Artificial Intelligence is everywhere these days. In fact, by 2021, over 75 percent of commercial apps are predicted to use AI. This can be a daunting statistic if you’re new to the AI game, but there are some basics you can quickly learn to help you become an expert.
In this blog post, we’ll be talking about:
- What is computer vision and how does Einstein Vision relate
- Why a representative dataset matters when working with computer vision
- How to properly structure a representative dataset
- The importance of feedback loops and “Agile AI”
Computer vision and Einstein Vision
Before we get started, I’d like to make sure we all understand a few terms I’ll be using in this post: computer vision, Einstein Vision, and datasets.
Computer vision (as an interdisciplinary field of study) is concerned with the automatic extraction, analysis and understanding (by a machine) of useful information from a single image or a sequence of images.
Einstein Vision is Salesforce’s proprietary computer vision technology (also a part of Einstein Platform Services) which lets developers harness the power of computer vision to build custom AI-powered apps fast (even without a data science degree!). Einstein Vision is comprised specifically of two different types of Salesforce’s computer vision technology: Image Classification and Object Detection. I’ll use Image Classification in my screenshots and examples further down in the post, but the ideas discussed are relevant for all Einstein Vision and Einstein Language services. To learn more about the features and differences between Image Classification, Object Detection, and Einstein Language, please visit our developer docs.
Finally, an integral part of any computer vision solution is the underlying data that has been used to teach the artificial intelligence exactly what to extract, analyze, and understand. “Datasets” is the term we’ll use to refer to this underlying data. They will be the focus of the rest of this post.
Why a representative dataset matters
First, let’s talk a bit about how computer vision learns at a high level. For the most part, it doesn’t just “know” things — you have to teach it much like you would teach a toddler.
The analogy I like to use is “What is an apple?” Think about how you would teach that to a toddler. Would you say to the toddler, “Well, the apple is red and curved and it has a stem”? No, you would continually point out examples of what an apple looks like in the real world and reinforce the concept of “That is an apple, and this is an apple, and that is an apple.” The toddler would learn what an apple is over time by seeing real examples of it.
The most important part of this analogy is the concept of “real world” examples. When I work with people who are interested in computer vision, a common sentiment is that the images used to train the AI model must be perfect example images of the object in question. I think of such images as “sterile examples,” or pictures taken in a professional setting with a professional camera and lighting, etc. But needing sterile examples is a common misconception. It’s true that we do need high-quality images of the objects for the AI to learn, but what is equally (maybe even more) important is that the images also include true to life examples of what the AI might be expected to analyze in the future.
Let’s look at an example.

Let’s pretend that we used the above six images to train our computer vision model to tell us if a new image it is looking at is an apple or pear. In this example, all of the apples are red and all of the pears are green.
How would our computer vision model categorize an image of a green apple? Given that it has only ever seen red apples and green pears, it would likely categorize the image of a green apple as a pear. However, if we provided the model with a more representative dataset of the images you expect it to categorize, the model’s accuracy will improve dramatically.
How to properly structure a representative dataset

Look at the differences in the images we’ve used to train our second model. The apples are all different colors, have white and different colored backgrounds, are being held, and are among other objects in their images. The test photo is of a combination that our computer vision model has never seen before, but it has seen green apples and it has seen apples with green in the background. This is an example of what it means to have a representative dataset because it gives our computer vision model real world examples similar to what it will be asked to categorize in a production system.
This becomes EVEN MORE important when we think about how images might come into a computer vision model from, say, a field service technician or a customer in their home.
A field service technician might send an image in from somewhere like this:

The images could come from various types of cameras or phones. They could be blurry or lower quality, or they could include shadows or other shapes that your computer vision model has not been trained to understand.
The goal for training your model doesn’t necessarily need to account for every single type of situation in which an image might be submitted, but you should attempt to create a sampling of images that is as representative as possible. If the images being sent in could possibly be blurry, then include a portion of blurry images in your training sample. If the images being sent in could possibly come from lower quality cameras and be lower quality photos, then include some of those in your training sample too. Finally, if the images could be of objects that get dirty, oily, or in any way deteriorate from their mint condition, you guessed it — include examples of those as well.
To give your computer vision model the best chance of success, let it learn from the widest range of information and experience available. Taking this approach will give your model the best baseline possible as you continue to refine its learning, accuracy, and confidence over time.
