

Welcome to the first installment of an illustrated mini-series on database systems design. In this post, we take a look at Redis — what it is, when it comes in handy, and how to use basic Redis commands. The commands are environment-agnostic, so in our example, we’ll be running them via a Redis CLI provided by Heroku Data for Redis, a preconfigured add-on that enables developers to quickly stand up a Redis instance and focus on working with data safely and effectively.
What is Redis?
Redis is, as the official documentation puts it, “an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine.” That’s quite a mouthful! Let’s further explore what this means by discussing when Redis might be useful, why it can be an effective tool, and how it works behind the scenes.
When would you use Redis?
Imagine for a moment that you’re an engineer working on a hypothetical app called Novel, a social media site for writers. You already know to stash content that is static and unlikely to change often, like CSS styles and the user’s profile picture, in their browser cache.

What about stuff that’s a bit more dynamic, like the most popular posts of the day? The list of top posts is likely to change relatively often, maybe once an hour, but not so often that it’s not worth storing … somewhere. But where?
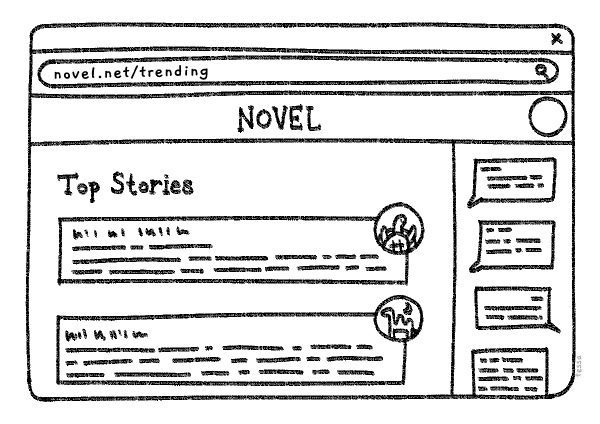
Why is Redis fast?
We could store the top stories in a traditionally-structured relational database. Database tables are useful for reliably storing and sorting large amounts of big chunks of data. But it can also take time to locate and retrieve data from the hard drives that store them long-term. RAM, on the other hand, is much faster. It’s designed to store and retrieve temporary data at a consistently fast speed no matter where “in memory” it’s physically located.

RAM is also where Redis stores data. In other words, the data is stored “in memory.” This is what makes Redis an optimal place to cache temporary, dynamic data that will be fetched and updated by multiple users, and its non-relational design is suitable for many use cases where speed of access is prioritized more highly than links between tables.

How does it work?
Redis stores data in a structure similar to a JSON object — in a giant blob of key-value pairs. This paradigm is reflected in its name, which is actually an abbreviation of Remote Dictionary Server.

We can set the amount of time a specific key-value pair should persist in memory (three days? forever?) via its time-to-live property, and know the data we’ve stored will be updated in a relatively consistent order using a Least Recently Used (LRU) eviction strategy. This means that when the Redis store is full, new data will replace the chunk that’s gone the longest without being accessed.


We can also rest assured that all Redis updates are atomic, meaning that a set of updates within a transaction will either completely succeed or fail, rather than get stuck in a partially updated state.


And if anything goes wrong, we can replace our main Redis store with our backup, thanks to Redis’ async replication and automatic failover features.
Other nice features Redis includes out of the box are support for pub/sub (scalable client-server communication and distributed messaging), and Lua scripting (Lua is a fast, lightweight language with a small and simple API footprint).

Getting started with Redis
To start working with Redis, you can follow the Getting Started Guide in the official documentation to start building with the Redis CLI, or by using Salesforce’s Heroku Data for Redis add-on, which we’ll go over briefly below.
Note: While the actual commands are normal Redis syntax, the setup section of the following example assumes you are using one of Heroku’s paid plans.
The Heroku Data for Redis add-on not only enables developers to quickly and conveniently integrate Redis instances into Heroku apps, but also comes pre-configured with useful features like high availability backups and automatic failover procedures. It also handles authenticating the connection between your Heroku app and Redis instance automatically.
First, create and run a new Heroku app locally. Then, create and attach a new Redis instance to your Heroku app using:
1heroku addons:create heroku-redis:hobby-devWhile waiting for the creation process to complete, you can check on its status using:
1heroku addons:infoNote: Depending on your setup, you may need to use
heroku addons:info redis -a your-heroku-app-nameinstead.
Next, start the Redis CLI by running:
1heroku redis:cliNote: If this command doesn’t get Redis up and running, you may need to install the Redis CLI first.
Now that you’re in the Redis CLI, you can use normal Redis commands right from your Heroku app’s Redis instance.
For example, PING confirms whether we are connected to the Redis instance by returning PONG if your request is successful.
1PING
2# PONGSET will set a variable name to store a string of your name, and GET will retrieve the value assigned to that key.
1SET name [yourName]
2GET nameWe can use EXPIRE to set the value of name to expire and be deleted after 5 seconds. The subsequent GET calls will prove name’s value exists, then prove it’s been deleted.
1EXPIRE name 5
2GET name
3
4# (wait 5 seconds)
5
6GET nameThe following LPUSH (left push) and RPUSH (right push)commands will create new list mylist which contains string b, add a to the front and c to the tail, then fetch the entire list.
1LPUSH mylist b
2LPUSH mylist a
3RPUSH mylist c
4LRANGE mylist 0 -1HMSET and HMGET will create and fetch a hashmap user:
1HMSET user username [your name] year 2022 verified 1
2HMGET userWhere user has the following values:
1{
2 name: [your name]
3 year: 2022
4 verified: 1
5}Further reading
You can learn more about Redis data types and CLI commands from the official docs or by checking out some of the below resources:
- 📼 What is Redis? (Jamil Spain, IBM Technology)
- 📄 Learn Redis (Tutorialspoint)
- 📼 Redis Crash Course (Web Dev Simplified)
- 📔 How Does the Internet (sailorhg)
- 📼 What is Distributed Caching? Explained with Redis! (Gaurav Sen)
- 📓 Heroku Data in Salesforce Functions (Greg Nokes, Salesforce)
- 📼 codeLive: Heroku Data in Functions with Redis (Julián Duque, Salesforce)
- 📓 Optimized Heroku-Force.com Integration Using Redis and Apex REST (Sandeep Bhanot, Salesforce)
- 📜 Heroku Data for Redis (Heroku Dev Center)
Thanks for reading, and happy caching!
About the author
tessa is a Lead Developer Advocate at Salesforce.


