Applications like CRM are always active; requests come from sales users, service users, APIs, report executions, and community users. All this access keeps the system busy and they are all business transactions, which means the data is critical and the database is a precious resource.
The usual CRM traffic patterns is not a concern; what would impact application scale are use cases where users repeatedly try to reference the same data to check if records are changed or if new data is available. These are users trying to get the latest lead or the most recent case. Developers, admins, and architects alike need to watch out for such use cases. Let’s explore why this is important.
Data, use cases, and impact
Impact on the health of an application comes from these types of users, use cases, and data:
- Thousands of sales or service agents wanting to retrieve the latest lead or case.
- The type of request polling, refreshing or reloading of pages resulting in millions of requests in a short amount of time.
- Data is dynamic, but between changes or new data, the database is queried with high frequency to check for changes.

And the impact:
- Database CPU spikes up during these heavy usage times
- Reduced capacity for other applications
- Performance slows down for applications and pages
- Dashboard and report executions time out
- User frustration and complaints
All this leads to lack of scalability for the application and a potential slow down of business growth and increased costs.
There are few solutions available; however, business prefers solutions that are quick to implement and are cost-effective. Caching is potentially a solution in such situations.
Let’s talk about caching
Caching has been around for a while. It is typically used to speed up webpages and protect backend systems from too many user requests. These days some sort of cache is available in all layers of an application stack.

These caches help tremendously in scaling and performance, however it’s not sufficient for high impact use cases. We need a new caching layer which caches data for short periods and intercepts requests from client.
Intro to application layer caching
To address the impact use cases we need to introduce a new cache layer called application layer cache. This cache is connected to the application server and is accessible from the application code.

