This series is a Merit winner of the Society for Technical Communication’s Touchstone Award.
This article is part 1 of a series written by Sovan Bin from Odaseva. This series details Odaseva and Sovan’s experiences and best-practice recommendations for anyone working with enterprise backup and restore processes. For more information about backup and recovery see part 2, part 3, and part 4 of this series.
Data backup and restore is often considered a security topic. While this topic is indeed the first step to set up a disaster recovery plan, the technical challenges raised share common grounds with data migration, rollback strategy, sandbox data initialization or even continuous integration.
What are the possible roadblocks? Which Salesforce API would you use? What kind of speeds can you expect? How can you accelerate the process?
Why would you backup Salesforce data (including metadata)?
Salesforce performs real-time replication to disk at each data center, and near real-time data replication between the production data center and the disaster recovery center. However, there are many different reasons why a customer would like to organize their own backup of information from Salesforce. We could mention for example:
- Recover from data corruption (unintended user error or malicious activity)
- Prepare for a data migration rollback
- Archive data to reduce volumes
- Replicate data to a data warehouse/BI
- Take snapshots of development versions
What to backup and how?
There are two types of information you can backup from Salesforce: data and metadata.
Salesforce provides four APIs to backup data and metadata information from the application:
- REST API
- SOAP API
- Bulk API
- Metadata API
These APIs will allow you to set up either a full, incremental, or partial backup.
| Backup Type | Comments | Pros | Cons |
|---|---|---|---|
| Full | Contains all data | Contains all information that may be required | Can represent a large volume, takes more time to retrieve a subset of data and be reactive to handle a data incident |
| Incremental | Backup differences since last full backup (daily incremental backup, weekly, monthly, etc.), the data replication API is particularly adapted to this type of backup | Efficient for retrieving a change that took place on a specific date, smaller files that are easier to handle | May lack related information and take longer to rebuild a complete picture (merge full backup and last incremental backups) |
| Partial | Backup a subset of data (for example, closed cases only) | Efficient for retrieving a record from a subset of data, ideal approach for archiving purposes (i.e. records older than 5 years) | May lack related information |
You could implement, for example, a strategy mixing several backup types to optimize backup time and target business critical information. Your backup plan might look something like:
- Weekly full backup
- Daily incremental backup
- Monthly partial backup (Cases closed more than 3 years ago) for archive and delete
When choosing a backup method, you should also consider whether you want to use Salesforce native features (Weekly Data Export, Data Loader), build your own solution leveraging APIs, or use a dedicated AppExchange app. There are pros and cons to all of these, so consider the following factors:
Security
Any local backup should be properly guarded against security risks, which might involve encryption of local data or other security measures. When choosing a backup method, keep the following factors in mind to ensure your backup data is secure.
- File system storage (data location, disk capacity, redundancy, availability, durability, encryption of the data at rest, encryption key management, physical security access, authentication, access logs, and other security requirements)
- Backup and Restore server configuration, run and maintenance (availability, redundancy, encryption of data in transit, encryption of cached data, network/CPU/memory capacity, etc.)
- Backup archives retention (retain backups for a specific amount of time)
Restoration capability
Backup raises the important question of Restore. Keep the following topics in mind when addressing this requirement. We’ll be going into more details on restore capabilities in the next article of this series.
- Capability to quickly Restore a few records
- Capability to mass Restore and rebuild all relationships between objects
- Restore process and data quality
- Restore process and system integrations
- Restore process and automation (validation rules, workflows, triggers, etc.)
Fault tolerance and scalability
Regularly run backup solutions should be able to handle backup failures with minimal user interaction. Asynchronous solutions (for example, the Bulk API) have some basic fault tolerance built-in (automatic retries for failed records). If the following factors are important for your backup process, consider a solution that provides fault tolerance. We’ll go into more details on scalability later on in this article.
- Volumes (need for extreme data volumes strategy)
- Backup and Restore required stability & retry capacity
- Backup and Restore required degree of automation
- Backup monitoring and optimizing capacities
- Backup and Restore required performance (i.e. need for parallel processing)
Customization and automation
Some scenarios might require the ability to change specific ways the backup process works. Using Salesforce APIs gives you fine-grain control over the entire backup process. If the following factors are important for your backup process, consider a solution that provides maximum flexibility, like using Salesforce APIs.
