

The Amazon S3 Storage Connector enables Salesforce Data Cloud to read comma-separated values (.csv) and parquet files from your Amazon S3 buckets. The data is retrieved in a batch job that you can schedule to run as often as hourly or as infrequently as monthly. You also have the flexibility to change the schedule as necessary, so don’t fret if you want something to run more or less frequently after you’ve already chosen the schedule.
In this blog post, you’ll learn how to use the Amazon S3 Storage Connector in Data Cloud to ingest data from an Amazon S3 bucket.
What is Amazon S3?
Amazon S3, also referred to as just S3, is object storage that enables you to retrieve your data from anywhere on the web. Amazon S3 stores data in a flat structure using unique identifiers to look up objects when requested. In Amazon S3, objects are stored in containers called buckets. When you create a bucket, you must choose (at the very minimum) two things: the bucket name and the AWS region that you want the bucket to reside in.
Amazon S3 use cases
Amazon S3 can be used for a wide variety of use cases. Here are some of the most common:
- Backup and storage: Amazon S3 is a natural place to back up files because it is highly redundant
- Media hosting: Because you can store unlimited objects, and each individual object can be up to 5 TB, Amazon S3 is an ideal location to host videos, photos, or music uploads
- Software delivery: You can use Amazon S3 to host your software applications for customers to download
- Data lakes: Amazon S3 is an optimal foundation for hosting a data lake because of its scalability
- Static websites: You can configure your bucket to host a static website of HTML, CSS, and client-side scripts
- Files: Because of its optimal scaling, support for large files, and the fact that you access any object over the web at any time, S3 is an ideal place to store files
Amazon S3 Storage Connector
The Amazon S3 Storage Connector is available by default in all Salesforece Data Cloud orgs. Nothing needs to be done to enable it to be used in a data stream; all you have to do is click New under Data Streams and you will see the connector.

