage dependencies when you’re deploying?
- Pay attention to your data model. You can use schema builder, the Workbench REST explorer, and the SOAP API data model documentation to get a sense of your custom objects and the standard object data models.
- Get comfortable looking at the xml for more complex metadata types. As I said before, if a piece of metadata references something else in its xml, something else either needs to already be in place when it deploys, or it needs to be in the same deployment.
- When in doubt, look at the xml.
I’ll end by sharing the general framework I use to think about deployment dependencies, ordered from least dependent to most dependent. This list is not at all comprehensive of all the possible metadata types you may need to consider, and is just where I begin when sanity checking my deployment plans:
Objects → Fields (Global Value sets)→ Actions (Global actions & Object specific/quick actions, NOT based on Visualforce or Lightning component overrides) → Static resources → Classes → AuraDefinitionBundles → Tabs → Actions (Visualforce and Lightning component-based) → Page Layouts → Visualforce Pages → Flexipages → Apps → PermissionSets → Queues
Summary
Managing dependencies is key to creating successful deployments. Knowing how to find and understand messages returned by the Metadata API can help you more effectively manage oversights in your deployments, and help you learn how to improve the stability and quality of your app development lifecycle.
To learn more, check out and complete the Apex Metadata API module in Trailhead.