- Backup and Restore scope (files, metadata, data)
- Backup automation frequency
- Need for Backup plan personalization (mix full backups and incremental backups, give higher priority to specific objects/fields/type of records, etc)
- Backup plan maintenance (environment change detection, support new Salesforce releases and API changes)
Next, we’ll start by looking into using APIs in your backup solution.
Which API should you pick?
If you opt to use Salesforce APIs for your backup solution, you’ll need to choose which API to use based on your backup use case. Some APIs (such as the Bulk API) are designed for bulk operations that can be performed asynchronously, while other APIs are designed for synchronous operations.
| Requirements | Recommended API | Explanation |
|---|---|---|
| You need to preserve governor limits regarding the number of API calls | Bulk | Bulk API does not consume API calls but consumes Bulk API calls, which are less restrictive |
| You need to preserve the governor limit regarding “number of batches per rolling 24 hour period” | REST or SOAP | REST or SOAP are not subject to Bulk-specific governor limits, however they have their own limits |
| You need to backup an object containing a large volume of records (i.e. more than 2M records) or do a backup that raises performance challenges | Bulk | Bulk API will generally be faster than the other APIs, but the REST or SOAP APIs might sometimes get better results depending on several factors: query batch size, current asynchronous load on the instance, degree of parallelization |
| You need to backup an object that is not yet supported by the Bulk API (i.e. CaseStatus, OpportunityStage, AcceptedEventRelation, etc) | REST or SOAP | Bulk API does not yet support all queryable objects in Spring `15 release |
| You need to backup an object that contains a lot of XML-like information (example: EmailMessage) | REST or Bulk | While this is not directly caused by the Salesforce SOAP API, we have seen some XML parsers encountering difficulties when processing the HTTP response (mix of XML-based protocol and XML data) |
| You need to backup metadata | Metadata | The Metadata API is by far the most exhaustive API to retrieve metadata, however a large part of the metadata is also available in the REST, SOAP and Tooling APIs |
