
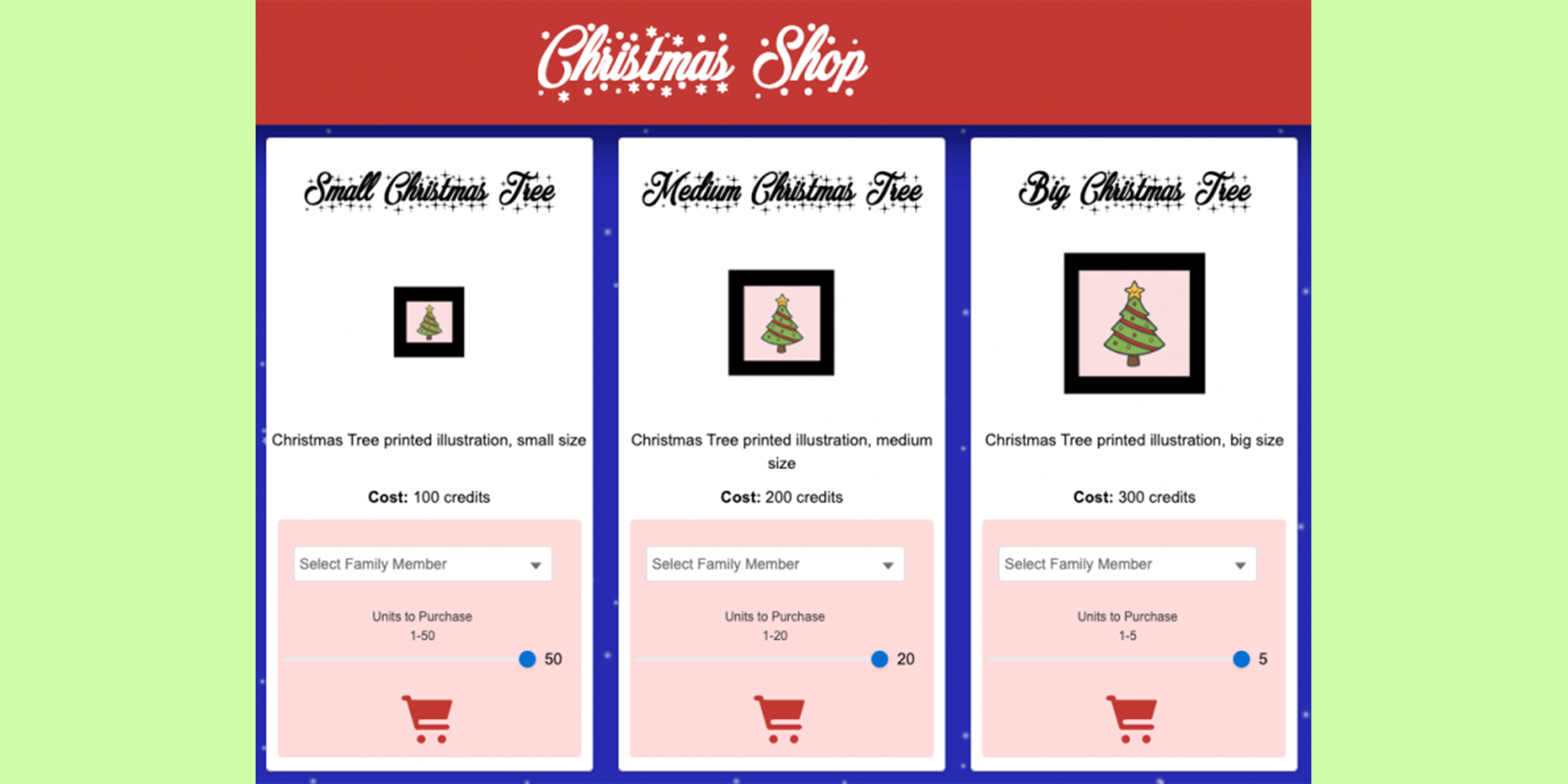
During the Christmas season, my family spends time together playing games. Last year, my little cousin decided to give credits to the winners. The credits could be spent buying printed Christmas illustrations, in a fictitious shop. I wanted to learn more about Node.js and architecture of modern web applications, so, this year, I decided to build our virtual Christmas shop on Heroku, using Node.js and Lightning Web Components Open Source (LWC OSS). In this blog post I will summarize what for me are the main points that a Salesforce developer should learn to make the move to Node.js + LWC OSS web app development.

Front-end vs back-end
One of my goals when tackling this personal project was to learn about effective architectures for modern web applications. That’s why I decided to completely separate the front-end and the back-end of the application. I created two different GitHub repos:
- Back-end app: it’s a Node.js app that stores family members, credits won, shop items, and each user’s purchased items in a PostgreSQL database. I chose Postgres for its simplicity of use within Heroku. The app exposes the APIs endpoints that I need to consume in the front-end app to be able to read and modify that data, using an Express server.