This new cache layer has good features. It’s an in-memory cache for fast retrievals and is implemented using Redis, an open source caching software. Data is stored in key value pairs. Data structures such as lists, sets and hash-sets can also be used along with primitive datatypes such as numbers and strings. Application layer cache also supports partitioning. At Salesforce, Lightning Platform Cache is the feature we provide to enable this application layer caching to applications on the platform.
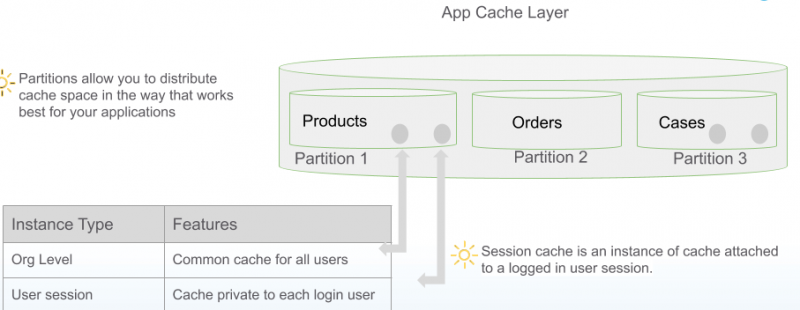
Using partitions and instances
Partitioning distributes data among nodes of the cache. This enables different partitions to be allocated to different applications or use cases. Each partition acts as a unique namespace for all keys.
A partition can have two types of cache: a common cache called an org cache which is accessible to all users of the application, and a session cache which stores data private a user and is attached to each logged in user session. The session cache is deleted at the end of a session.
On to solution
Now that we are familiar with cache and its internals, let’s see how it can be implemented for some high impact use cases.
Use case
Let’s take one use case and see how the cache can help. In this use case, agents take reservations from customers. The process involves giving offers based on loyalty programs. The offer is written to the database from an external API call. To check if an offer exists, the agent’s application constantly polls the server. There are thousands of agents doing the same and this causes the database CPU to spike.
We will refer to this use case throughout the rest of this document as the offers use case.
Implementing the app layer cache
The cache solution is as shown. Here session cache is used as each offer is unique to an agent based on reservation done by that agent.
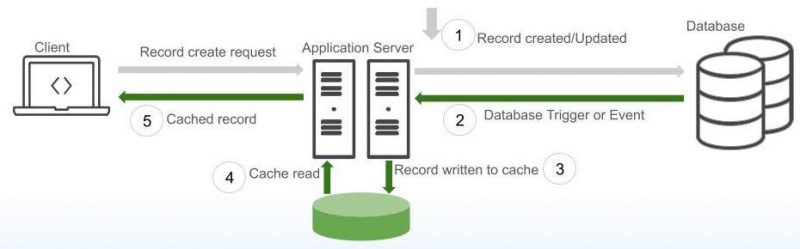
The business flow:
- An offer record is created via an API call.
- Database Trigger fires on save or update.
- Record is put into app layer cache (session cache) by trigger code.
- Record is retrieved by the client from session cache.
- Cached record is shown to the client.
This pattern is called write through pattern. In this pattern, the cache is written immediately when the data is created or updated in the database.
This implementation ensures the client requests never go to the database. All requests are served by the app layer cache, therefore protecting the database from spiking up.
Handling failures
In case of an exceptions in the transaction, the values in the cache and database can be different. To avoid this situation the following pattern can be used:
1. Use a reasonable TTL(time to live) on cached object. Cached objects clear when TTL expires.
2. Commit new values to database.
3. Post commit, clear the existing cached object. TTL will expire the object from cache.
4. Set cache to new object.
Here’s a code sample to read data from cache for offer use case:
Sample Apex Trigger code, adds data to cache.
Sample Apex class used by trigger to cache Offers.
Challenges
Race conditions
Not all data can be cached. Data that is shared among multiple users and getting constantly updated can lead to race conditions.
Knock knock! Who’s there? Race Condition! Race condition who? A race condition happens when multiple threads update the same record concurrently. Each of them write into the cache the data they have. The last update would be the “winner” however the winner might not have the latest update to the record and would result in the user getting the old data.
Work around
Race conditions can be worked around using a lazy load pattern. In this pattern, triggers are not employed to update the cache. Instead, one user is assigned to read data directly from the database, the data is then written to cache. Since data is visible to all users, the rest of the users read from the cache.
There is a slight overhead of that one user making frequent database requests. However, in situations where large volume of users concurrently use the system, allowing one user to access the database directly is less of an impact.
Cache miss
A cache miss is when the application expects data to be in the cache but can’t find it there. This causes the application to go to the database to get that data. Too many cache misses will reduce the effectiveness of the cache.
Cache miss happens because data in the cache is non-durable; cached data may be evicted when space is short. The user code should handle cache misses.
As shown in the code snippet, the cache is checked to see if a key exists. Or else, a fallback condition executes and retrieves data from the database and caches it for subsequent requests.
Platform Cache provides the CacheBuilder interface which helps with this use case. The link is provided below.
Org cache or session cache — which one to use?
The type of cache to use is determined by the type of data, visibility, changeability and the duration the data is expected to be in cache. Table below provides some guidance on selecting the type of cache to use.
Comparing session cache and org cache
| Org Cache | Session Cache |
|---|---|
| Ideal for data that is shared | Ideal for data that is private to a user |
| Data is visible to all users in an Org | Data is visible only in a user session |
| Writes or updates can be done any user or application | Writes or updates possible only in the user session |
| Data evicted when TTL expires or removed by application | Data evicted when session ends, expiration of TTL or removal by application |
| Invalidation can be done by a Trigger or Apex code | Invalidation possible only in the current session |
| Good for data that is long-lived | Good for data that is short-lived |
Examples of data types for org cache
- Case list for service agents
- Leads list for sales agents
- Report summary data
- Shared user profiles, metadata, org info
Examples of data types for session cache
- Accounts, contacts or user info private to the user
- Order history, order items, discount information
- Custom data with calculations in a transaction
- Financial data
Benefits
This table shows results monitoring App Layer cache implementation for the offers use case. Prior to the implementation of the cache the database was the target of requests from agents checking for new offers. This caused a high usage of database CPU. After implementation of the Platform cache, we see a good reduction as shown in the table.
Before implementation:
| Total Requests/Day | DB CPU Usage ** | DB CPU %*** | Database Queries/day * | Avg Response Time |
| 12 Million | 83 Hours | 7 ~ 8% | 12 Million | 30ms |
After App Layer cache implementation:
| Total Requests/Day | Improvement in DB CPU % | Offers served from Cache | Improvement in Response Time |
| 11.39 Million | 7~10% | 99% | 60% |
Based on this data we see the cache has a significant impact by reducing database usage to 1 minute from 83 hours and also benefiting the application performance by reducing the response time by 50 percent.
Some of the other benefits include:
| Area of impact | Benefits |
| Reduced number of Database nodes | Cost effective use of resources |
| Capacity released for critical operations | Scale businesses processes |
| Simplifies data access | Switching to cache access is easy |
| Better performance | Cache access is faster |
Conclusion
Designing for scale is critical as business grows. Scale in transaction-based apps on the Lightning Platform depends on critical resources like database. Data can be accessed millions of times before it changes.
Application layer caching is a solution to protect databases from such heavy load. Caching needs to be planned as there can be challenges.
References
- Redis Partitioning
- Application Layer Caching
- Trailhead Module: Platform Cache Basics
- Platform Cachebuilder
About the author
Anil Jacob is a Lead Software Engineer on the Frontier Scale team at Salesforce. He works on large and complex customer implementations and related scale challenges. His areas of interest are application scale, user experience, UX performance, and application development and business scale. Prior to Salesforce, he was with Intuit, Bea Weblogic, and Wells Fargo Bank.