Data Fetching
Storefront Next is built on React Router, leveraging its Framework Mode to provide a structured foundation for routing and data handling. As such, Storefront Next represents a server-rendered single-page application (SPA). This application model means that only the initial navigation request to a route is processed and responded to by the server. All subsequent client-side navigation requests are routed on the client and only trigger requests for data or additionally required assets, or both. Server-side rendering (SSR) ensures fast initial load times while client-side navigation and rendering (CSR) eliminates full page reloads after hydration, combining the strengths of SSR and CSR without their respective tradeoffs.
Storefront Next uses these data loading components:
- Loaders: Server-side functions that fetch data before component rendering.
- Actions: Server-side functions that handle data mutations triggered by form submissions or programmatic calls.
- Fetchers: Client-side functions that enable loading data from or submitting data to routes without causing navigation. Fetchers can call loaders (for reads) or actions (for writes) on any route, making them ideal for in-page interactions.
- Middlewares: Functions that run in a pipeline before loaders and actions and allow intercepting navigation requests before a route renders.
- Cookies and Sessions: Server-side mechanisms for persisting state across requests, such as user preferences, authentication tokens, and flash messages.
| Package | Version | Purpose |
|---|---|---|
react-router | 7.12.0 | Framework mode with loaders, middlewares, actions |
react | 19.2.0 | React 19 with use() hook |
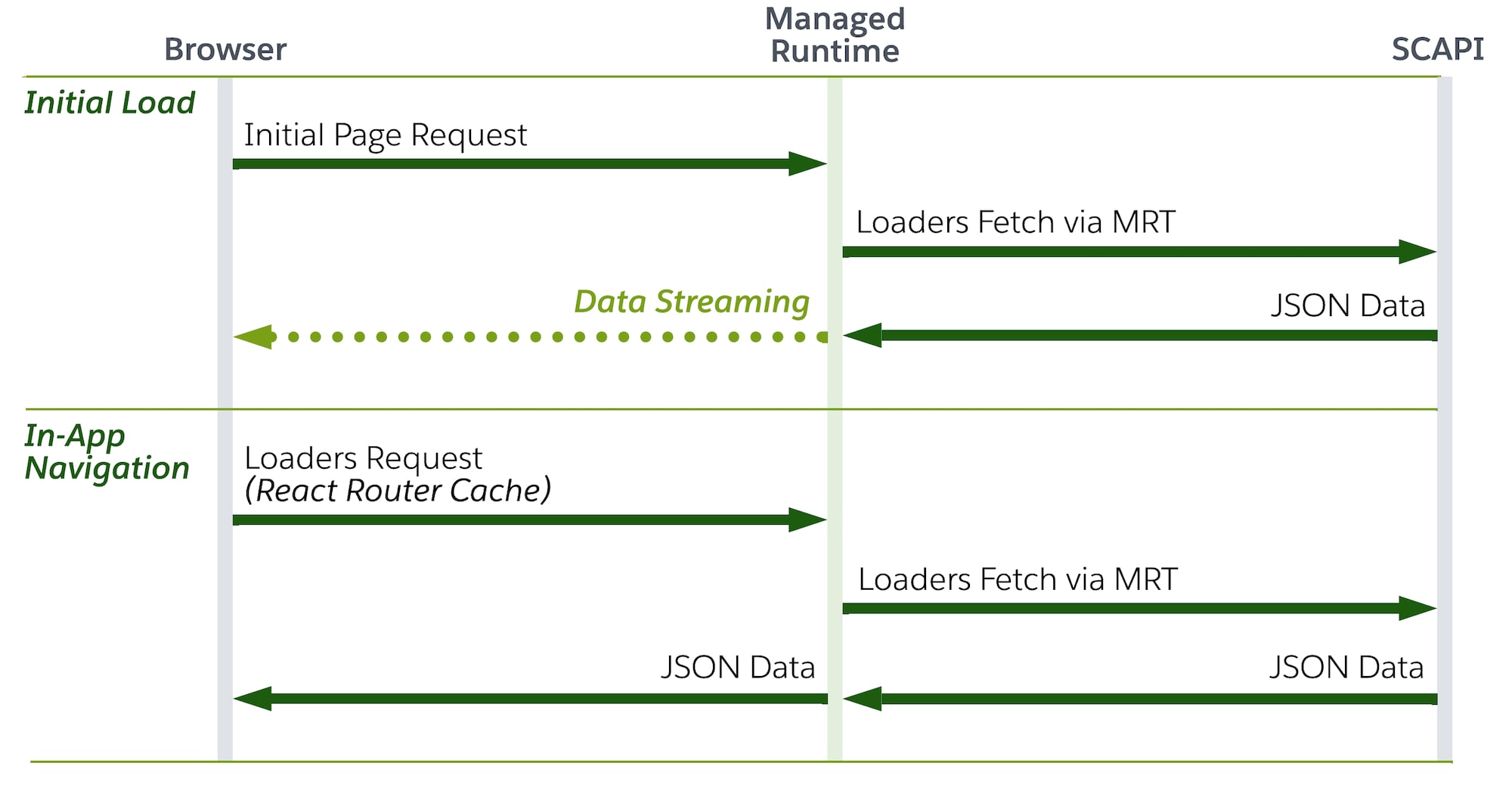
One of the many strengths of React Router lies in its highly flexible mechanisms for controlling and calibrating data retrieval and data flows within an app. While it’s technically possible to implement complex, server/client-segregated data flows, we made the deliberate architectural decision for Storefront Next to promote a server-load everything paradigm.
In our proposed architecture, Managed Runtime (MRT) isn’t only used as a simple data proxy, but acts as the data orchestration layer. Using React Router’s server data loading functionality, we’re able to aggregate parallel and sequential SCAPI requests into a single request to MRT and progressively stream the response to the client. This ultimately means that all API requests are executed on the server (that is, MRT).
