

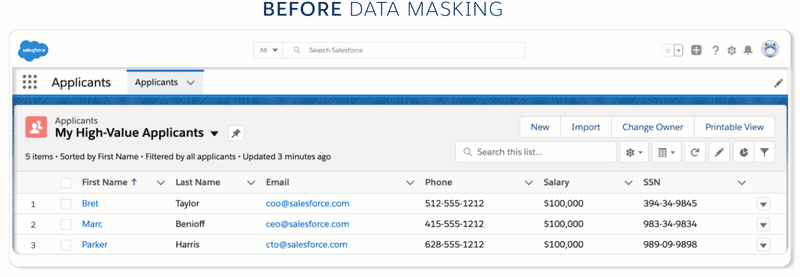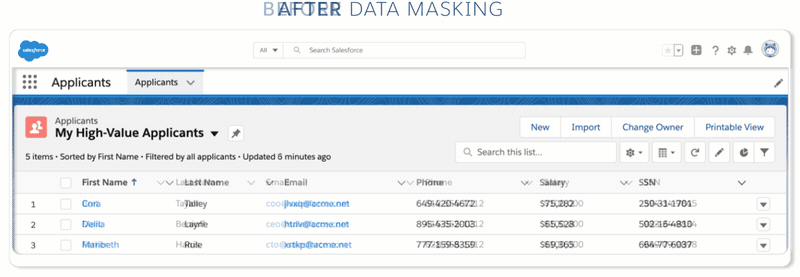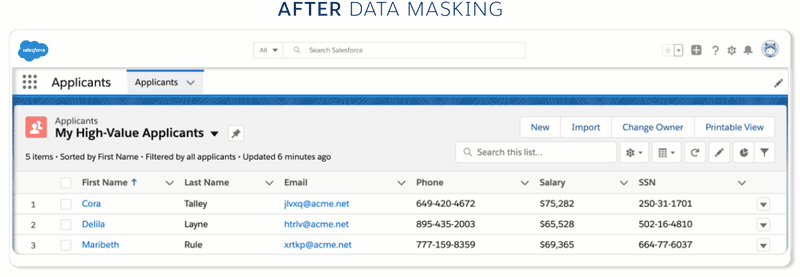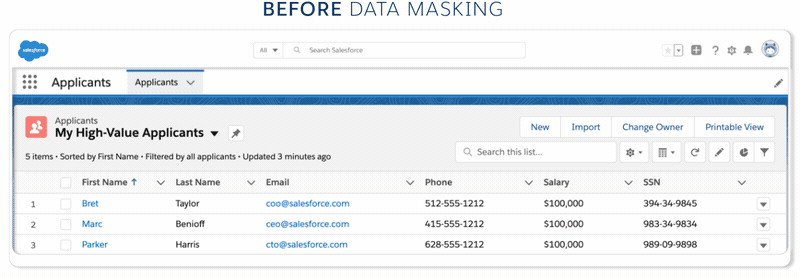
Salesforce Data Mask helps teams build and test applications while protecting regulated data, such as Personal Information (PI) and Personally Identifiable Information (PII). Full and partial Sandboxes mirror Production orgs enabling teams to build and test quickly. While access to Production is regulated and controlled, access to sandboxes tends to be flexible as many companies deploy employees and contractors to test applications. And that opens up potential risk when sensitive data in sandboxes is not protected.
With new compliance standards in place such as the European Union (EU) General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), companies are now held to higher standards of compliance and data governance regulation. Non-compliance and data breaches can result in loss of customer trust and and legal consequences.
Data mask secures sensitive sandbox data using a fully platform-native approach without taking data out of Salesforce. Data is masked through methods such as
- Anonymization — or making the data anonymous — scrambles a field’s contents into unreadable results. For example, Blake becomes gB1ff95-$.
- Pseudonymization converts a field into readable values unrelated to the original value. For example, Kelsey becomes Amber.
- Deletion converts a field into an empty data set.
What’s new in Data Mask?
Since the product launched in December, we have released several new features:
Pattern-Based Masking
Users now have another option to mask sensitive data based on a masking pattern of their choice. Pattern-based masking allows the user to create and generate a masking configuration that is a combination of random characters, letters and digits with a limit of up to 20 characters.
Server-side Pre-Processing
Server-side pre-processing of the masked data helps with scale issues seen by large organizations. This feature removes the need for users to keep a browser window open while running Data Mask, as well as increased speed allowing multiple objects to pre-process in parallel.
Email Uniqueness
Similar to an option for other fields, email fields can now be marked “Unique”. When selected, records for email fields can be masked with their own unique value, which reduces the likelihood of incurring duplicate rules.
Clone a Configuration
A user can create a new Data Mask configuration by cloning an existing configuration that has similar characteristics, thus not having to deal with creating a new configuration from scratch.
UI Updates for Configured Objects and Fields
Enhancements in UI now allow for objects and fields that have been selected for the configuration to group alphabetically at the top of their respective sections. This allows the user to quickly find and determine which objects and fields are included in their configuration. The new Quick Find search bar also gives the user the ability to easily search for the object or field they want to mask.
Abort and Re-Activate
If a user has the need to cancel an execution, they now have the ability to select “Abort” from the Configuration List View UI. Once aborted, Data Mask will reactivate any automations that had been deactivated, such as triggers, workflow rules and field history tracking that are turned off during data transformation. In cases where an execution did not complete on its own, the user can re-activate automations that were deactivated by selecting “Reactivate” from the Config List View UI.
What’s next?
We continue to innovate and look for ways to help customers manage data privacy and security requirements. This includes bringing more ways to customize data mask configurations such as accessibility in filtering for specific records a user wants to mask and giving the user the ability to build custom libraries that can be selected as a masking option. Finally, sandbox integration features will be added to enhance the sandbox creation process. With these new enhancements in place, Data Mask will further help organizations automate their processes and save them time and cost when building and customizing applications.
To learn more about Data Mask, view the Product Demo and visit the website here.




