Building solutions on the Lightning Platform is a highly collaborative process, due to its unique ability to allow Trailblazers in a team to operate in no code, low code and/or code environments. Lightning Flow is a Salesforce native tool for no code automation and Apex is the native programming language of the platform — the code!
A flow author is able to create no-code solutions using the Cloud Flow Designer tool that can query and manipulate records, post Chatter posts, manage approvals, and even make external callouts. Conversely using Salesforce DX, the Apex developer can, of course, do all these things and more! This blog post presents a way in which two Trailblazers (Meaning a flow author and an Apex developer) can consider options that allow them to share the work in both building and maintaining a solution.
Often a flow is considered the start of a process — typically and traditionally a UI wizard or more latterly, something that is triggered when a record is updated (via Process Builder). We also know that via invocable methods, flows and processes can call Apex. What you might not know is that the reverse is also true! Just because you have decided to build a process via Apex, you can still leverage flows within that Apex code. Such flows are known as autolaunched flows, as they have no UI.
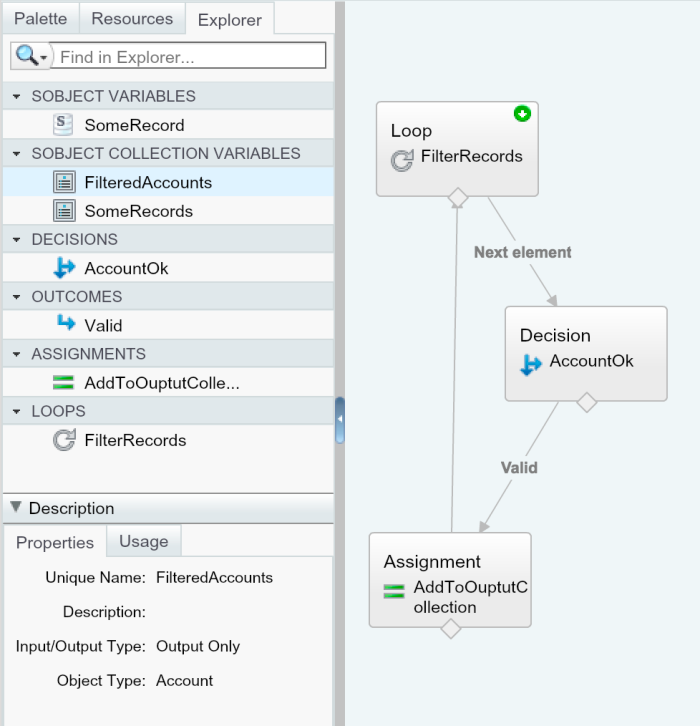
As a developer that has written some Apex code (for example, a controller or scheduled job), that code can call flow to delegate processing and/or provide a form of extensibility available to a flow author. The following code shows a basic example of this, also highlighting a very cool feature permitting your Apex code to explicitly reference the flow output parameters. You can read more about this explicit approach in an earlier blog of mine here.
The above code calls a flow called FilterAccounts that takes a list of Accounts as input via the SomeRecords input variable and outputs a filtered set via the FilteredAccounts output parameter.
The downside with explicitly referencing / hardcoding a flow in your Apex code, as shown above, is that it becomes the only flow that can be called and that flow has to travel with your Apex code as a hard dependency, including all the things the flow references. This is less desirable when you want to allow the flow author freedom over which flow to use and you want to make calling the flow an optional configurable part of the process (also quite appealing for package developers).
Enter dynamic Flow invocation from Apex, new for the Spring’18 release.
The following code performs the same task as the above but does so without explicitly referencing the flow. In this example, the dynamicFlowName variable is hardcoded of course but could be obtained dynamically via configuration in Custom Metadata types for example (more on this later!).
As you can see from the code above the flow is using a variable to determine which flow to load. It is also using the getVariableName method to dynamically extract the flow output parameters. Note that if the output parameter is not defined and marked as Output in the flow, then null is returned.