A solid understanding of this paradigm is suggested, as it directly impacts the structure and bundling of the app code, as well as overarching aspects such as performance, authentication, security, and SEO.
In Storefront Next, we promote route-level data fetching via loaders, as they are the only mechanism that guarantees data is fetched before component rendering on the server.
Component-level data fetching (for example, useEffect or direct fetch calls within components) isn’t recommended for initial page loads, as data is absent during SSR, resulting in degraded SEO and slower perceived performance. All of these client-side data fetching strategies should only be considered for interaction-driven data scenarios.
Another pillar of an effective data fetching strategy is classifying data by its route-level relevance. This strategy requires answering three questions per route.
- What data must be available before the route renders? (Blocking data, critical for SEO, and typically desirable for above-the-fold content.)
- What data can be deferred? (Streamed data, below-the-fold content, but also negotiable for above-the-fold content in case of visually stable content/layouts.)
- What data is interaction-driven? (Outside the initial data fetching lifecycle; fetched on user action.)
Critical data comprises all information required to produce a complete, semantically correct, and layout-stable initial HTML response. This data includes above-the-fold content that determines Largest Contentful Paint (LCP), layout-defining attributes such as image dimensions that affect Cumulative Layout Shift (CLS), and all SEO-relevant artifacts such as accurate title, meta description, canonical links, structured data, and correct HTTP status codes (for example, 200, 301, 404), and so on. It also includes any data necessary to render the correct document state for crawlers and social previews. Data is considered critical if its absence delays meaningful paint, changes initial layout, misrepresents document semantics, or produces an incorrect status code.
Non-critical data comprises information that doesn’t affect initial render completeness, layout stability, document semantics, or HTTP correctness. It doesn’t negatively impact loading metrics like LCP, or the visual stability of the above-the-fold structure, and isn’t required for accurate indexing or link previews. This category includes below-the-fold content, related items, recommendations, progressive personalization, analytics payloads, and enrichment UI elements. Such data can be deferred, streamed, or lazy-loaded without compromising performance metrics, crawlability, or document validity. Learn more about visual stability here.
