Data Science
The terms “data science,” “machine learning,” and “artificial intelligence” are often used interchangeably, but they don’t all mean the same thing.
Data science is a broad interdisciplinary field that uses automated, scientific methods to analyze large amounts of data and extract knowledge from that data. You can use these methods to:
- Train the predictive models that are central to machine learning and artificial intelligence
- Analyze, visualize, and transform the data fed into those models
- Analyze the health and performance of models in production
Artificial intelligence (AI) is an umbrella term that refers to teaching computers to perform complex tasks. The use of AI ranges from chatbots that field simple customer support questions to self-driving cars that intelligently navigate real-world traffic.
AI behaves “like a human.” It can take complex, unpredictable input and respond with complex output that gives the appearance of agency. Often AI deals with the environment it’s placed in and makes various complicated decisions. Robots who play chess and the personal assistant on your phone? Those are examples of AI.
Machine learning is a technique that takes in data and produces a refined, specific type of output. Machine learning helps a computer “learn” from examples without being explicitly programmed with step-by-step instructions. Unlike AI, which typically responds to a diverse stream of inputs and outputs, machine-learning algorithms are geared toward answering a single type of question well. We don’t expect these algorithms to perform exactly like humans. In fact, we generally expect them to answer certain questions better than a human. For that reason, machine-learning algorithms are at the forefront of efforts to diagnose diseases, predict stock market trends, and recommend music.
Machine-learning techniques can help create AI, but the techniques aren’t sophisticated enough to constitute AI on their own. They can recognize and tag people in your photos or let your navigation app predict how long it takes to drive home at rush hour. In these examples, a computer takes in data, such as images that you already tagged of your friends or information from other drivers about how fast traffic is moving on the roads you need to take at 5 PM, and produces a specific output.
Data science, artificial intelligence, and machine learning all overlap. A Venn diagram of these disciplines looks like this:
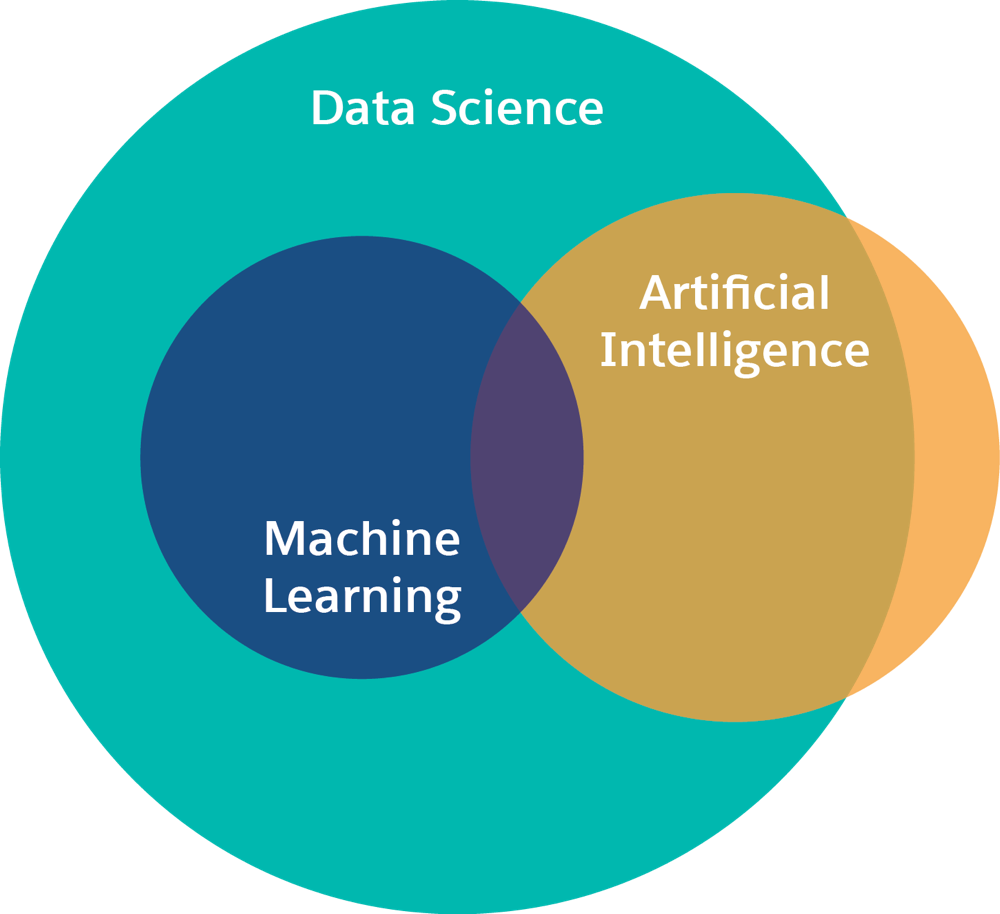
Deep learning is a type of machine learning. In deep learning, you create and train a neural network in a specific way. A neural network is a set of algorithms designed to recognize patterns. In deep learning, the neural network has multiple layers. At the top layer, the network trains on a specific set of features and then sends that information to the next layer. The network takes that information, combines it with other features and passes it to the next layer, and so on.
