


In our previous blog post, The ApexGuru AI Engine Explained, we showed how ApexGuru identifies performance antipatterns, and goes further by prioritizing the ones that matter most and delivering prescriptive, contextual fix recommendations. That post highlighted how ApexGuru combines runtime telemetry with specialized models to help developers not only see problems, but also act on them with confidence.
This blog post builds on that foundation. Here, we take you behind the scenes of ApexGuru’s newest capability: a multi-agent workflow that doesn’t just recommend fixes, but generates, validates, and refines Apex code changes automatically. It’s the next step — moving from recommendations into true remediation at scale.
Multi-agent workflows with ApexGuru
ApexGuru already detects 20 antipattern variants across customer implementations and offers recommendations where practical. This new methodology targets semantic refactoring for performance optimization and pushes that “practical” boundary using agentic workflows to address complex patterns that previously we could only detect. Some of these are SOQL/DML in loops (bulkification), redundant SOQL on a single sObject (SOQL merge), and aggregation in Apex (should be pushed down into SOQL).
These antipatterns show up frequently in real-world orgs, and remediating them manually often slows down development teams. ApexGuru’s goal is to turn that recurring overhead into an automated safety net, allowing developers to focus on delivering features instead of re-fixing the same issues.
So, why use agents? These fixes require deep, non-local reasoning; in practice, that means understanding code across methods and data flows, often spanning hundreds of lines. This complexity is challenging for traditional heuristics or supervised approaches. To deliver faster, the ApexGuru product team explored agentic workflows on commercial models (GPT-4.1, Gemini) rather than training bespoke models from scratch.
The Agentic pipeline: DML in a Loop
Let’s go through the full agentic code fixing workflow for the antipattern DML in Loop.
Apex developers sometimes place DML operations inside loops, such as insert, update, or delete for each record. While functional, this pattern quickly leads to excessive CPU usage and governor limit violations. Best practice is to bulkify the logic by collecting records and executing DML outside of the loop.
Our multi-agent pipeline handles this by detecting loop-contained DMLs, filtering for fixable cases, generating bulkified fixes, and validating correctness with semantic checks.
Data and evaluation approach
For reliable benchmarking and prompt refinement, our team evaluated models on a large, diverse set of human-annotated samples, aiming for ≥100 annotated samples per antipattern. This underpins model selection, prompt iteration, and quality evaluation, and such a level of rigor in evaluation is critical for building developer trust. Automated fixes only work if they’ve been tested across diverse, realistic cases that mirror the challenges that teams encounter in production.
The multi-agent pipeline
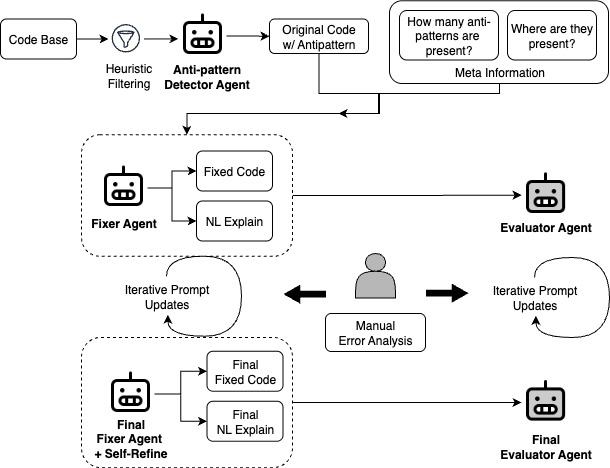
The first step in our analysis is to scan the code base for potential antipattern candidates. This heuristic pre-filtering isolates likely antipatterns for the next stage, which reduces model load and false positives.
