 You are planning a Force.com implementation with large volumes of data. Your data model is in place, all your code is written and has been tested, and now it’s time to load the objects, some of which have tens of millions of records.
You are planning a Force.com implementation with large volumes of data. Your data model is in place, all your code is written and has been tested, and now it’s time to load the objects, some of which have tens of millions of records.
What is the most efficient way to get all those records into the system?
The Force.com Extreme Data Loading Series
This is the first in a six-part series of blog posts covering all aspects of data loading for very large enterprise deployments. Here are the topics planned for this series.
- Designing the data model for performance
- Loading data into a lean configuration
- Suspending events that fire on insert
- Sequencing load operations
- Loading and extracting data
- Taking advantage of deferred sharing calculations
This first post explores some crucial decisions you can make in data model design to ensure good performance far into the future. The most important decisions you make to ease the loading of big data can happen much earlier in your project ? when you are designing your data model. Some choices in object structure, fields, and relationships may fit your business requirements, but cause problems later during data loading or operations. This post highlights four common issues: object bloat, slow queries, record ownership skew, and parent/child data skew.
Force.com Object Bloat
As a Salesforce architect, administrator, or application developer, you are likely familiar with this scenario: your business users have a hard time focusing on exactly what data is required to manage the process they are trying to automate. So you end up with objects with large numbers of fields, “just in case.” Perhaps this works when the organization doesn’t yet have much data, but as time goes on and record counts reach up into the millions, you start getting complaints about slow custom-built pages, list views, and reports.
The Solution
When business requirements demand large objects, there is a platform feature that can significantly improve performance ? the “skinny table.” For example, after careful analysis of the fields that a report requires, you can use a skinny table to hold just those fields. The report will then calculate and display much faster because the underlying query scans fewer fields.

Put It Into Practice
To minimize the impact of large objects on future queries, list views, and reports, consider the following when designing your data model:
- include only those fields truly necessary by business requirements
- if requirements do call for an object with a large number of fields, ask Salesforce Support to help you create a skinny table that contains only the required fields
Force.com Slow Queries
You’ve got a nice lean set of objects, and all the code for integrations and custom Visualforce pages has been written and performs well with test data. Everything is going fine as customers begin to use the system, but then performance begins to degrade seriously when the organization loads or accumulates a large amount of data.
The Solution
You can anticipate and prevent query performance from degrading by understanding and using indexed fields in your queries. The Salesforce platform includes its own query optimizer that takes advantage of indexed fields to create the most efficient execution plan for a given query. The handy cheat sheet below shows which fields Salesforce always indexes in objects.

In addition to these standard fields, Salesforce also allows customers to create custom indexes on most fields. The exceptions are: non-deterministic formula fields, multi-select picklists, currency fields in a multi-currency org, long text area and rich text area fields, and binary fields (type blob, file or encrypted text).
Put It Into Practice
To ensure good query performance as data volumes increase in an organization:
- take advantage of standard indexed fields whenever possible in your query designs
- ask Salesforce Support to help you create custom indexes to speed up specific queries
You can find more information on how the Salesforce query optimizer takes advantage of standard and custom indexes to speed query execution in the doc “Best Practices for Deployments with Large Data Volumes” in the reference section below.
Force.com Record Ownership Skew
The concept of record ownership is a very powerful feature for managing record access on the Salesforce platform. When individual users own the records they create, the role hierarchy makes sure managers have access to the data owned by their subordinates. But when a single user owns a very high percentage of the data for any one object, Force.com must perform large sharing recalculations when you move that user in the hierarchy. These recalculations can be even worse when you add or remove the user to a role or public group that uses a sharing rule to make its data visible to other users in the organization.
The Solution
Avoid assigning a single user as owner of a large amount of data whenever possible.
Put It Into Practice
To avoid potentially long-running sharing recalculations caused by concentrating record ownership:
- Design your ownership strategy from the beginning so that users own the data they create, then use the role hierarchy and sharing rules to provide access to others.
- When you must have a single owner for a large amount of data, place that user in their own role at the top of the hierarchy, use sharing to provide access for other users, and don’t move that user to a new role.
For more information about managing data ownership skew, consult the doc “Architect Salesforce Record Ownership Skew for Peak Performance in Large Data Volume Environments” below.
Force.com Parent / Child Data Skew
Salesforce.com’s salesforce automation and customer service management applications have built in data sharing features that handle many of the most common use cases for management of Accounts, Opportunities, Cases and Contacts. For example, the platform maintains the rule that when a user can see a Contact, they can also see the parent Account. But when a very large number of child records are associated with the same parent record, performance can degrade when the ownership of Contacts changes.
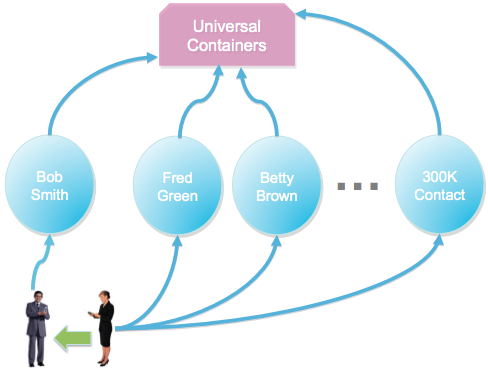
For example, in the diagram above Jean is transferring the Contact “Bob Smith” to her teammate, Thomas. So Thomas should gain access to the parent Universal Containers Account, and Jean should lose access. But if Jean owns any of the other 299,999 contacts under the Account, she should retain access. To resolve this situation, the platform has to check every one of these Contacts to make sure Jean is not the owner. This underlying operation can take a substantial amount of time.
The Solution
To avoid issues with parent/child data skew, salesforce.com recommends that you keep the number of child records assigned to a single parent below 10,000.
Put It Into Practice
If your organization has a corporate, business-to-business relationship with its customers, you are unlikely to encounter this issue because you will rarely have thousands of contacts at a single Account. But if you are selling direct to consumers, you may not have a strong notion of an Account separate from the individual consumer. In this situation, you may have a strong temptation to put all your contacts under the same account, but you will come to regret it. Instead, salesforce.com recommends the following:
- Plan your data model with enough Accounts to keep the parent/child ratio below 10,000, and distribute new child records across these Accounts as the child records are created.
- Engage an architect from Salesforce Strategic Services to help you design the best way to manage the initial configuration and growth over time.
For more information about managing parent/child data skew, consult the doc “Reducing Lock Contention by Avoiding Account Data Skews” below.
Summary
When planning a Salesforce implementation that will serve a large number of users with a large amount of data, design your data model to build scalability in from the beginning. Key elements to consider include:
- Keep objects as lean as possible ? where you can’t, consider using skinny tables.
- Take advantage of fields indexed by default, and create custom indexes to improve performance of queries, list views, and reports.
- Distribute records across owners and parent objects to avoid skew-related performance problems.
Related Resources
- Best Practices for Deployments with Large Data Volumes
- Architect Salesforce Record Ownership Skew for Peak Performance in Large Data Volume Environments
- Reducing Lock Contention by Avoiding Account Data Skews
- Architect Core Resources
About the Author and CCE Technical Enablement
Bud Vieira is a member of the Technical Enablement team within the salesforce.com Customer-Centric Engineering group. The team’s mission is to help customers understand how to implement technically sound salesforce.com solutions. Check out all of the resources that this team maintains on the Architect Core Resources page of Developer Force.