Deep learning has increased in popularity because it has proven to outperform other methodologies for machine learning. Due to the advancement of distributed compute resources and businesses generating an influx of image, text, and voice data, deep learning can deliver insights that weren’t previously possible.
Unlike a traditional program, where every instruction for the computer to follow is laid out explicitly, step by step, machine learning lets the computer build its own steps. It does this by using data to build a model.
A wide variety of machine learning algorithms are available, each suited to performing a specific task. For each machine learning task, a data scientist selects the right generic algorithm and chooses the right kind of data to feed into it. The algorithm looks for patterns in the data that map the input data to the desired output. Then the algorithm uses those patterns to build a mathematical model that describes the data.
For example, say you’re designing a trip-planning app that helps consumers find the best time to buy a cheap plane ticket. First, you train a model to predict when airlines have the lowest price for a specific itinerary, given historical data on ticket pricing for the route, holidays, departure time, and how long in advance you buy the ticket. The model uses results from the past to predict what is likely to happen in the future.
Then, when a customer enters the desired travel dates and route, you feed the model information about what the customer needs and get suggestions back about when the tickets are cheapest. Over time, you continue feeding data to the model, which adjusts itself, improving its suggestions as its dataset (and therefore its knowledge about pricing trends) grows.
At a high level, designing a machine-learning solution involves these four steps.
-
Identify the outcome you want. For example, say that you own a clothing store. You want to bring in the maximum revenue from sales of your clothing. This outcome is the output of your algorithm.
-
Identify your inputs. Often, these inputs are the “levers” that affect your outcome. For the revenue of a clothing store, that can include price and in-store promotions. These items are the input for your algorithm.
-
Build a model that connects the input that you can control to the outcome you want. You can see how changes you make to your input affect the outcome. For example, you can see how changing the price for your products (inputs) affects your revenue (the outcome).
-
Optimize. Use your model to search for and find the best inputs to achieve the outcome you want.
You can use this basic blueprint to design machine-learning solutions for a wide range of problems, such as:
- Web search ranking
- Autocomplete features
- Credit card fraud detection
- Address or handwriting recognition
- Voice assistants
- Language translation
- Autonomous navigation (robotic vacuums, self-driving cars, space exploration vehicles)
- Targeted ads based on your online activity
- Facial recognition
- Automatic product recommendations
- Medical diagnostics
- Spam filtering
Data scientists use machine-learning models to extract information from data. But where do those models come from? A computer builds a model by taking a generic machine-learning algorithm and feeding it a set of training data. There are many machine-learning algorithms, and the broadest way to categorize them is by learning style.
The two major learning styles are supervised and unsupervised.
The learning style of an algorithm has to do with the kind of data it uses to create a model.
A supervised algorithm takes input data called “training data,” which has a known label or result. A data scientist knows what results this training data produces and can compare those known results to the actual results of the model and correct the model until it’s accurate.
For example, if you want a supervised algorithm to produce a model that can identify pictures with cats, you feed it a set of labeled data containing pictures with cats and pictures without them. Because the data is labeled and you know which pictures are in each category, you can adjust the model until it reliably identifies which pictures contain cats and which don’t.