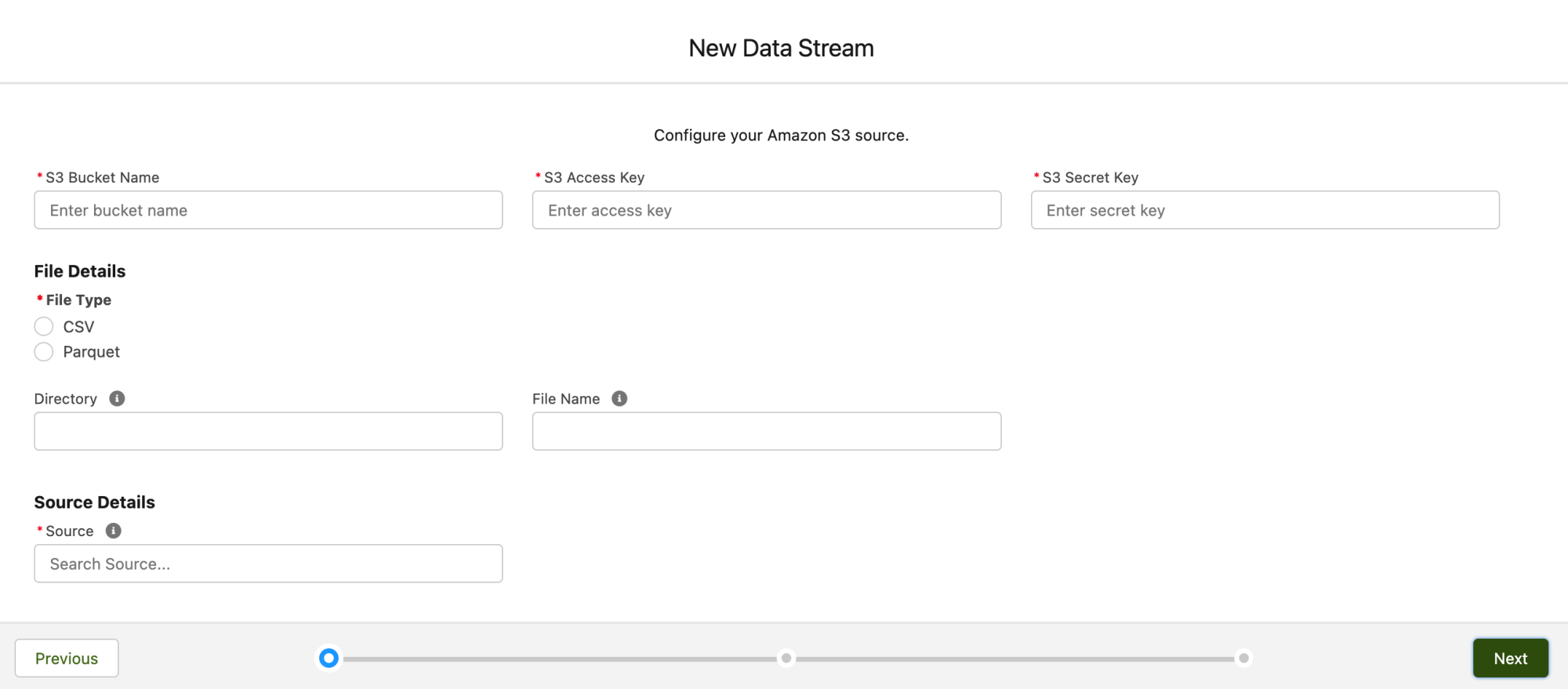
To set up a new connector from Data Cloud to Amazon S3, there are a few things that you’ll need to configure, including: bucket name, access key, secret key, the type of file, its directory, file name, and the file source. Don’t worry, we’ll show you how to configure all of this!
Creating a Bucket in Amazon S3
Let’s dive in — we’ll create an example connection between Amazon S3 and Data Cloud by taking the following steps.
To get started, we first pull up S3 in Amazon Web Services using the global search functionality. Then, we click Create bucket to create a new Amazon S3 bucket.
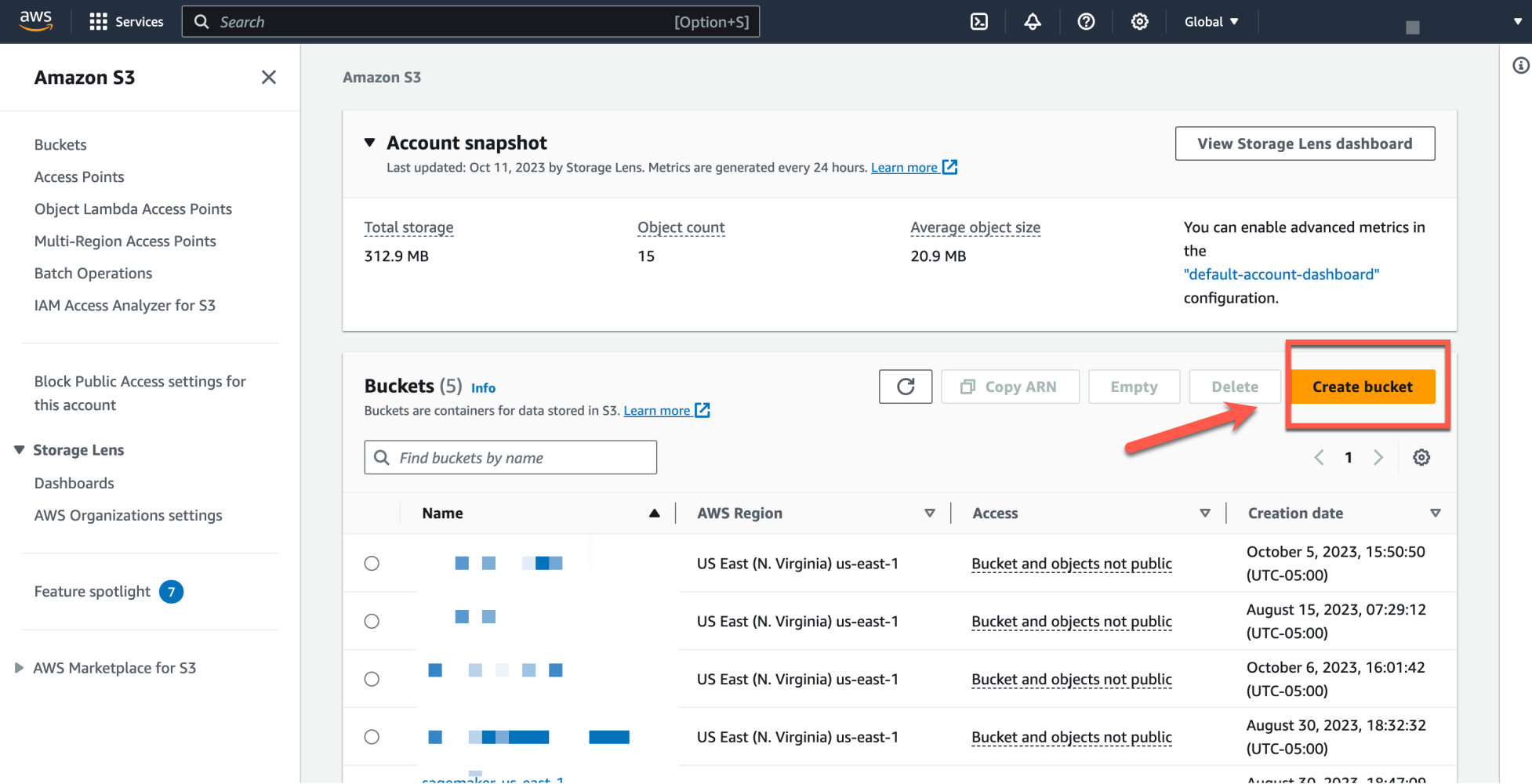
Next, we enter a name for the bucket and choose our AWS region. We can also set the security and other settings on this page. For the purpose of this demonstration, we’ll configure the minimum criteria, which is the bucket name and region.

