Dataset Training and Retraining
The training and retraining processes both create a model, but they are slightly different. There are different cases when you want to use train or retrain, and this content helps you understand when and why to use each method.
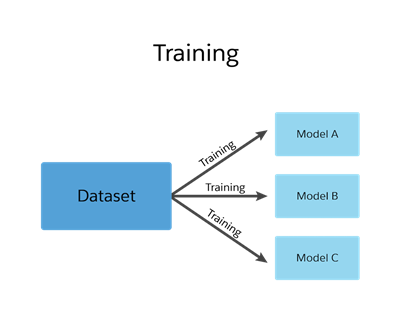
Training is the process by which a model is created from your data (a dataset). In the training process, algorithms are combined with your data to create the object that returns predictions.
Each time you call /train to train a dataset, it creates another model with a different model ID. Creating a separate model each time you train a dataset is helpful because you can compare them and then test and refine your models.
For example, you train dataset A, create a model, and find that the model doesn’t perform to the level you expect. So you add some data to the dataset and train that dataset to create a new model. You can still access the previous model to compare the accuracy and other metrics as you iterate through the process.
Here are some considerations to keep in mind when you train a dataset.
-
When you call
/train, it creates a new model with a new model ID. -
If you decide to use the new model, you must update the model ID in existing code or tools that reference the model ID.
-
Creating multiple models enables you to compare models as you change your dataset.
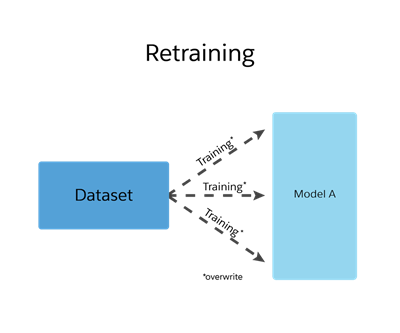
Retraining works differently. When you call /retrain to train a dataset, it references the dataset used to create an existing model. This method overwrites the old model with the new model, but it retains the previous model ID.
For example, you train a dataset, create a model, and iterate through the process. You have an accurate model that you use in your apps. Due to changes in your business, you need to include more data in your model.
Here are some considerations to keep in mind when you retrain a dataset.
-
Retraining overwrites the existing model, but maintains the model ID.
-
If you retrain using bad or incorrect data, the model is corrupted. You can’t recover the older version.
-
Because retraining keeps the original model ID, you don’t need to update references to the model ID. Your existing code and tools use the new model.
-
You must explicitly retrain a dataset when you want to update model. Retraining doesn’t occur automatically.