An unsupervised algorithm takes in unlabeled data and creates a model by looking for patterns in that data. It can look for general patterns or rules in the data, or it can organize the data into groupings by similarity.
For example, you can use an unsupervised model to examine customer data, such as purchase history and demographics, to categorize similar customers for specific marketing campaigns.
You can also think about supervised and unsupervised models as either predictive or descriptive. A supervised model is usually predictive: It uses existing data to build a model that you can use to predict what can happen under specific conditions in the future. For example, a predictive model can predict whether changing prices increases sales and revenue.
An unsupervised model is usually descriptive: It takes existing data and describes it by examining the rules and patterns in the data and categorizing or arranging it. For example, a descriptive model can tell you what kinds of customers you have by grouping them into segments based on age or spending habits.
Both Einstein Vision and Einstein Language use supervised algorithms. Therefore, the models they create are predictive.
Machine-learning problems typically fall into four functional groups: classification, clustering, regression, and dimensionality reduction.
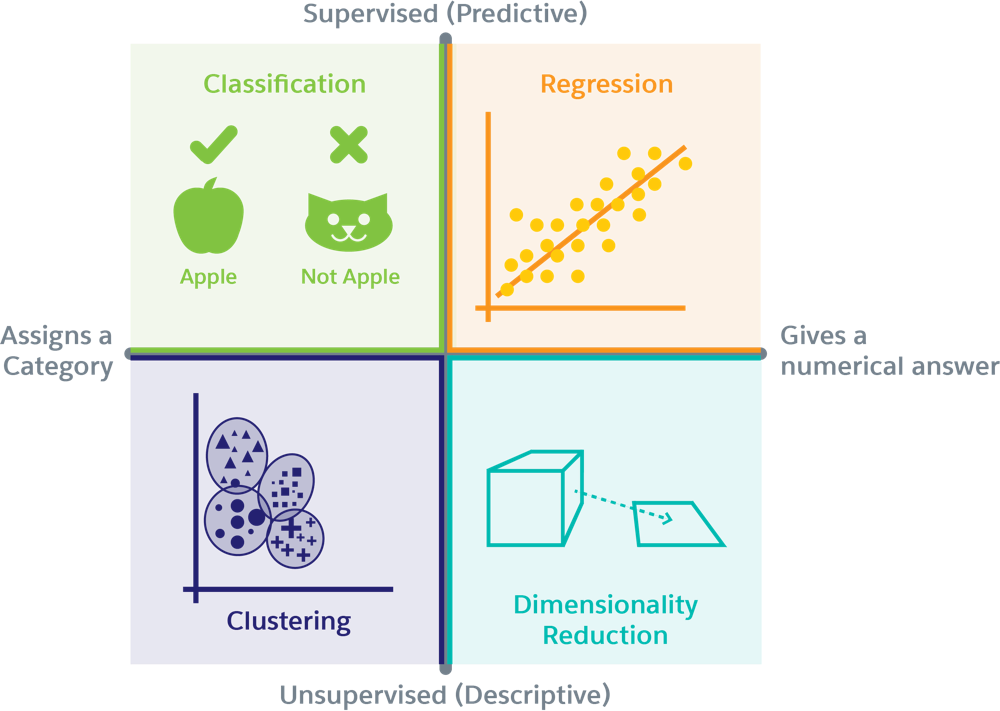
We’ll focus on classification, because Einstein Vision and Language builds classification models. A classification algorithm sorts data into categories and gives a result that’s a label, for example, “cat” or “not a cat.” Because a classification algorithm is supervised, you train it with a set of labeled data. Then you can check the accuracy of the resulting model against that data.
The world of AI and deep learning has introduced many new terms. Understanding these terms and how they relate to each other makes it easier to work with Einstein Vision and Einstein Language.
