Migrating Salesforce data between sandboxes can be a daunting task; this is especially true if you have a complex data model. So how do you make migrating data from one Salesforce org to another org in a breeze? Here within Salesforce, with dozens of sandboxes shared among multiple teams, we were always running in challenges with keeping those sandboxes up to date with correct product data. Though many teams have started to use scratch orgs, we still need the setup data in scratch orgs. Moving data manually is frustrating, time-consuming, error-prone, and not an ideal approach.
My team wrote a Java-based tool using Salesforce SOAP APIs to migrate the data from one Salesforce org to another Salesforce org. The now open source Org to Org Data Migration Tool lets you migrate the data from one Salesforce org to another Salesforce org. This is a standalone tool that one can run from a local machine.
Sound interesting? Let’s get to it.
What it does
The data migration tool connects to a source org and a target org using WSC (Web Service Connector) and partner APIs. It selects the records from source org based on JSON object mapping (discussed in the following sections) and inserts/upserts into the target org.
Features
This tool provides the following features:
- Easy migration: The tool migrates data from one Salesforce org (prod, sandbox or scratch org) to another Salesforce org for complex parent-child, hierarchical, lookup relationships. The migration can be easily automated if you need to deploy data to multiple orgs. Only common fields data is migrated. Alternatively, you can run Metadata Compare Service to find any differences in metadata for an object in source and target orgs.
- Selective migration: You can migrate all or selected records. You select the data what you would like to migrate. The tool provides support for filtering the records and the ability to replace old values with null values.
- Avoid duplicates: The data migration tool supports external IDs. If you specify external ID in JSON mapping, then the tool will do upsert — no worries about duplicate records in the target org.
- Performance: The tool supports up to ten connections to speed up the migration. However, note that the tool currently doesn’t support enabling and disabling the triggers.
Design
The tool connects to the source org only to retrieve the records. During a particular run, your source org is the source of truth and data in that org shouldn’t be changed. The tool never updates anything in the source org — it does insert/update/upsert or delete in the target org only.
High level architecture:

In addition to data migration, the tool provides a few other services.
- The Metadata Compare Service: Lets you compare the metadata for an object between source and target orgs.
- The Mapping Generator Service: This service generates the JSON object relationship mapping. You may want to edit the mappings, specifically the lookup keys. All fields are mapped unless they are excluded; you also should make sure to review and edit the JSON object relationship structure to ensure:
- Correct lookups reference.
- Correct parents reference.
- Any other references, like owner etc.
- The Validator Service: Once the data has been migrated, you can use this service to compare the count of records in source and target orgs.
Data structure
At the heart of the tool is one SforceObjectPair pair class. An instance of this class holds the references to source and target records. A pairing is established between source and target records for parent-child object relationships. For example, if Approval_Process__c is parent object and Approval_Step__c is child object, then with that structure (below diagram) in place, it becomes easy to replicate it for any number of related objects. Child object Approval_Step__c can in turn be parent of another child object and above structure will still preserve that relationship too.

Objects mapping using JSON
Let’s consider the below object relationship between three objects. Account and Asset are parent-child objects, Asset has a lookup to Product object. (Note: While our example utilizes standard objects the tool works equally well with custom objects.)
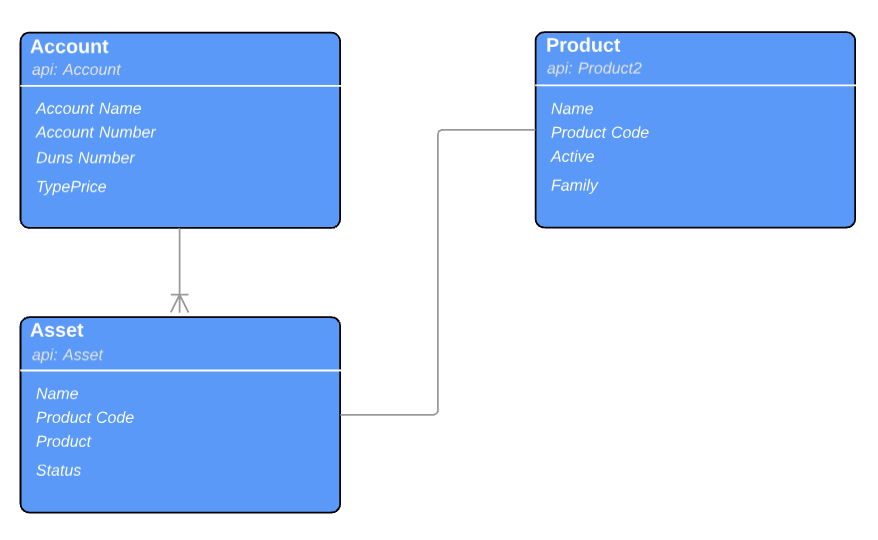
The JSON object mapping for above related objects will look like this:
Description of object JSON mapping

Security
The data migrator tool doesn’t store your password or logs it. All the data is kept in memory only. The data communication is between your machine and Salesforce using Salesforce apis.
The tool uses standard Salesforce SOAP APIs, which enforces CRUD/FLS restrictions. The source org user should have read access to objects/fields in the source org. The target org user should have proper CRUD and FLS in the target org. In the absence of CRUD/FLS, the migration will fail.
Usage
1. Input your source and target orgs credentials in build.properties file. As a best security practice, never store your username and passwords in source repositories.
2. Map and relate your objects and fields in a JSON.
You can filter records, avoid certain records from migration etc. using the JSON mappings. By default, each field from the source org object is mapped to a target org object. You can exclude certain fields.
A lookup record can be identified using more than one field (in the form of an array keys). Use “keys” array to uniquely identify the lookup record. More details on JSON mapping can be found under GitHub wiki page.
3. Run using any of existing main classes provided or create your own class to trigger the migration.
4. Alternatively, create your own main class to trigger the migration.
Additionally, the Github wiki has more details around how you can compare the metadata/data in two orgs, create sample JSON object mappings, etc.
Best practices
When migrating data for — let’s say — 100 objects, it can be challenging to manage the number of JSON mappings. As a best practice, try to group related set of objects in one JSON mapping. More details on JSON mapping can be found under the GitHub wiki page. To speed up execution, you can configure the number of threads in build.properties. (Note that the maximum value is 10)
Limitations
This tool holds the data in memory and no other intermediate storage is used. Since the data is stored in memory only, there is a limit of how much data you can migrate in a single run. On a machine with 32GB RAM, we have tested the migration of 1 million records in a single run.
Future
We have been adding more features in this migrator tool. Here’s what you can expect in a future release:
- Currently, the tool supports migration of data from one org to another org. We are working on an option where you can download the data from a source org to JSON data files and then use JSON data files as input to migrate data to your target org.
- Data masking
- A Heroku-based version with UI, coming soon!
- Scheduling of migration
- Email support
In the absence of such a tool, developers were spending lots of time in setting up their development environments. Some teams have moved on to use scratch orgs, but we still need to setup each scratch org with setup products data. With this tool, we are able to load the orgs with setup data with ease. Internally, we have automated this process as part of our CI/CP pipeline which has resulted in huge productivity gain.
We would love to hear the feedback from you. I would encourage you to download this tool and give it a shot!
Please let us know how you may want to use this tool in your CI/CD pipeline or in day-to-day development activities. Feel free to reach out to me on Twitter at @anoop_76