Introducing the FlowProcess class
The above code for interacting with flow is great but could do with some better error handling, readability and support for dynamically resolving the flow to run. Just the type of code that can easily run into the category of boilerplate code. My response to this is a small open source class I have called FlowProcess.
The FlowProcess class wraps the above API and allows you to manage the execution and interfacing of runtime resolved flows in Apex. It focuses on providing support for declaring inputs and outputs as well as integrating with Custom Metadata types as a means to allow admins to control which flows are invoked.
The above example can be rewritten using the FlowProcess class (which leverages the Fluent API design). The result is more expressive as it captures the intended inputs and outputs. This class will also throw an exception if the flow does not return the expected FilteredAccounts output parameter.
This next example tells the FlowProcess class to use a Custom Metadata record to look up the flow to execute. In this case, the parameter passed to the named method is not a flow name, but the DeveloperName of the custom metadata record that contains the flow to run. Custom metadata records can be created by admins, included in change sets, and also packaged, so are great for managing configuration data.
To set up the Custom Metadata Type, go to the Setup menu and enter Custom Metadata in the search box. Then create a Custom Metadata type with a single text field of your choosing.
The following is a simpler example if you are wanting the flow to simply return something where no inputs are required from the calling Apex code. Again, this will throw an exception if the flow being called does not define an output parameter or provide a value for it.
Finally, if things are a little more complex, you can still access multiple inputs and outputs as follows. Note the use of the required method. This declares a required output parameter. An exception is thrown if the OutputC parameter is not defined in the flow. In the case of OutputA and OutputB these are considered optional.
Apex testing and mocking flows
The FlowProcess class also has built-in support for emulating or mocking a flow. This enables you to write Apex test code covering different scenarios that flows might result in, such as invalid or missing parameters, optional parameters, etc. The sample code below shows how the Apex Stub API is used to mock the FlowProcessRuntime class (used by FlowProcess). For more information about using the Stub API, see the documentation here.
A closing word on defining required flow parameters
Some closing notes in terms of designing these types of interactions:
- Naming: Give some thought to the flow parameter names expected. Consider a prefix, e.g. myapp_FilterAccounts. This will ensure it’s easier for the flow author to tell the difference between parameters used internally by the flow and those required by the calling Apex logic. If you are a package developer, you may want to use your namespace.
- Bulkification: As you can see from the examples above, you can pass in collections/lists as well as single values. By keeping bulkification in mind, you can avoid the flow being called multiple times. Passing in collections to the flow does make the flow logic a little more complex, but is worth the efficiency gain to the Apex code and the flow.
Summary
Regardless as to which approach you decide to use, explicit or dynamic, hopefully this blog has given you some inspiration on how to empower a more collaborative experience between developers and admins when architecting solutions. Keep in mind that you should also be looking for ways in which you can expose Apex into Lightning Flow as well. Have fun!
To learn more, check out the Automate Your Business Processes with Lightning Flow trail on Trailhead.
About the authors
Andrew Fawcett recently joined Salesforce as VP of Product Management on the Platform team. Prior to that, Andrew was the Chief Technology Officer of FinancialForce, a leading provider of accounting and ERP apps on the Salesforce platform. Andrew was a long-standing Salesforce Developer & Community MVP prior to joining the company, and also published the well-regarded book Force.com Enterprise Architecture through Packt Publishing. Andrew has contributed a prolific number of projects and libraries to the Salesforce developer open-source community, including the widely-used “Declarative Lookup Rollup Summaries”. Follow him on Twitter @andyinthecloud.
Jason Teller is Director of Product Management for Salesforce Process Automation. He’s spent the last 20 years building platforms for healthcare, telcos, banks, security, payments, IoT, and immediately prior to Salesforce as Platform PM for Guidewire Software, the largest software provider to the Property and Casualty Insurance industry.