The final pipeline adopts a multi-agent setup:
- Detector agent labels candidate methods for the target antipattern (e.g., DML in a Loop) and notes whether it can be fixed without breaking functional equivalence
- Fixer agent admits only Yes-labeled candidates to be fixed
- Self-refinement Fixer agent generates and iteratively improves a code patch
- Evaluator agent assesses correctness and quality in the development stage, helping to validate the Detector and Fixer agent performance
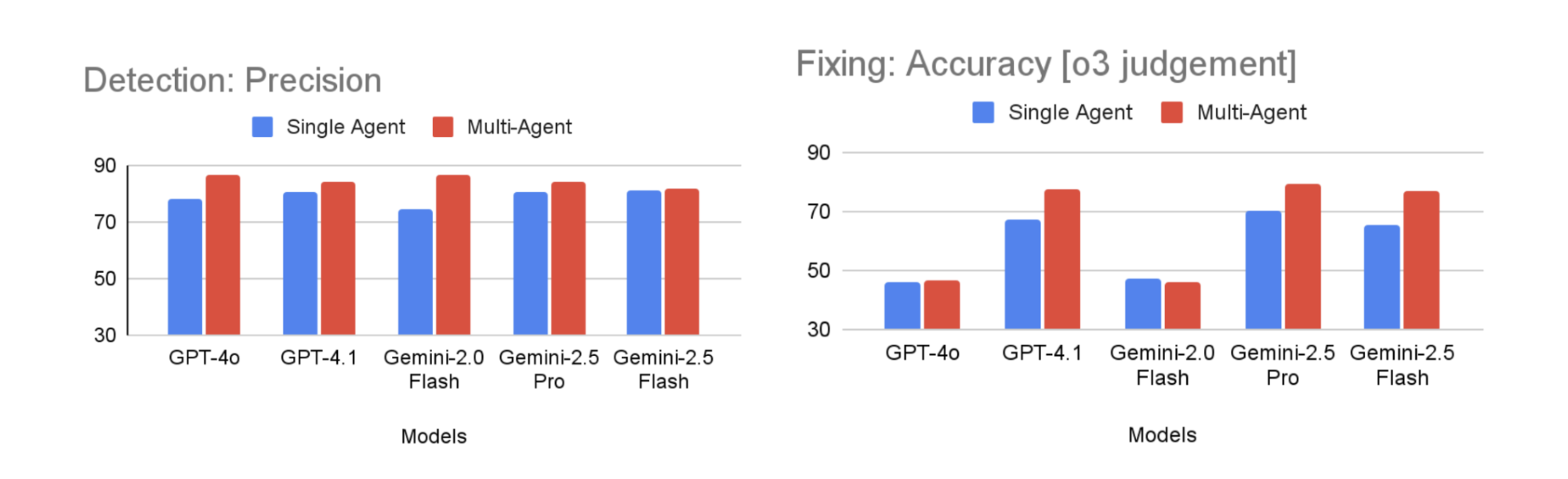
This distributed design improves both detection precision and code-fix accuracy vs. single-agent prompting, and is used as the final configuration.
Code example
Original excerpt
1for (Contact c : contactsToUpdate) {
2 c.Status__c = 'Inactive';
3 update c;
4}Fix attempt (excerpt)
1for (Contact c : contactsToUpdate) {
2 c.Status__c = 'Inactive';
3}
4update contactsToUpdate;Key takeaway: The Fixer agent correctly moved the DML operation outside of the loop, bulkifying the update and ensuring that the code scales without hitting governor limits.
The Evaluator agent is used in the development stage to validate correctness by checking functional equivalence. As shown in the chart below, this multi-agent setup consistently outperforms single-agent prompting across models as judged by the o3 Evaluator agent.
On the left, detection precision rises when dedicated Detector and Filter agents are used, eliminating noise before fixes are attempted. On the right, fixing accuracy improves sharply for models like GPT-4.1 and Gemini-2.5 Pro, where iterative self-refinement allows the Fixer agent to converge on higher-quality patches. These gains validate the choice of multi-agent pipelines as ApexGuru’s final configuration.
Iterative prompt refinement
Across multiple antipatterns, including DML in a Loop, we observed the same trend: iterative refinement cycles steadily improved robustness.