Interaction-driven data is fetched in response to user actions, such as clicking a button, submitting a form, or triggering other UI interactions. Unlike route-level data fetching that occurs during navigation, interaction-driven data is requested after the initial page render.
The React Router framework provides loaders for data fetching and actions for interaction-driven data mutations, with middlewares handling cross-cutting concerns (for example, authentication, logging, caching), and fetchers enabling interaction-driven data updates without navigation.
Loaders are exported functions in route modules that fetch data before (or during) the component tree renders.
The return value of a loader function is a record whose key–value pairs represent discrete data fragments that the route consumes. Alternatively, a Promise resolving to such a record can be returned. The framework transparently awaits such outer Promise.
The individual values within the returned record can themselves be either concrete values or Promises. In React Router, unresolved Promises inside the returned object are handled natively and can be consumed in combination with React <Suspense/>.
This enables fine-grained control over rendering behavior by separating:
- Critical Data: values awaited within the loader before returning the object.
- Non-Critical Data: Promises returned as values, resolved later and rendered within
<Suspense/>boundaries.
| Argument | Type | Description |
|---|---|---|
request | Request | Standard Fetch API Request object. |
params | Object | Route parameters from URL. |
context | RouterContextProvider | Shared context from middleware. |
While React Router also provides the concept of client loaders, we recommend the consistent use of server loaders in accordance with our server-load everything paradigm. Server loaders get invoked during server-side rendering (SSR), but also to fetch data during subsequent client-side navigation requests.
Server loaders offer several advantages and enhancements:
- Security can be enhanced by keeping API credentials and sensitive business logic server-side, never exposing them to the client bundle. Additionally, server loaders enable direct access to backend services, databases, and internal APIs without CORS concerns or public endpoint exposure.
- Perceived performance can benefit from server-side rendering as Core Web Vitals metrics like LCP (Largest Contentful Paint) and TTI (Time to Interactive) can improve significantly by delivering pre-rendered HTML. CLS (Cumulative Layout Shift) improvements require explicit layout stability measures like reserved space for dynamic content (for example, via skeletons).
- Client bundle size can remain minimal since data fetching code and dependencies don’t have to get shipped to the browser if kept out of the client module graph.
- SEO can benefit from fully-rendered HTML with data already present in the initial response, enabling bots to crawl complete content without having to execute JavaScript. Dynamic meta tags (title, description, Open Graph) can be populated with actual data, improving social sharing.
This code example shows how to fetch all data for a specific route before the component for that route renders. It initiates two separate data fetches to external APIs using the standard fetch API. The function returns an object containing the two resolved data portions.
When a requested resource doesn’t exist, returning a proper 404 HTTP status code is critical for SEO. Search engines distinguish between valid pages and missing content to maintain accurate indexes and avoid crawl budget waste.
This code example shows how to throw a 404 response when a product isn’t found. The thrown Response is caught by the framework and returned with the correct HTTP status code, ensuring search engines and social media crawlers receive proper signals.
Always throw a Response with a non-200 status code rather than returning error data with a 200 status code. Throwing this response ensures search engines correctly understand the page state and prevents indexing of non-existent content. The thrown Response will be caught and handled by the closest ErrorBoundary in your route hierarchy catches and handles the thrown Response, enabling you to render custom 404 pages.
React Router awaits route loaders before rendering route components. To unblock the loader for non-critical data, simply return a Promise instead of awaiting it in the loader.
Non-critical data enables progressive rendering by prioritizing above-the-fold content while deferring below-the-fold elements. This improves perceived performance by showing users meaningful content faster, reducing time-to-interactive. For SEO, critical data like product titles and descriptions are immediately available in the initial HTML, while supplementary content like reviews or recommendations can stream in afterward. This pattern optimizes the balance between fast initial page loads and comprehensive content delivery.
This code example defines a loader that demonstrates both data deferral and Promise chaining. The goal is to maximize performance by initiating fast and independent fetches immediately, while organizing dependent fetches to run as soon as their prerequisite data is available.
