Code Analyzer Architecture (Retired)
Code Analyzer is an open-source Salesforce CLI plug-in. Most of the code is written in TypeScript in the Node.js framework, and some is written in Java. Code Analyzer is powered by multiple static analyzers, also known as rule engines, and by Salesforce Graph Engine
Code Analyzer engines specialize in different aspects of static analysis and support multiple languages. Each rule engine has its own unique set of rules, input parameters, and formats for reporting the results. Code Analyzer unifies these rules engines as a single static analyzer and provides a common user experience.
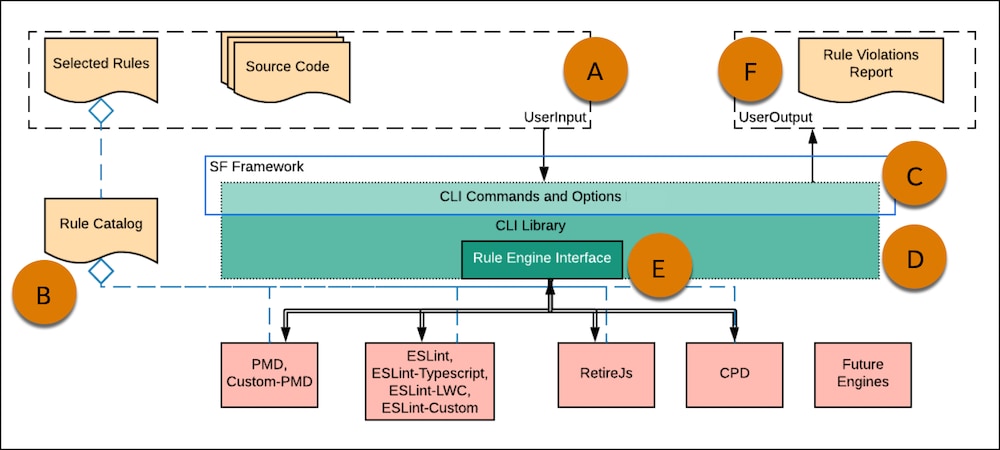
To scan code with Code Analyzer, users provide their source code and select rules to run (A) from the rule catalog (B).
Next, CLI Commands and Options (C ) accept a user’s source code for analysis and the selected rules and parameters to apply to each scan.
CLI Commands and Options:
- are built on the Salesforce framework
- pass the scan information to the CLI Library (D)
The CLI Library contains the Rule Engine Interface (E) that extends to the included engines in the backend:
- PMD, including Custom-PMD
- Eslint, including Eslint-Typescript, Eslint-LWC, Eslint-Custom
- RetireJS
- CPD
- Graph Engine
When the CLI Library receives the scan parameters, it executes the relevant engines based on the file types in the provided source code and in the selected rules.
After the Code Analyzer execution completes, it collects violations and passes them back to the CLI Commands and Options. Finally, CLI Commands and Options constructs a Rule Violations Report (F) as user output.
To provide a consistent experience while using multiple rule engines, Code Analyzer has two bridging blocks: a rule catalog and a rule engine bridge.
Each rule engine has a different set of rules and different formats for representing them. Code Analyzer communicates with each rule engine separately to pull the default rules that they offer and to populate them together into a rule catalog. This catalog contains the name of a rule, a short description, its classification category, and the code source language that the rule can analyze.
To view the rule catalog, run the scanner rule list command. The command’s output includes the rule-engine name that a particular rule belongs to, as shown in this example.
By unifying the representation of the rules into a rule catalog, Code Analyzer accepts a uniform set of input parameters. Here’s how it works.
- Using rules that you select, the bridge detects the related engine and determines the target files based on the file types defined in
~/.sfdx-scanner/{{ site.data.versions-v3.configfile }}. - Next, the bridge tailors the input for each relevant rule engine and hands the input to the rule engine for the actual scan.
- After the scan completes and the rule engine provides the results, the bridge surfaces the rule-violation results in a normalized output format.
The code for Code Analyzer is in the /forcedotcom/sfdx-scanner repo on GitHub. Salesforce is working on expanding and improving the tool.