- An initial fixer evaluation scored around 41%
- After refining fixer prompts (clarifying exception-handling and loop handling), the score increased to 63%
- Tightening evaluator prompts (e.g., catching outer-loop DML cases) adjusted the evaluation to 59%, reflecting a stricter but more reliable judge
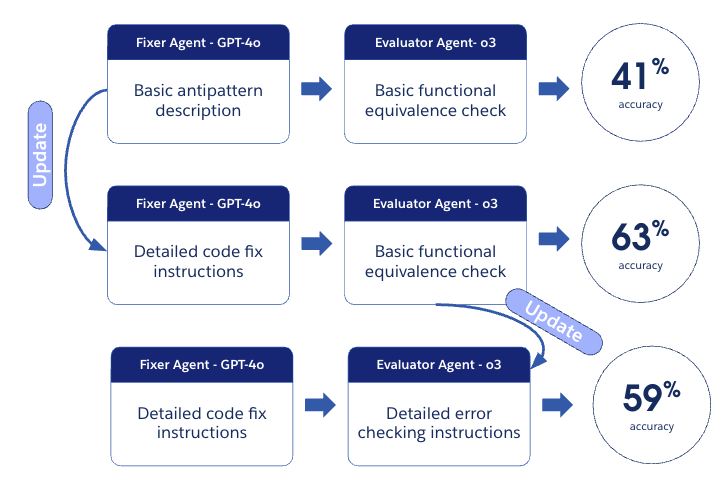
This demonstrates that fixer/evaluator co-evolution — where fixes are iteratively improved and judged against stricter criteria — is key to raising system accuracy beyond baseline prompting.
Iterative refinement ensures that the system not only improves over time but also remains predictable and dependable. This stability is what makes developers comfortable adopting automated fixes in their workflows.
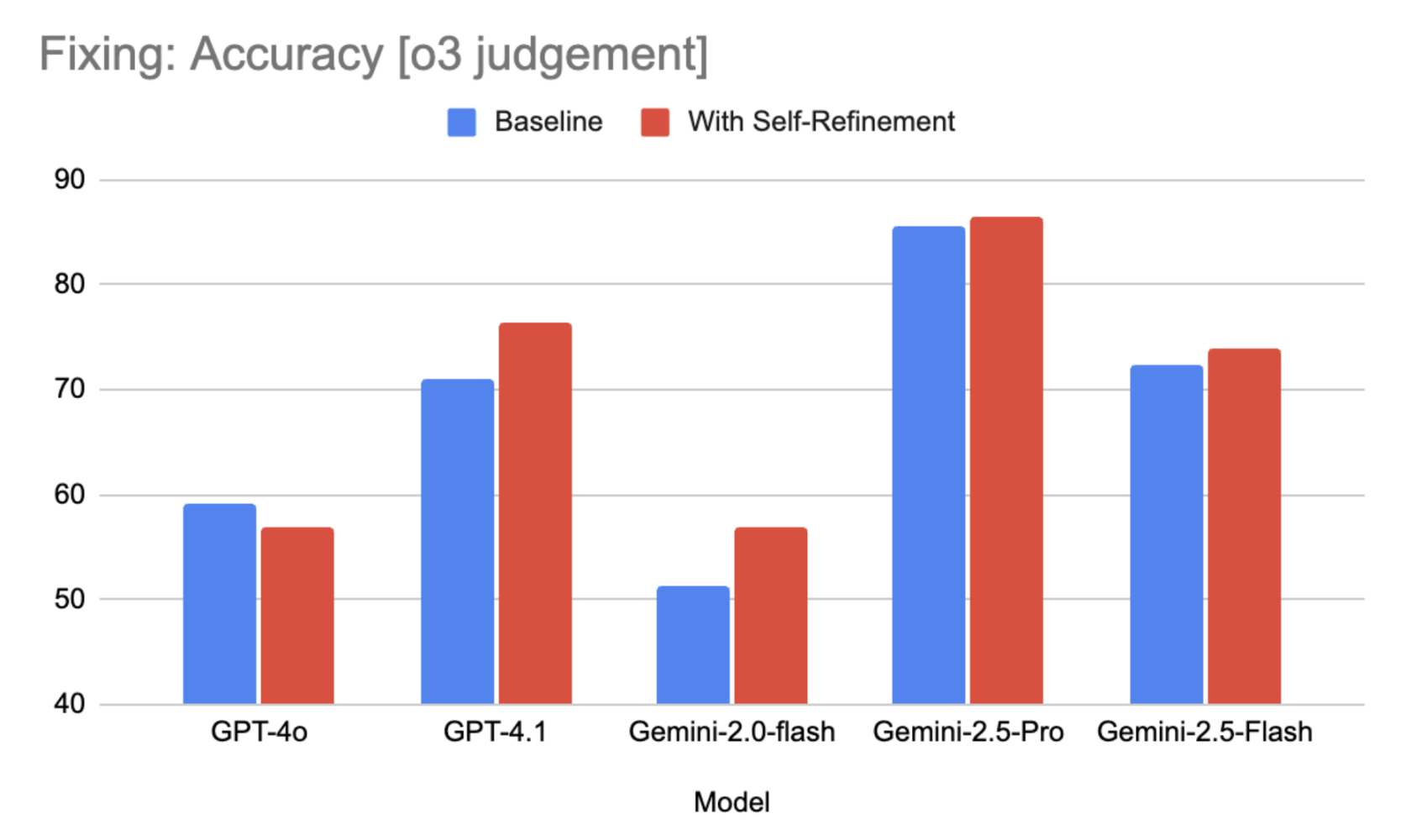
Fixer agent self-refinement
Another way to further improve accuracy of the code fixes is to prompt the Fixer agent to perform self-refinement, i.e., ask it to double-check its generated code for any errors and rewrite it based on that information.