Feedback loops and “Agile AI”
The refinement process is also an inherent part of any production computer vision model. In a custom solution using the Einstein Vision API, the model can be given positive or negative feedback from users as images are uploaded and AI predictions are given. Feedback loop processes can be used to get up and running with computer vision models quickly instead of trying to think of every possible image and combination you’d need (i.e. boil the ocean approach) before you even implement your computer vision model.
“Agile AI,” as I’ve come to call it, would be the process of starting with the images you have on hand to train your model, allowing your users to submit images (whether those are images the model has been trained to see or completely new types of images [maybe oranges, to use our apples and pears example]), giving feedback of those images against the real-time predictions, and then having the AI continually learn from the feedback and become more confident.
To do this, developers can build a looped process using the Feedback API to add mislabelled images to the dataset and then eventually retrain the model. This looped process, or “Agile AI,” is how you can get up and running with computer vision today.
Let’s review a potential Agile AI process by starting with Image 1 below.
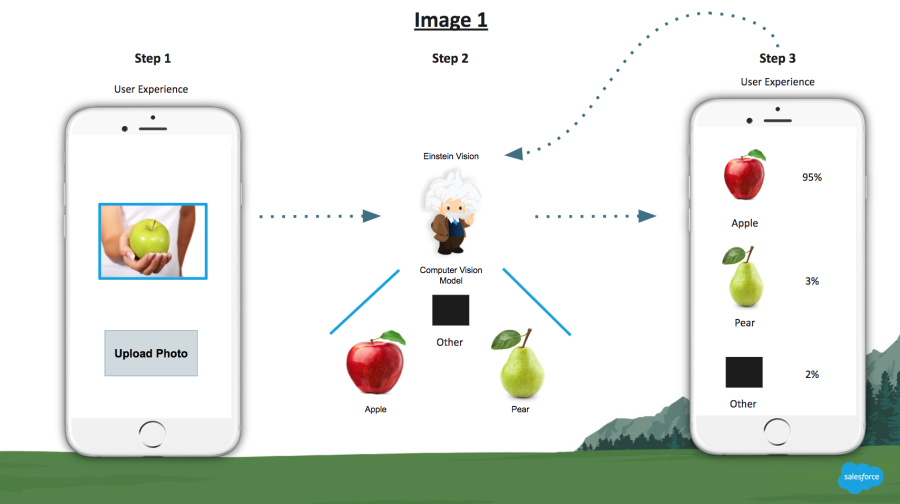
Follow the trail of Steps 1, 2, and 3. A user takes a picture of an apple and that image is sent to Einstein Vision (specifically, Image Classification). Einstein Vision has been trained to recognize apples and pears and sends the prediction back to the user’s mobile device.
Within our custom solution using the Einstein API, the user can see what Einstein Vision thinks the image is and the confidence score for each prediction. The user can also tap to confirm the correct image which sends the feedback to Einstein for confirmation (either automatically or via a review process to ensure the integrity of the model). This creates a feedback loop where Einstein’s intelligence is constantly being expanded and reinforced by its users.
But what about if the user takes a picture of something other than what you taught the model? What if a user submits a type of image that Einstein does not know how to classify?
Let’s look at Image 2 below.
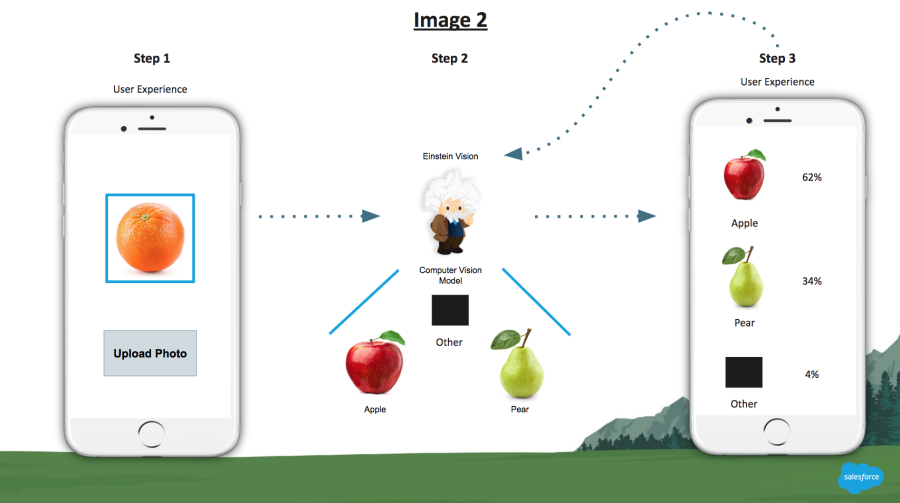
Einstein Vision provides data for you to include a “negative” class in your model. A negative class is basically an “Other” bucket. Images classified as “Other” can be manually reviewed at regular intervals to determine if a new class/label/bucket should be added to the model. Human review of computer vision predictions is similar to any quality assurance or regression testing process for any modern IT implementation.
