

If you’ve been around Salesforce long enough, you have probably encountered a screen that looks like this one here:
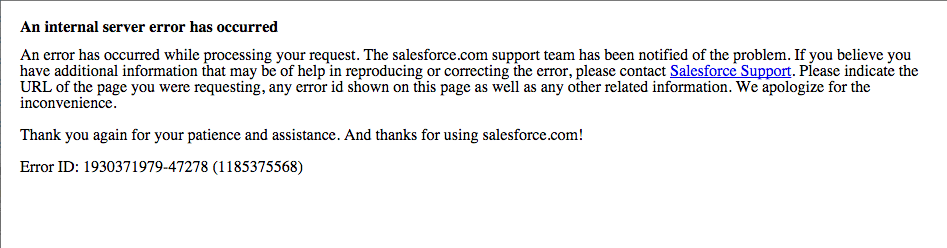
What you are looking at is what we call a GACK. A gack is our blue screen of death, our frowny Mac icon, our “the number you have reached is no longer in service”, our “Jedediah has died of dysentery”. A gack is what happens when an error got thrown within our application and we didn’t catch it and handle it.
What this means is that it’s not your fault. It’s ours. That’s why we apologize in that message. Sorry!
This friendly message is the above-water portion of a huge iceberg of functionality. The numbers you see are part of an elaborate system for efficiently bringing these events to the attention of R&D. This post will help you understand that system, and how you can help us in getting you running safely. (Hint: steer away from icebergs.)
The Numbers
On gack notification such as these, you will see two numbers. The first of these numbers has a hyphen in it, and the second number is in parentheses. These two numbers, respectively, are the identifying ID for that specific event, and the general stack trace that was produced by that failure.
Gacks are going to happen. We run nearly 3 billion transactions per day; even a Six Sigma certified process would expect 10,000 errors a day at this volume. When you throw the complexity of our application stack on top of the creativity of the Apex developer, you can imagine that we get more than 10,000 a day. We’re not manufacturing widgets; we’re manufacturing a system that lets you try your hand at manufacturing widgets. In the cloud. In a multi-tenant environment. It’s complicated.
We get a lot of gacks because there are a lot of you out there. If a feature goes out with an unhandled exception, it could be hit by thousands of users per day. Even if it’s only affecting one org, we still can get scores of gacks that are symptoms of the same problem.
Needless to say (but I will say it anyways), it would be impossible to sort through every single unique gack event. Salesforce built an internal system to help us find signal within the noise.
The Gack System
The gack system starts its day by attempting to match the stack trace of your gack up against other known gacks. Every stack trace will be slightly different, but gacks caused by a common problem usually have the same basic stack trace. When the system finds close matches, it aggregates each unique event with a common stack trace. This reduces the set of all individual gack events into a consolidated list of distinct problems that need to be fixed.
When a unique stack trace has been identified, a bug is logged. If your gack was the first of its kind, the bug is logged based on it. If your gack has the same stack trace as a previously encountered gack, it is attached to that gack and the bug that was generated by it.
The next trick the gack system does is attempting to assign the unique events to the team responsible for the missing error handling. It does a pretty good job of this, all things considered.
These capabilities allow our teams to be notified when we caused you see that ugly screen. Before you even have a chance to contact Customer Support, we already have a bug on our plate to fix.
Help Me Help You
Just because we know that a gack has occurred does not mean that we have any idea how it occurred. Often, with nothing but the stack trace, our team of reverse engineers can reverse-engineer the user flow that caused the gack. Developers can frequently figure out what is wrong simply by looking at the stack trace.
Often, though, we cannot determine how the gack happened. In these situations, we can use your help.
When you see a gack error screen or message, please take note of how you arrived at the situation. Any information you can provide is useful. If you can reliably reproduce the issue, that’s the most useful information of all.
There are a couple of ways you can get your noted details to our internal R&D teams. If you have a case logged with Customer Support, you can feed this context information there. When your case is linked with the bug in our system, we’ll have access to your input. Be sure to mention in your comments that you are providing information that will allow us to reproduce the gack.
Another way is to post your experience on Stack Exchange. You can post the gack ID and stack trace ID, along with information on how it was that you encountered our lovely message. We will be able to find it there when doing our investigation.
This detail isn’t always necessary, since we can often find the problem ourselves. When we can’t, however, your information becomes very valuable to us in solving the problem you (and likely others) are encountering.
Not Lost In The Shuffle
There are times where we simply cannot find the cause of a gack. There are corner cases around atypical events, like server shutdowns and release boundaries; these gacks sometimes never appear again. Sometimes there are corner cases encountered once by you, but never again. In these cases, we end up closing gacks as “not reproducible”. This is a bit like closing our eyes and hoping the monsters go away; we try to do this only when, based on the details, we presume the monster will probably never return. (Because if a monster returns, you wouldn’t want to be sitting there with your eyes closed, amirite?)
If you continue to experience the problem, we cannot ignore it. The gack system makes sure we remain aware of gacks as long as they continue to occur. If a team has given up on a gack and closed the bug, and the gack appears again, a new bug is logged. This new bug is attached to the original, letting us know that the issue persists. In this way, we never lose track of a bug.
We do our best to provide a gack-free environment for your application to thrive and run free. When we make a mistake, we want to know about it so that we can continue to head towards that goal. The gack system helps us help you.