The plot below shows that adding self-refinement to the prompt leads to better code fixing accuracy across several models.
Natural language descriptions
In addition to rewriting code snippets to remove the antipattern, the Fixer agent also generates a natural language description of the code changes. This aims to make code changes easier to track and streamline the review process for Fixer agent-generated code, ensuring that users can validate the output before integration.
We evaluated the accuracy of these descriptions using an Evaluator agent, and performed agent-simulated A/B testing to gauge their utility. Specifically, we checked if providing this natural language description as a prompt input to GPT-4o improved the quality of the code fixes it produces compared to a template prompt, which would indicate that it contains a helpful description of the code changes to perform.

The table above shows that code fixing accuracy improves significantly when given these descriptions; if the accuracy of the description improves, so does the code fix accuracy. This demonstrates that these descriptions offer valuable guidance for performing code fixes. We anticipate that this additional information not only helps users identify potential errors, but also empowers them to write their own code fixes if necessary.
Results across various LLMs as agents
The table below shows the accuracy results for different LLMs playing the part of the various agents, according to o3 evaluator agent judgments, averaged across multiple runs.
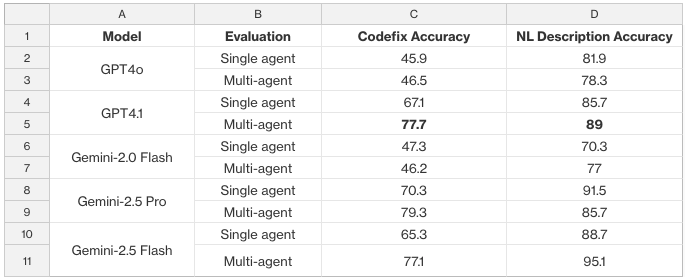
We find that GPT-4.1 provides the best overall accuracy for code fixes and NL descriptions. Our team further validated the final end-to-end pipeline with GPT-4.1 on a held-out, ~800-sample test set, achieving 77.6% code-fix accuracy for the DML in a Loop antipattern (averaged over multiple runs).
DML in a Loop is one of the most common reasons that orgs hit governor limits in production. Automating bulkification here helps prevent escalations and frees teams from repeatedly rewriting the same pattern.
Additional antipattern examples
Here are the results and examples of similar workflows for three additional antipatterns.
Example 1: SOQL in a Loop best method results summary
All loop nodes (for/while) present in a class with any child node corresponding to a static SOQL query is flagged as the SOQL in a Loop antipattern. All detected antipattern instances are then passed on to the fixing stage to generate recommendations for bulkification of database interactions in Apex.
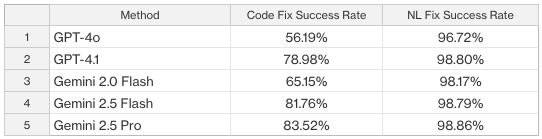
Key takeaway: In the table above, across all models, the multi-agent and self-refine configuration consistently outperforms baseline prompting, with Gemini 2.5 Pro achieving the highest score (83.52% code-fix success). Importantly, all models deliver >96% success on natural language (NL) fixes, confirming robustness in less code-intensive scenarios.