| You need to back up files (Attachment, ContentVersion, Document, FeedItem, StaticResource, etc.) | REST or SOAP | The Bulk API does not yet support Base64 fields in Spring `15 release |
Backup performance matters
A full backup does not contain a WHERE clause by definition. Backup speed will thus depend on other factors than indexes, for example:
- Number of records (lines)
- Number of fields (columns)
- Type of fields (i.e. rich text fields are slower to backup than checkbox fields)
- Salesforce API selected
- Your network capacity
- Degree of parallelization
Ideally a backup should give a representation of the data at a certain point in time. However, while the backup is being performed, Salesforce data can be modified by users. The longer the backup process lasts, the more discrepancies you might get at the end of the process.
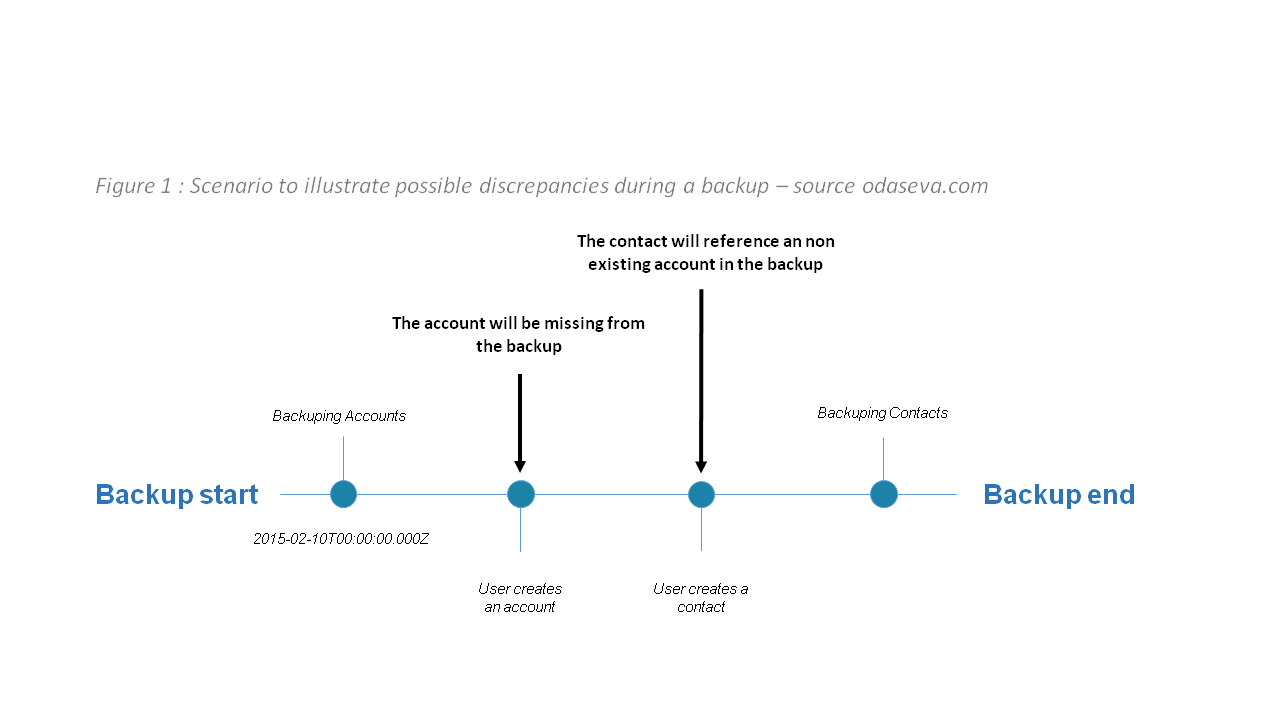
Note that in this example, a partial workaround would be to launch another incremental backup for accounts created/modified after 2015-02-10T00:00:00.000Z
Minimizing the time spent by the backup to reduce the probability of such discrepancies remains one of the best options — this is why performance is key in backing up.
Have you ever wondered how fast Salesforce APIs can go?

The following metrics were provided by odaseva.com, based on the backups of 12 billion records from Salesforce.
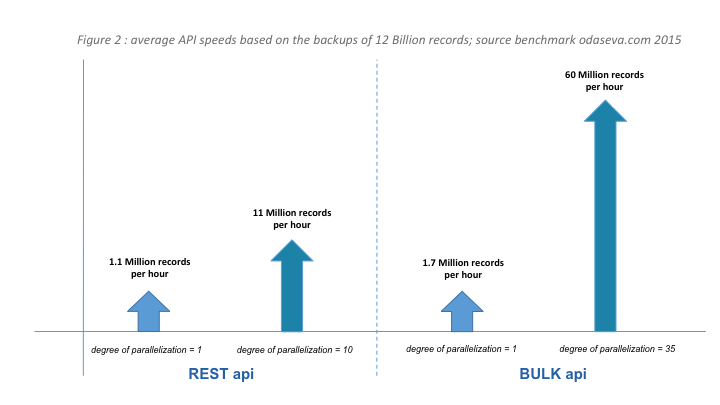
The degree of parallelization has been arbitrarily set to 10 for the REST API based on my personal projects experience. Going above 10 usually does not accelerate the process or raises new challenges (i.e. org limits). Similarly, we’re showing a degree of parallelization of 35 for Bulk API based on data from my projects. Note that this degree of parallelization comes from metrics from Salesforce servers with minimal load.
In general, when dealing with high data volumes, the Bulk API has better throughput and is more scalable than the REST API.
Some backup metrics coming from real life experience
Backup speed (data) can vary a lot depending on the number of columns of the different objects and the types of fields.
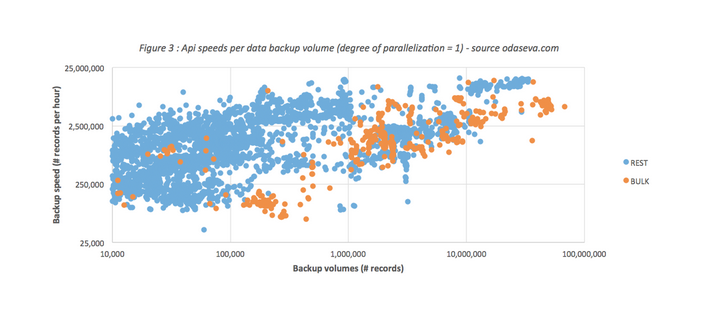
A backup of 9 million records containing less than ten fields (boolean and audit fields) even reached the impressive speed of 16.5M/h per unit of parallelization, which gives a theoretical speed of 577 million records per hour with a degree of parallelization of 35. Salesforce platform definitely has one foot in the future!