In this example, the team can create the appropriate label(s) as necessary for Einstein to assign to oranges in the future, as seen in Image 3 below.
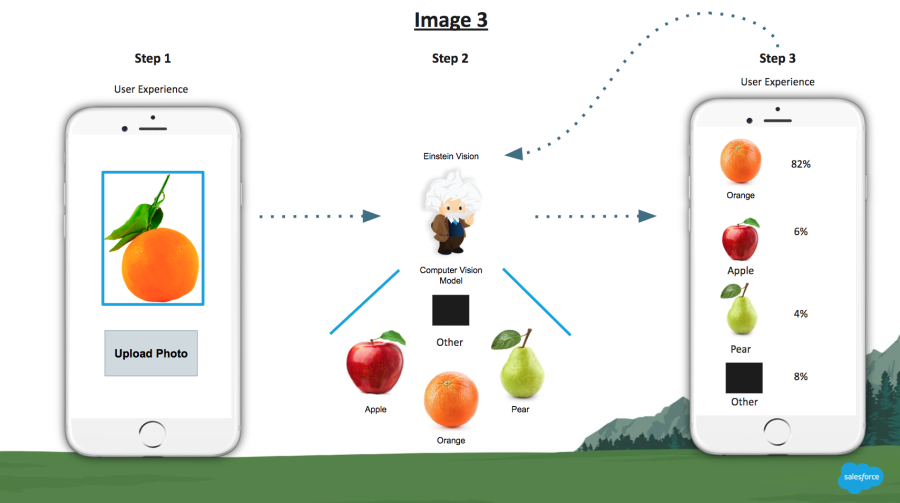
As Einstein is given more images of oranges, the confidence in the prediction of an orange image will continue to rise. As confidence in the system grows, the amount of human intervention necessary lessens.
Now that you have learned about representative datasets, feedback loops, and “Agile AI,” you are in a great position to create your own production-ready deep learning computer vision models using Einstein Vision. What’s also great is that what you just learned also applies to Einstein Language!
To continue learning more about what Salesforce is doing with computer vision and natural language processing, please visit Einstein.ai and review our press release for how Salesforce is combining Einstein Vision with Field Service.
Learn with Trailhead
- Project: Build a Cat Rescue App that Recognizes Cat Breeds
- Trail: Get Smart with Salesforce Einstein
About the authors
Mike Salem works on the Emerging Technologies team, a group of Architects and Solution Engineers who are subject matter experts in cutting-edge areas of cloud computing (such as Artificial Intelligence, Machine Learning, Cognitive Image Recognition/Computer Vision, Big Data, and Blockchain) on the Salesforce Platform. Our team fuels the growth of new and emerging technologies at Salesforce through consultative pre-sales engagements with prospects and customers across North America. We help showcase the world’s most innovative and industry-changing new products, such as Einstein Platform Services.
We help our customers CIOs, CTOs, and other Senior Technology Leaders understand where cutting-edge and future technologies fit into their strategic roadmap and assist in co-building a plan to implement and get business value from them. We additionally help fuel the rapid growth of Salesforce clouds by providing thought leadership and internal enablement for other Solution Engineers across the world and align closely with our technology & product teams on strategically important and highly targeted customer engagements and PoCs.
Our team makes the “next big thing” at Salesforce. We are the cloud incubators.
You can reach him by visiting his LinkedIn page.
Zineb Laraki is the Senior Deep Learning Product Manager at Salesforce leading product growth and research for Salesforce’s computer vision and natural language processing products. You can follow her on Twitter @zlaraki or visit her on LinkedIn.