For developers, this directly reduces the risk of governor-limit errors derailing late-stage testing or deployments. Higher accuracy in automated fixes means fewer manual rewrites and faster code reviews.
Code examples: Multiple SOQL in a Loop sites
Original excerpt
1// 1st SOQL-in-Loop
2Country__c country = [SELECT Id, Name FROM Country__c WHERE Id = :countrycode LIMIT 1];
3
4// 2nd SOQL-in-Loop
5User capOwner = [SELECT Id, Name, REP_Manager__c, ManagerId FROM User WHERE Id = :capRecords.OwnerId];
6
7// 3rd SOQL-in-Loop
8List existingCapRecord =
9 [SELECT Id, OwnerId FROM Commercial_Action_Plan__c WHERE OwnerId = :UserInfo.getUserId()];Each query is embedded directly in a loop, which multiplies roundtrips to the database. Under high record volumes, this pattern quickly leads to governor limit violations (SOQL 101) and adds unnecessary CPU overhead.
Fix attempt (excerpt)
1Set countryIds = new Set();
2Set ownerIds = new Set();
3for (Commercial_Action_Plan__c capRecords : capRecordsList) {
4 if (capRecords.Country__c != null)
5 countryIds.add(capRecords.Country__c);
6 if (capRecords.OwnerId != null)
7 ownerIds.add(capRecords.OwnerId);
8}
9
10Map<Id, Country__c> countryMap = new Map<Id, Country__c>(
11 [SELECT Id, Name FROM Country__c WHERE Id IN :countryIds]);
12
13Map<Id, User> userMap = new Map<Id, User>(
14 [SELECT Id, Name, REP_Manager__c, ManagerId FROM User WHERE Id IN :ownerIds]);- The first two SOQL in a Loop sites are eliminated by collecting all IDs upfront and issuing set-based queries. This is the correct bulkification strategy.
- The third SOQL in a Loop remains unhandled. The Fixer agent didn’t fully generalize the pattern, leaving partial coverage. This is a common failure case: fixes may solve some loop sites, but miss others in the same method.
Key takeaway: Even with automation, developers must review generated patches, ensuring that all query sites are covered before accepting fixes.
Example 2: Redundant SOQL best method results summary
Redundant SOQL queries occur when multiple queries on the same SObject are issued within the same Apex method, even though they could be merged. This antipattern increases database round trips and consumes unnecessary CPU. Our pipeline addresses this through a multi-agent workflow.
Evaluation of redundant SOQL code fix and NL fix accuracy
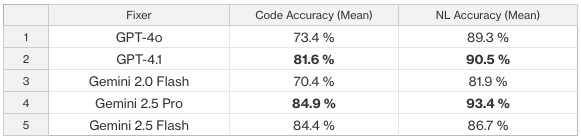
Key takeaways
- High accuracy is achievable: Top models fix ~eight to nine out of 10 redundant query cases correctly
- Gemini 2.5 Pro led in code fix accuracy (84.9%)
- GPT-4.1 produced the clearest NL explanations (90.5%)
- Lower variance values show consistent fixes and explanations, which is crucial for developer trust.
Code example
Multiple queries on the same object with overlapping filters/fields waste DB roundtrips and CPU.
Original excerpt
1List activeAccounts = [
2 SELECT Id, Name, Status__c
3 FROM Account
4 WHERE Status__c = 'Active'
5];
6List accountOwners = [
7 SELECT Id, OwnerId, Status__c
8 FROM Account
9 WHERE Status__c = 'Active'
10];Fix attempt (excerpt)
1List activeAccounts = [
2 SELECT Id, Name, OwnerId, Status__c
3 FROM Account
4 WHERE Status__c = 'Active'
5];Key takeaway: The Fixer agent merged two queries into one unified projection, reducing query count and aligning with Salesforce best practices.
Automating redundant query merges is both a performance and productivity win. It streamlines codebases, reduces review overhead, and helps teams avoid repetitive fixes across multiple classes.
Example 3: Aggregation in Apex best method summary
Aggregation antipatterns occur when record summarization is performed in Apex loops instead of using aggregate SOQL queries. For example, developers may iterate over large datasets in Apex and compute counts, sums, or maximums manually. This is functional but inefficient: it increases CPU time and consumes heap unnecessarily, compared to letting the database handle aggregation.