- Front-end app: contains the views for the app – the list of products available in the shop, and the products that each user has purchased. The UI is built with LWC OSS, using Lightning base components and the Salesforce Lightning Design System (SLDS). The front-end app consumes the backend-app endpoints when needed. The pages are served using another Express server. So, technically, I am using Node.js in this app too. This was something that confused me at the beginning. The front-end vs. back-end separation in my mind was like the Node.js vs LWC separation, but that’s not strictly true, as the pages in the front-end app need to be served somehow.

Note that having the front-end and back-end running on different apps requires that you configure Cross-Origin Resource Sharing (CORS) in the server and Content Security Policy (CSP) in the client so that you can call the APIs correctly.
Production vs development environment
In Salesforce, you just run apps on the core platform. However, external standalone apps, need to be executed in a runtime. For convenience, I decided to use Heroku. Heroku is Salesforce’s PaaS (Platform as a Service), a service that allows you to elastically run applications written in many different languages. It also has great features that allow you to control the resources that your app uses, as well as security, collaboration, and monitoring – plus a long list of other excellent features.
There are several methods for deploying an application on Heroku, but the most common one is to use git. You have to think about your Heroku app as a git repository, to which you push your app code. The common workflow is to create your code locally, and then push it to your Heroku app repo, so that Heroku can build it and run the app.
This is a pretty easy way to deploy, but as you can imagine, it’s not very effective for development, as uploading changes take a while. For that, it’s recommended to setup your environment to be able to develop locally.
To be able to run my app locally I needed a Postgres development database to read and store sample data from the back-end app. The approach I took was to install Postgres on my local machine, and created a script that initializes a database with sample data. You can follow other approaches, such as having different database add-ons on Heroku for development and production, or using Postgres from Docker.
Then, I needed a way to tell the apps which databases to use and URLs to query in the different environments. This is where Heroku config vars enters the game. A config var stores an app’s environment-specific configuration. Let’s take the database example. In our backend app, we need a config var that points to the Heroku database URL when the app runs in Heroku, and to the local database when it runs on our machine. You can define config vars in the Heroku dashboard or using the Heroku CLI. Additionally, when you attach a Postgres add-on, a DATABASE_URL config var gets created automatically, so our job was half done.
Then, you can assign a different value when the app runs in your local environment by different means, as using a local .env file. What I did, for simplicity, was to use a hard-coded value in the code as a fallback for when the variables are not set (which happens when you execute the app locally). In Node.js, you can easily access environment variables using process.env.VARIABLE_NAME.

One problem I faced was that I needed to access those variables in the LWC code, but that code runs in the browser, and process.env does not exist there. To overcome this, I created a custom webpack configuration that uses a plugin called EnvironmentPlugin. When webpack builds the LWC app, the plugin scans the code and replaces any process.env.VARIABLE_NAME occurrence with the value of the real environment variable. So, when you push to Heroku, the Heroku process environment variables are inserted into the LWC code.
Working with node packages
When working with Node.js, it’s very important that you understand how packages work.
The default package manager that comes with node is npm. With npm, you declare your app dependencies (development and production dependencies) in package.json. Production dependencies are those required to run your application. Development dependencies are required only for development, these include code formatters, linters, unit testing libraries, etc. When you execute npm install, both development and production dependencies are downloaded into your local machine, in the node_modules folder.
dependencies in package.json (backend-app)
1{
2 ...
3 "dependencies": {
4 "compression": "^1.7.4",
5 "cors": "^2.8.5",
6 "ejs": "^2.5.6",
7 "express": "^4.15.2",
8 "pg": "^8.2.0",
9 "helmet": "^4.2.0"
10 },
11 "devDependencies": {
12 "dotenv": "^8.2.0",
13 "nodemon": "^2.0.6",
14 "request": "^2.81.0",
15 "tape": "^4.7.0"
16 }
17 ...
18}If later on you want to use a new package, you can add it manually to package.json and run the install command again, or, you can install it running npm install -D whateverpackage (the optional -D flag needs to be specified for development dependencies). This command effectively downloads the last version of the package and adds it into package.json.
In package.json, most of the time, dependencies are specified with version ranges (semantic versioning). For instance, "nodemon": "^2.0.6" means the app works with versions 2.0.6 to 2.9.9. This means that different developers may install different versions of nodemon. That’s why there’s another file, package-lock.json, in which the exact version used by the developer is specified. If you run a first npm install and there’s a package-lock.json file, the downloaded dependencies will be those specified in the package-lock.json file. Equivalently, if you install a specific node package version, it will be updated in package-lock.json. It’s advisable to commit this file together with the rest of your code base.