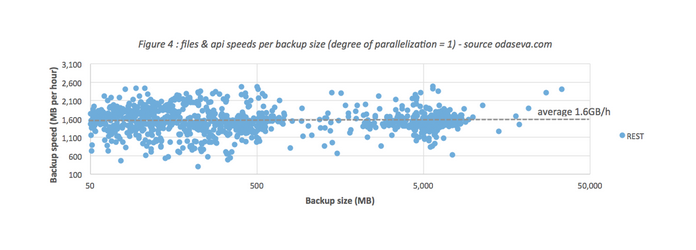
Backup speed regarding the files (Base64 fields) can vary a lot depending on the size of the files. It is much faster to backup one file of 2GB (~2.6GB per hour) than 2,000,000 files of 1KB (~600MB per hour).
Retry, retry… and succeed!

Another important part of backup performance is the capacity to retry an operation to maximize its probability of success.
For example, should you encounter timeouts using the SOAP or REST API, you could retry and leverage the Bulk API. Should you encounter timeouts using the Bulk API, you could retry and leverage the Bulk PK Chunking header (Spring ‘15).
Especially in the context of file/Base64 backups, defining a retry policy (failure or corruption detection, incremental/fixed interval/exponential backoff pattern) will play an important role in your backup strategy.
What about Backup optimization principles?
Figure 2 and the article “The Salesforce Bulk API – Maximizing Parallelism and Throughput Performance When Integrating or Loading Large Data Volumes” written by Sean Regan show how important parallelization can be to extract Large Data Volumes (LDV) and optimize a backup strategy.
Parallelizing several queries is a first step. What about parallelizing a single query to accelerate the backup of the Account object for example?
| Vertical optimization | Backup time is, among other parameters, proportional to the number of records you are retrieving. Splitting vertically your query into several queries to reduce the number of records included per query can bypass several incidents like timeouts or other limits (for example, in Spring `15 a single Bulk query can only generate up to 15GB of data). This approach can be efficient if taking into account how the Force.com Query Optimizer works. Using PK Chunking is one very efficient way of splitting a query vertically. Partial backup is also a type of vertical optimization. |
| Horizontal optimization | Backup time is, among other parameters, proportional to the number and types of columns you are retrieving. Text areas (and other large fields) are fields that can really slow down a backup to the point of timeout. Splitting horizontally your query into several queries, to reduce the number of fields included per query, will avoid several issues like timeouts or query size limit (i.e. in Spring `15, by default, SOQL statements cannot exceed 20,000 characters in length). Removing fields from the query (i.e. calculated fields) is also a type of horizontal optimization. |
In either case, you will have to add the time required to merge the final results to your time estimates.
Part 1 summary
This article was a gentle introduction to backing up and restoring data/metadata using Force.com APIs, and we’re just getting started. Look for the next part of this series soon and learn more about Restore.
Related resources
Salesforce Backup and Restore Essentials Part 2: Restore Strategies and Processes
Salesforce Backup and Restore Essentials Part 3: Learn from a Customer’s Experience
Salesforce Backup and Restore Essentials Part 4: Minimize Transformation when Restoring Data
Salesforce data recovery
Bulk API limits
Bulk PK Chunking Header
SOQL and SOSL Limits
Data replication API
Condition Expression Syntax (WHERE Clause)
Salesforce Data Export Service
About the author and CCE Technical Enablement
Sovan Bin is a Salesforce Certified Technical Architect and the CEO and Founder of odaseva.com, an AppExchange enterprise software provider based in both San Francisco and Paris, addressing the challenges of Salesforce data recovery (backup & restore) and release management (metadata comparison, sandbox initialization & data quality). He has been providing innovative solutions regarding Salesforce platform governance, security and performance since 2006.
This post was published in conjunction with the Technical Enablement team of the Salesforce Customer-Centric Engineering group. The team’s mission is to help customers understand how to implement technically sound Salesforce solutions. Check out all of the resources that this team maintains on the Architect Core Resources page of Salesforce Developers.