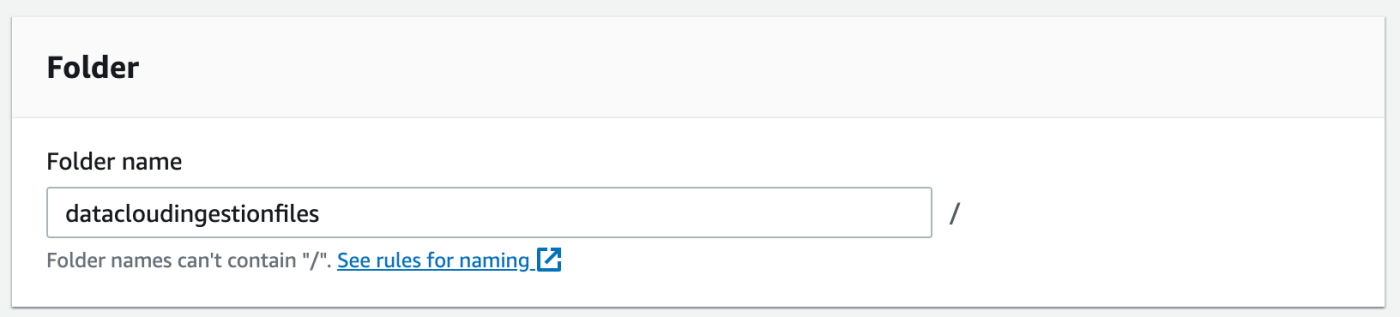
In our bucket, we will need to create a folder to serve as our directory in Data Cloud.

We then give our folder a name and create the folder.
After we have created our folder, we can then upload files to be ingested in Data Cloud. Note that Data Cloud can ingest files uploaded to Amazon S3 that are in .csv or parquet format.
Creating the integration user and generating the API keys
We then navigate to the Identity and Access Management (IAM) console in AWS and create a user that we’ll use for the integration between Amazon S3 and Data Cloud.

We enter the details for the user and follow the prompts to add additional optional configurations as necessary. Please note: no additional configurations were added for this demonstration.

