
 If you regularly perform Salesforce implementations with objects that store a lot of records, you probably already know about the strategies that you can use to appropriately manage and distribute your data. Some of the more obvious strategies include using indexes, skinny tables, archival strategies, and even divisions.
If you regularly perform Salesforce implementations with objects that store a lot of records, you probably already know about the strategies that you can use to appropriately manage and distribute your data. Some of the more obvious strategies include using indexes, skinny tables, archival strategies, and even divisions.
However, even if you choose the most appropriate strategy or strategies, you might miss a lesser-known “silent killer” within your architecture: lookup skew.
Read this blog post to learn both how lookup skew affects objects with large volumes of data and what you can do now to minimize its effects.
Types of Salesforce Data Skew
You’re probably wondering what lookup skew is and what kind of trouble it can cause, but before we head down those paths, let’s make sure you are familiar with the concepts of account data skew and ownership skew. Understanding these concepts and this post’s lessons will give you a comprehensive view of the most common data relationship issues we see.
Account Data Skew
Certain Salesforce objects, such as accounts and opportunities, have special data relationships that maintain parent and child record access under private sharing models. If too many child records are associated with same parent object in one of these relationships, this imbalance causes something called “account data skew,” which in turn causes performance problems.
If you are unfamiliar with account data skew, you can read more about it here.
Ownership Skew
Similarly, when a large number of records with the same object type are owned by a single user, this imbalance causes something called “ownership skew.” Ownership skew also causes performance problems, which can surface when you’re managing your role hierarchy and sharing rules.
If you are unfamiliar with ownership skew, you can read more about it here.
Lookup Skew
Lookup skew happens when a very large number of records are associated to a single record in the lookup object. Because you can place lookup fields on any object in Salesforce, lookup skew can create problems for any object within your organization.
Let’s take a look at an example.
Company XYZ has 500,000 accounts in its production instance of Salesforce. The company’s sales organization wants to track an educational achievement level, so it configures the following custom object to store an achievement level and a description.

Next, it adds the achievement level to the account object as a lookup field.

Company XYZ then creates three achievement levels, into which all of its accounts must be categorized.
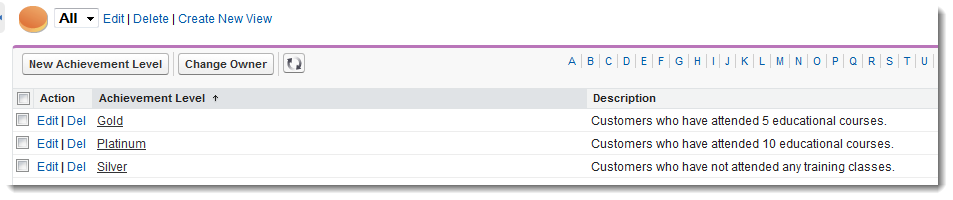
Finally, Company XYZ loads the update to its account records so that it can associate each account with an achievement level. No problem, right? Wrong. What we have just created is a very simple example of lookup skew. Even if the distribution between the lookup records is evenly split, you will have 166,000 accounts looking up to each of the three achievement levels. Lookup skew occurs when a very large number of records look up to the same record on a lookup object regardless of whether that lookup exists on a single object or across many objects.
What Makes Lookup Skew So Bad?
Lookup fields in Salesforce are essentially foreign key relationships between objects. Every time a record is inserted or updated, Salesforce must lock the target records that are selected for each lookup field; this practice ensures that, when when the data is committed to the database, its integrity is maintained. If Salesforce did not lock each of the lookup records while saving, and one record was deleted in the middle of the save operation, you would face a referential integrity issue. Under normal circumstances, save operations execute so quickly that you don’t encounter locks. However, when you add custom code and a large volume of data simultaneously in an automated process, you might encounter lock exceptions that cause failures when you try to insert or update records.
Identifying Lookup Skew
Since there aren’t any tools specifically designed to identify lookup skew, finding these architectural issues can be like finding a needle in a haystack. It is important to remember that lookup skew under certain usage patterns may not cause any problem at all so it is best to search based on patterns that will cause problems. You should evaluate objects with:
- A large number of records
- Heavy concurrent insert and update activity
Even objects with a smaller number of records can be at risk if concurrent transaction volume is large however it is more often the case with large data volume objects. Once you have identified the objects which are at risk, you need to look at each of the lookup fields on those objects. You can use one of two strategies to identify problems with your data model:
- If you are very familiar with your data shape, you may be able to determine if skew exists simply by looking at each of the lookup fields.