Our Detector agent functions as a domain-specific syntax analyzer that systematically scans Apex code to identify occurrences of loop-based aggregation. It also extracts rich contextual information, including the specific SOQL variables involved, the aggregation operators used, the surrounding loop structures, and whether a GROUP BY clause is required. This extracted metadata forms the foundation of a structured context that is passed to the code fixer agent.
Key takeaways: The detector for this antipattern demonstrates strong performance, achieving a precision of 91.91% and a recall of 88.33%. The code fixer also achieves a high accuracy of 93.71%. This strong result demonstrates the effectiveness of the fixer in automatically resolving SOQL aggregation antipatterns with minimal need for manual intervention.
Code example
Here is an example of Apex performing aggregation in loops instead of leveraging SOQL.
Original excerpt
1Integer closedCount = 0;
2for (Case c : [
3 SELECT Id, Status
4 FROM Case
5]) {
6 if (c.Status == 'Closed') {
7 closedCount++;
8 }
9}Fix attempt (excerpt)
1Integer closedCount = [
2 SELECT COUNT()
3 FROM Case
4 WHERE Status = 'Closed'
5];Key takeaway: Instead of scanning all Case records in Apex and incrementing a counter, the Fixer agent pushes aggregation into SOQL, reducing CPU and heap usage dramatically.
Even partial automation here provides significant value. Teams spend countless hours hand-optimizing loops, but automatically pushing these computations into SOQL saves CPU, keeps orgs within limits, and improves scalability without extra developer effort.
Latest ApexGuru features are now Generally Available
Beyond our agentic code-fixing behind the scenes, ApexGuru is also shipping new features that developers can use right now:
- Test Case Insights: Prevent misleading coverage by flagging filler statements and outdated
testMethodusage, helping teams maintain reliable test suites - On-Demand Insights: Run up to three insights per week, in your local time zone, and align performance reviews with sprint cycles.
- 5× Expanded Antipattern Coverage: New detections for SOQL Without Platform Cache, Sorting in Apex, SObject Map in a For Loop, Copying List or Set Elements Using a For Loop , and Aggregating Records in Apex give developers fewer runtime surprises and cleaner codebases.
- In-App Feedback: Share feedback right inside ApexGuru, ensuring that the product evolves with your real-world needs.
Conclusion
With ApexGuru’s new agentic pipeline, we are moving beyond detection and recommendation into true automated remediation of Apex antipatterns. By combining Detector, Filter, Fixer, and Evaluator agents, we’ve shown that complex refactorings — from SOQL/DML in loops to redundant queries and inefficient aggregations — can be automated with accuracy levels that rival human fixes.
For developers, the takeaway is simple: ApexGuru is no longer just an assistant that tells you what’s wrong — it’s a system that can propose, validate, and refine fixes you can trust. This capability means less time firefighting governor limits and more time building scalable, performant features.
The latest GA features noted above show how this vision is already reaching developers in their day-to-day workflows. These advances turn ApexGuru from a passive assistant into an active partner that proposes, validates, and refines trusted fixes. Adoption has been strong: nearly 10,200 orgs have opted into ApexGuru, with over 110,000 performance-focused recommendations already implemented. This growth since GA reflects the clear value that developers see in automating performance fixes.
Looking ahead, our focus is on expanding coverage across all 20+ antipattern variants already in scope, while also shifting left by bringing ApexGuru insights directly into the IDE where developers work. By embedding fixes closer to the point of coding, alongside deeper integration into the broader workflow, our goal is to give every Salesforce team a reliable safety net that keeps Apex code correct, efficient, and future-proof — so developers spend less time firefighting and more time building.
About the authors
- Prathyusha Jwalapuram is an Applied Scientist at Salesforce working on ApexGuru. Reach out to her on LinkedIn.
- Mayuresh Verma is a Product Manager at Salesforce working on the Scalability Products portfolio. Reach out to him on LinkedIn.
Special thanks to Akhilesh Gotmare, Senior Staff Research at Salesforce (LinkedIn); Wenzhuo Yang, Lead Research Scientist at Salesforce (LinkedIn); and Ziyang Luo, Research Scientist at Salesforce (LinkedIn), for their contributions to this blog post.