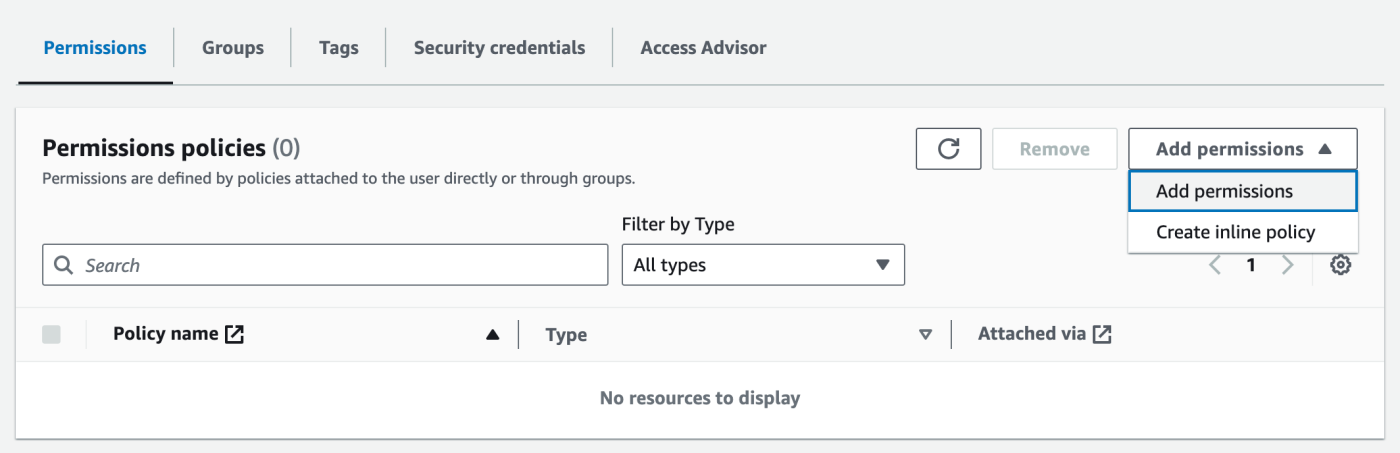
We then add the necessary S3 permissions to our integration user. We can add existing S3 policies manually, or create an in-line policy and copy the JSON (see documentation).
Now, we are ready to generate the secret and access keys that we’ll need to use in Data Cloud. We click Create access key to generate the keys that are needed.

We then need to designate to AWS what our use case is for generating these keys. For our example use case, we choose “Other.”

Next, we create a tag for our access key.
Our secret access key (secret in Data Cloud) and access key will appear. Please note: You may need to click Show to unhide your secret access key. Be sure to follow AWS’s best practices for securing your access keys.
Then, we enter all of the information necessary to configure the Amazon S3 Connector in Data Cloud. You can enter in the file name, a wildcard (*), or wildcard (*).csv as shown below.
And finally, we create and configure our data lake object that will store the data from our Amazon S3 data stream.

Closing words
Hopefully, this blog post was helpful and informative. Going forward, we’ll be publishing many more blog posts on how to use AWS with Salesforce Data Cloud. If you want to take it a step further and learn how to map your data lake object to data model objects in Data Cloud, please watch our YouTube video, where we show you how to map your ingested data in your data lake object to data model objects in Data Cloud. Also, we encourage you to take these two trails on Trailhead, Learn AWS Cloud Practioner Essentials and AWS Cloud for Technical Professionals, to strengthen your AWS knowledge. Now let’s get streaming!
Resources
- Learn more about Salesforce Data Cloud
- Documentation: AWS Identity and Access Management
- Documentation: Bucket Policies and User Policies
- Documentation: Policies and Permissions in S3
- Video: Mapping Data Streams
- Trailhead: Learn AWS Cloud Practioner Essentials
- Trailhead: AWS Cloud for Technical Professionals
About the author

Danielle Larregui is a Senior Developer Advocate at Salesforce focusing on the Data Cloud platform. She enjoys learning about cloud technologies, speaking at and attending tech conferences, and engaging with technical communities. You can follow her on X(Twitter).