Alternatively to npm, you can use yarn as a package manager. But it’s advisable to not mix the two.
Build vs Serve vs Watch
On the Salesforce Platform, we don’t have to worry about compilation. However, in other environments we do. For instance, LWC OSS apps need to be compiled. Some features in your LWC code (such as decorators or template directives) are converted into HTML and JavaScript that browsers are able to understand. Also, features not supported by older browsers are transpiled in compatibility mode, that is, written in a way that older browsers can understand.
That’s why in LWC OSS apps created with create-lwc-app you’ll find scripts defined in package.json that help you compile and serve your code using the lwc-services module:
build:development: compiles LWC, and moves resulting files to thedistfolder.build: compiles LWC code, and moves resulting files to thedistfolder. This time the files are minified and chunked for a better performance in production.serve: executes the script that’s the entry point for the app. The script creates an Express server that serves the files in thedistfolder.watch: it basically runsbuild:development && serve, and re-executes again any time that you change something in the code. This helps you see the changes instantly, without having to restart the app. This is also known as hot reloading.
scripts in package.json (frontend-app)
1{
2 ...
3 "scripts": {
4 "build": "lwc-services build -m production -w scripts/webpack.config.js",
5 "build:development": "lwc-services build -w scripts/webpack.config.js",
6 "lint": "eslint ./src/**/*.js",
7 "postinstall": "npm run prepare:slds",
8 "prepare:slds": "node scripts/copySldsAssets.js",
9 "prettier": "prettier --write \"**/*.{css,html,js,json,md,ts,yaml,yml}\"",
10 "prettier:verify": "prettier --list-different \"**/*.{css,html,js,json,md,ts,yaml,yml}\"",
11 "serve": "node index.js",
12 "test:unit": "lwc-services test:unit -w scripts/webpack.config.js",
13 "test:unit:coverage": "lwc-services test:unit --coverage -w scripts/webpack.config.js",
14 "test:unit:debug": "lwc-services test:unit --debug -w scripts/webpack.config.js",
15 "test:unit:watch": "lwc-services test:unit --watch -w scripts/webpack.config.js",
16 "watch": "lwc-services watch -w scripts/webpack.config.js"
17 }
18 ...
19}Build steps are not always needed, only when your sources require compilation, bundling and/or minification. For instance, when your project is using TypeScript, or when using LWC. For my Christmas back-end app, I was just serving static content, so I didn’t have to create scripts for compilation, just served the files that are part of the project. For watch mode, I learned that there’s a popular node library called nodemon, that did the trick – so I just had to install it as a development dependency.
Separation of concerns
At the time of creating the code for the apps, I started with a single file that did everything: it was the entry point setting up the Express server, the module performing the connection to the database and querying it (in the back-end app), the module requesting data to the back-end app endpoints (in the front-end app), etc…
Then I realised how the code could easily become unmanageable and I decided to apply some separation of concerns. I did some research, and the truth is I didn’t find “the definitive pattern”. But I got some ideas from some reference apps I looked into, and this is what I came up with:
- Backend: I divided the code into 1) the entry point for the app, that sets up the express server, 2) a file where I route the incoming endpoint requests to the different business logic and 3) a file to manage the communication with the database. Ideally, I should have created a service layer between the router and the database, but because of the app’s simplicity I decided to leave it as it is.
- Frontend: I divided the code inyo 1) the entry point that boots the server and routes the request to the app container, 2) the single page app container, in which we build the UI with LWC and 3) an API service file, to perform requests to the back-end app.
I’m sure many node developers know better ways of structuring the code, but my takeaway from this section is: make sure to apply separation of concerns patterns to your app if you want it to be manageable and scalable!
Using Lightning base components
As I was going to use LWC for the UI, I wanted to use our library of base components. Lightning base components were open sourced last year. Today, it’s even easier, as there is a lightning-base-components npm module that you can install in your apps simply running npm install lightning-base-components.
Take a look at this blog post for more details on how to use them.
Learn more
For me, it’s been a great learning experience to give it a try and build this app. Getting hands-on definitely helps with learning a technology, and why not do it with some added fun?
My recommendation if you want to get started with Node.js is to first consolidate your modern JavaScript knowledge, as you’ll see JavaScript modern language features everywhere. You can tackle this Trailhead trail and even give the JavaScript Developer I certification a try.
If you want to learn more about LWC OSS, make sure to complete this other Trailhead trail. And finally, if you want to see a more complex sample app in action, check out our eCars sample app.
Merry Christmas and happy coding!
About the author
Alba Rivas works as a Lead Developer Evangelist at Salesforce. She focuses on Lightning Web Components and Lightning adoption strategy. You can follow her on Twitter @AlbaSFDC.