Components receive loader data and can either use React 19’s use() hook or React Router’s <Await/> component to unwrap promises. This code example shows how to consume critical and non-critical data loaded by the data loader from the previous example. The component waits for the critical data to resolve, then renders the main content, for example, product name and description. Secondary data is rendered within <Suspense> boundaries, enabling us to influence the loading state of any promises that suspend within it.
You can also use the useLoaderData hook to retrieve the data.
For details on how loader data integrates with the broader state model, including useLoaderData, useRouteLoaderData, and middleware context as state, see State Management. For visual feedback during data loading, see Loading States.
SCAPI endpoints expose several knobs that control response size and cacheability, such as expand, select, limit/offset, and similar query parameters. Treat these as part of the loader’s contract, not as defaults to copy from another route. Two side effects are easy to overlook:
- Payload size. Every requested field crosses the network and lands in the SSR response. Over-fetching adds bytes to TTFB, inflates the streamed HTML, and increases hydration cost. Audit each loader and ask which fields the route actually renders. Drop the rest.
- Cache TTL. SCAPI caches responses per unique request URL, including the full query string. Adding or removing a parameter creates a separate cache entry. More importantly, fields with shorter TTLs (for example, real-time inventory or pricing) pull the entire cached response onto their shorter schedule when included inline. Prefer fetching short-TTL data separately via a non-critical deferred loader rather than mixing it into critical, long-cacheable payloads. See Expand Parameter Impact on Cache Hit Rates for the underlying caching behavior.
Action functions handle data mutations, such as form submissions, updates, or deletions, the counterpart to loaders. While loaders handle read operations, actions handle writes. A GET/POST/PUT/DELETE distinction is a useful mental model, though React Router routes requests by navigation intent rather than HTTP method alone.
| Argument | Type | Description |
|---|---|---|
request | Request | Standard Fetch API Request object. |
params | Object | Route parameters from URL. |
context | RouterContextProvider | Shared context from middleware. |
Comparable to server loaders, React Router also provides the concept of client actions. In line with our server-load everything paradigm, we recommend server actions exclusively. Server actions are functions that execute solely on the server, ensuring sensitive mutation logic, such as database writes or authentication checks, never reaches the client.
Always return data(payload, init?) from react-router — never Response.json(...). This:
- Preserves the HTTP status code so CDNs, server logs, and client-side
fetcher.formMethodchecks behave correctly. - Keeps the payload type inferable, so consumers can use
useFetcher<typeof action>()and get full type-safe access tofetcher.data.
Annotate every action with an explicit return type so the contract is enforced at the action definition (not just at the caller):
Consumers then bind the fetcher to the action:
For an action that may dispatch to one of several routes (for example, a single fetcher submitting to add/remove/update endpoints), use a union: useFetcher<typeof addAction | typeof removeAction>().
This example demonstrates interaction-driven form submission with validation and error handling via an action function.
For details on how action return values integrate with the state model (optimistic UI, fetcher.data, useActionState), see State Management.
Fetchers are React Router’s mechanism for triggering loaders or actions outside of navigation, enabling data fetches and mutations without changing the current route or URL. Unlike standard navigation, multiple fetchers can run concurrently and independently, each tracking their own submission state. This makes them well-suited for use cases such as inline form submissions, optimistic UI updates, or background data refreshes.
This example demonstrates the same interaction-driven form processing as the previous example, but this time using a fetcher (via the useFetcher hook).
For details on how fetcher.state and fetcher.data integrate with the state model, see State Management. For visual feedback patterns based on fetcher.state, see Loading States.
Resource routes are specialized routes that don’t render UI components but instead function as API endpoints within your app. Unlike traditional UI routes that export both a loader/action and a component, resource routes typically export only loaders, actions, or both. This makes them ideal for encapsulating server-side business logic that can be called from anywhere in your app.
Resource routes bridge the gap between loaders and actions by providing a dedicated location for reusable data operations. They leverage the same loader and action patterns you’ve learned, but organize them as callable endpoints rather than navigation destinations.