- If you are unfamiliar with your data shape, you will need to extract the lookup values into a spreadsheet or database to identify areas where lookup skew exists.
Strategies for Mitigating Problems Related to Lookup Skew
You can address the lock exceptions associated with lookup skew in many ways. Any time you encounter any type of lock exception, the mitigation strategy always revolves around reducing the frequency and duration of the offending locks.
Use the following strategies to mitigate locking issues related to lookup skew.
Reducing Record Save Time
Increasing record save performance reduces the duration of locks, which reduces or eliminates lock failures, and has the added benefit of providing an enhanced end user experience!
There are several ways to go about increasing record save performance.
- Increase the performance of synchronous apex code–tune you triggers for peak performance by consolidating code into a single trigger per object and following Apex best practices.
- Remove unnecessary workflow or consolidate into existing trigger code–workflow lengthens the lock duration, which in turn increases the lock failure rate. Removing or consolidating workflow into your Apex code can increase your save performance.
- Only process what’s required–move any code that isn’t required immediately upon save to asynchronous processing. Locks are held the entire time your custom code is executing, so processing logic that is not critical during the save will increase the lock failure rate.
There are many excellent articles on tuning Apex and large data volume best practices available on the Architect Core Resources page.
Distributing the Skew
For lookup skew, the root of the problem is that a large number of records look up to a single record. We can distribute the skew to resolve the problem. The first step is to identify which lookup records are heavily skewed. If you add additional lookup values to distribute the skew, you can significantly reduce or even eliminate your lock exceptions.
In some situations, the lookup skew is on a single generic value, which is created as a catchall. Assuming in the previous example that most customers have not taken training at XYZ Company, the “Silver” achievement level falls into this catchall category because it represents customers who have not yet attended any training. Instead of heavily skewing many customers who will never take any training with this lookup value, we could have just left the lookup blank for those customers. Note that there might still be a problem if XYZ Company customers all start taking classes, and the majority of accounts wind up achieving “Gold” and “Platinum” levels. Over time, a lookup skew would be created, which could cause long-term scalability issues with XYZ Company’s architecture.
Using a Picklist Field
When you have a relatively low number of lookup values, it’s generally a good idea to use a picklist field rather than a lookup field to define those values. By defining those values as a picklist, you can eliminate locks associated with lookups on those records, which eliminates any kind of locking issues related to lookup skew. In many cases, you cannot substitute a picklist for a lookup field if you have additional fields and other data on the lookup records. The main point here is that you should generally avoid using a lookup field to represent data that can be accommodated by a picklist.
Reducing the Load
In most cases, end user load will not be heavy enough to cause lock exceptions when lookup skew exists. If it is, carefully consider your save performance. It is far more likely that automated processes or integrations running in parallel would create problems for themselves and other users in the system. One way to address this problem is to reduce the load created by the automated process, which you can do by running the automated processes serially during non-peak periods. If automated processing must occur during your end user operations, and your end users are encountering locks, then you can reduce the batch size to reduce the lock duration and allow your end users to obtain the lock. You can prioritize the end users’ access to the locks to ensure they are not impacted by the automated processes.
Summary
Lookup fields play a critical role in every customer’s data architecture. In fact, they are so common that many architects add them without a second thought about what types of problems they might cause. If you end up with lookup skew and have a highly complex custom implementation, you might be creating a problem without realizing it. By carefully considering your options for managing lookup skew, you can avert lock issues on lookup fields to ensure that your architecture can scale to meet your organization’s growth.
Related Resources
- Overview of Object Relationships
- Best Practices for Deployments with Large Data Volumes
- Extreme Salesforce Data Volumes webinar
- Architect Core Resources
About the Author and CCE Technical Enablement
Sean Regan is an Architect Evangelist within the Technical Enablement team of the salesforce.com Customer-Centric Engineering group. The team’s mission is to help customers understand how to implement technically sound salesforce.com solutions. Check out all of the resources that this team maintains on the Architect Core Resources page of Developer Force.