-
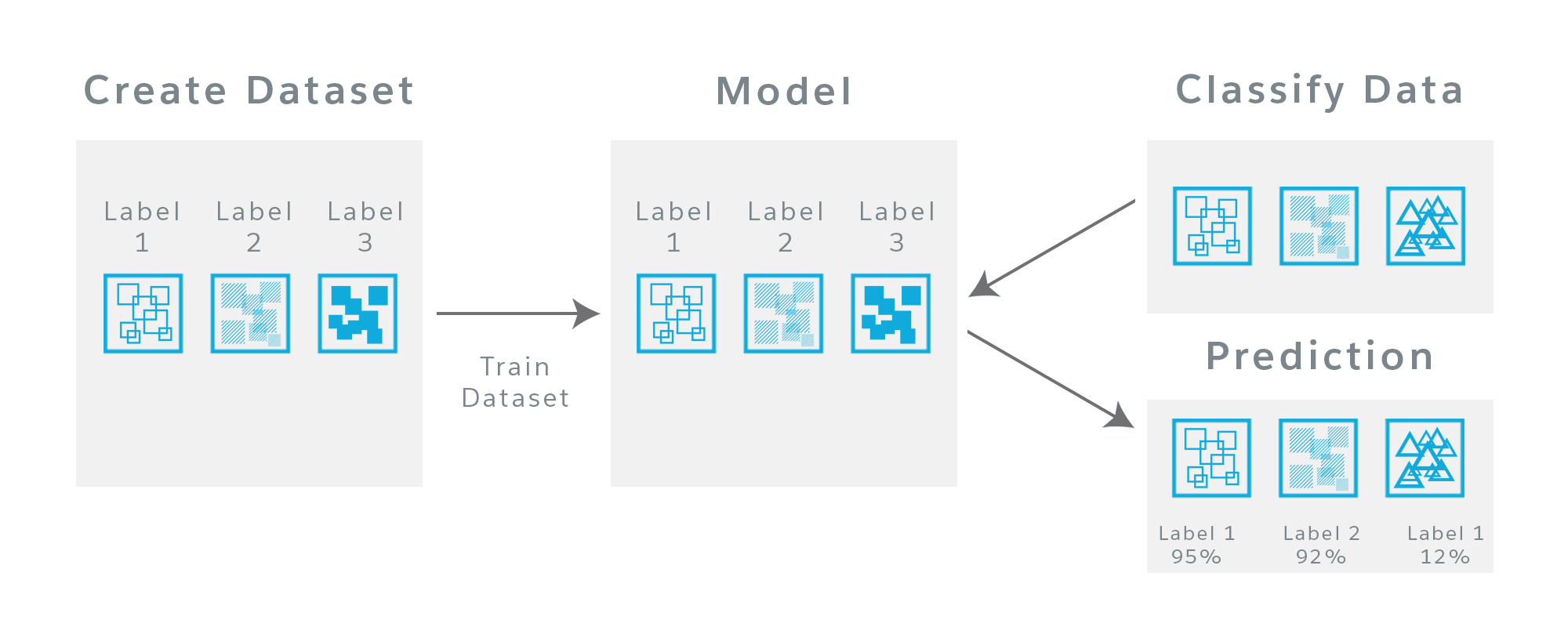
Dataset—Contains the training data. The dataset is the starting point for an Einstein Vision or Language implementation because it contains the data from which the model is created. After you gather your data, whether it’s images or text, you use that data to create the dataset.
-
Label (Class)—A group of similar data inputs in a dataset that your model is trained to recognize. A label references the output name you want your model to predict. For example, the food classifier, which is trained from a multi-label dataset, contains labels like chocolate cake, pasta, carrots, and so on.
-
Example—A single occurrence or piece of data. For Einstein Vision, an example is an image. For Einstein Language, an example is a text string. Because the learning is supervised, each example is given a label.
-
Training—The process by which a model is created. A dataset is trained, and the result is a new model.
-
Model—A machine-learning construct used to solve a classification problem. When you send in images or text, the model returns the prediction.
-
Prediction—The results that the model returns as to how closely the input matches data in the dataset.
-
Model metrics—Provides a picture of model accuracy and how well the model will perform. Metrics include elements such as the f1 score, confusion matrix, accuracy of the test data, and accuracy of the training data.
- Blog series: Machine Learning is Fun!