Resource routes are particularly useful for:
- Encapsulated business logic: Complex operations that benefit from being isolated in dedicated route modules, such as basket management, wishlist operations, or multi-step workflows
- Reusable endpoints: Data operations that multiple components across different routes need to access without duplicating code
- Non-navigational mutations: Actions that modify data but shouldn’t trigger navigation, such as adding items to basket, toggling favorites, or updating preferences
- Direct SCAPI calls: Generic API proxy routes (for example,
resource/api/client/*) that forward requests to SCAPI without requiring SCAPI client libraries on the client
Resource routes follow the same patterns as regular routes but typically don’t export a default component. They can be prefixed with resource/ to distinguish them from UI routes.
In this example, we bring together the concepts of actions and fetchers alongside the previous form-processing examples. Using Resource Routes enables a more decoupled component architecture.
This example shows a resource route that encapsulates complex business logic for adding items to a shopping basket.
For direct API calls without client-side API libraries, you can use a generic proxy route pattern.
React Router middleware consists of functions that intercept navigation requests before a route renders, enabling cross-cutting concerns, such as authentication, redirects, or logging, to be applied declaratively at the routing layer, upstream of loaders and actions.
This code example defines a logging middleware function named loggingMiddleware. It’s designed to run before any route loaders or other middleware in the chain, specifically to log request information and measure response times.
Middlewares can store data in a shared context, which loaders and actions can access. The following code example shows this fundamental pattern. It uses the createContext utility provided by React Router to establish a communication channel that bypasses global state or complex dependency injection.
For details on how middleware context functions as a state concept (request-scoped dependency injection vs. React Context API), see State Management.
Cookies and sessions are React Router’s built-in mechanism for state that must persist across requests. Examples include user preferences (theme, locale, dismissed banners), shopping cart identifiers, and authentication tokens. Cookies and sessions integrate directly with the loader/action lifecycle: cookies are read from the incoming Cookie header in loaders and actions, and written via Set-Cookie response headers. Because cookies travel with every HTTP request, they’re available on the server during SSR without client-side synchronization, localStorage workarounds, or hydration mismatches.
createCookie defines a reusable, typed cookie object with sensible defaults for attributes like httpOnly, sameSite, and maxAge. The cookie is read in a loader and written in an action.
This pattern reads the cookie server-side in the loader (no useEffect, no SSR mismatch), writes it via the action with a Set-Cookie header, and triggers automatic revalidation so the UI reflects the new state immediately.
For structured, server-managed state, such as authentication tokens or multi-field user profiles, React Router provides createCookieSessionStorage. A session storage object wraps cookie handling with getSession, commitSession, and destroySession helpers.
Sessions support flash data, values that exist only until the next read. That’s useful for one-time messages like “Login successful” or validation errors across redirects.
Cookies and sessions combine naturally with middleware context. Rather than having every loader parse the session independently, a middleware can resolve the session once and inject it into the context. All downstream loaders and actions then access the pre-parsed session without repeating the boilerplate.
This eliminates duplicated session-parsing logic across routes and centralizes the commitSession call. The middleware owns the session lifecycle, loaders and actions simply read and write session data.
For details on how cookies and sessions fit into the broader state model alongside URL state, middleware context, and React primitives, see State Management.
By default, React Router automatically revalidates (re-executes) loaders after navigation events, form submissions, and actions to ensure data stays fresh. While this default behavior guarantees data consistency, it can lead to unnecessary network requests and degraded performance in scenarios where data hasn’t actually changed.
A shouldRevalidate function exported at the route level gives you fine-grained control over when a route’s loader should re-execute, enabling you to optimize performance by preventing redundant data fetching while maintaining data freshness where it matters.
This example shows a product listing page where query parameters control filters. The example uses the category, price range, and sort order query parameters. Because the loader already uses these query parameters to fetch filtered results, we don’t need to revalidate when only the URL search parameters change. The loader naturally fetches the correct data on the next navigation.
When your loader consumes URL search parameters to fetch data, returning false for query parameter changes prevents double-fetching. The loader executes with the new parameters on the next navigation anyway.