Detect Text and Tables
Some images contain tabular data. To return the table data for each text element, specify the tabulatev2 model and a task parameter value of table.
The cURL call looks like this.
The response looks like this JSON.
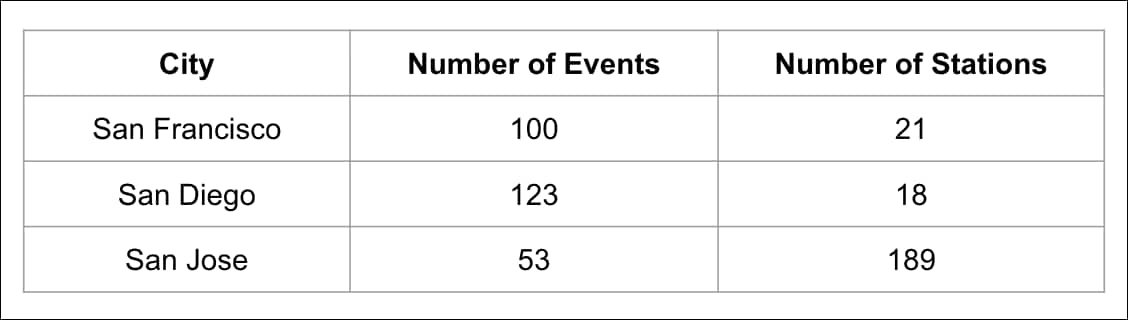
The above JSON describes Einstein’s detection of the table elements, and is depicted below:
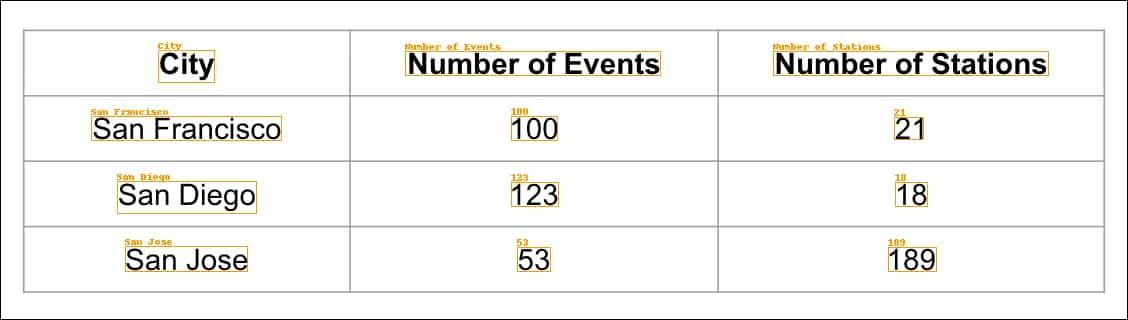
When an image contains more than one table, Einstein returns tabular data for each table in the image. The following image depicts how the tables and fields are denoted in the JSON. (The JSON is not provided). With this example, three tables are identified: One 3x2, one 2x5, and one 2x2. The values in the second row of the 2x2 table cells will be identified separately, resulting in a 2x6 JSON table definition.
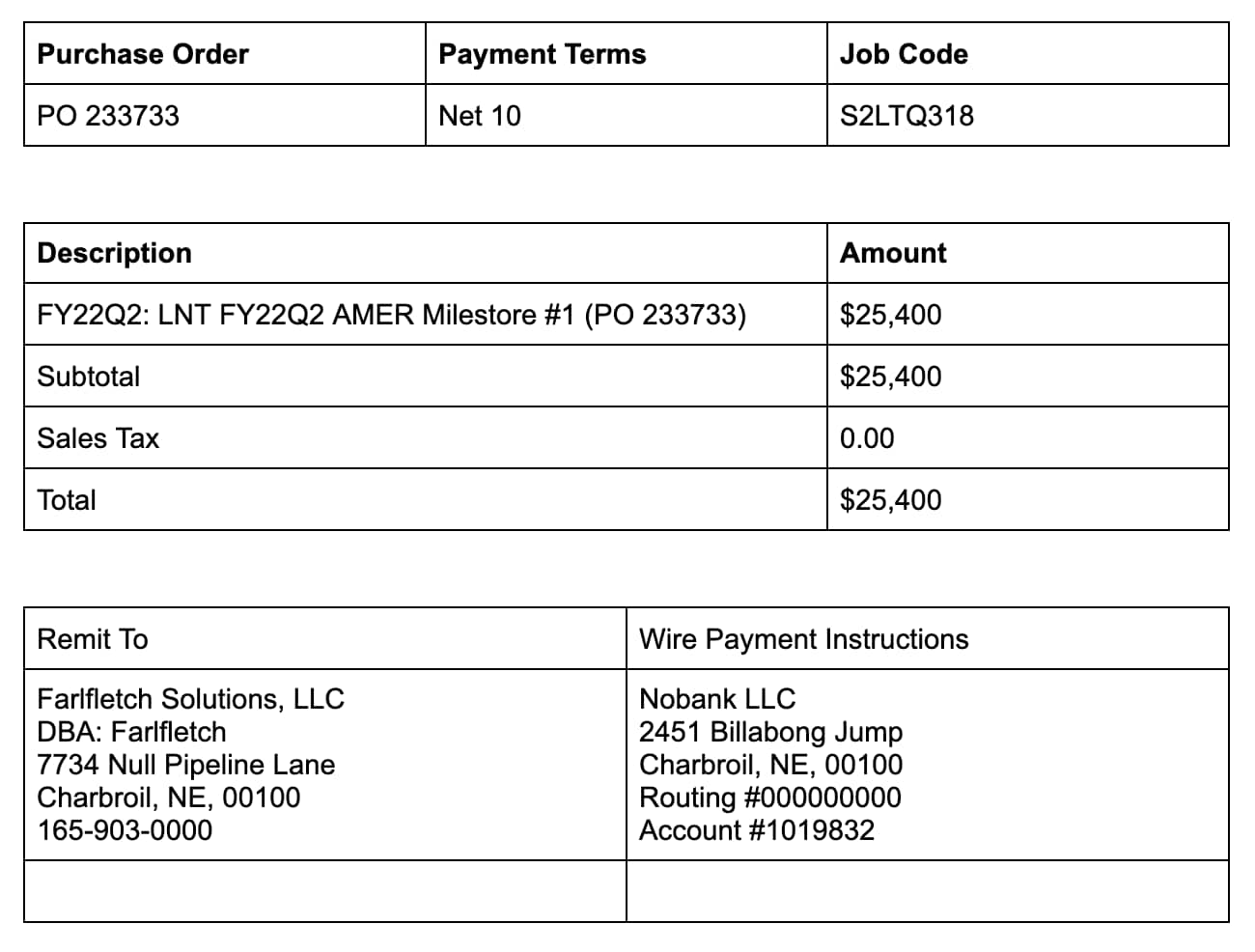
We currently support only the content confined within the individual tables. Free text in the image which lies outside of a table border is not processed.