

Salesforce is a multi-tenant platform that serves multiple customers on the same hardware. With this type of architecture, the Salesforce Platform imposes limits to enforce an even distribution of resources across all tenants. Such limits include API consumption, Apex governor limits, and others. Most of the developer-related limits are described in the Salesforce Developer Limits and Allocations Quick Reference, however, it’s easy to overlook other limits like data and file storage allocations.
In this post, we’ll look at file storage and explore a solution that allows you to reduce file storage consumption by offloading documents to Amazon Web Services (AWS) using Salesforce Functions. We’ll share sample implementations for exporting and importing documents from Amazon Simple Storage Service (Amazon S3).
Working with documents at scale
The amount of file storage that is available in Salesforce varies depending on the org edition, but the Platform is not designed to store large volumes of files like an Enterprise Content Management (ECM) solution. This is why you typically want to integrate with dedicated storage solutions, such as Google Drive, Dropbox, Box, or AWS, when you deal with large numbers of documents.
Given Salesforce’s expansive partnership with AWS that has resulted native integrations designed to simplify the developer experience, let’s explore how Amazon S3 can help us store documents.
Introducing Amazon S3
Amazon S3 is a popular web services from AWS for file storage. S3 offers an API-enabled content storage service in environments called “buckets.” S3 is durable, reliable, scalable, secure, and available across the world, and AWS provides SDKs for multiple programming languages. Just like with Salesforce Functions, you can sign up for an AWS free tier account to start using the service.
These reasons make AWS S3 a great candidate for building an integration that transfers documents from Salesforce to S3, and thus saving on document storage consumption.
Offloading documents with Salesforce Functions and Amazon S3
The first thing that comes to mind when designing a solution that offloads documents to S3 is to keep it simple and use Apex to communicate directly with S3’s REST APIs. Why would you need anything else, given the fact that Apex can consume those APIs natively, right?
This question brings us back to limits. Apex transactions have a total heap space of up to 12 MB (excluding email services, which have a limit of 36 MB). This limit is likely to cause issues when working with documents at scale.
If you try to read the content of a single 13 MB document with Apex, you’ll hit the heap space limit.
A good way to avoid this issue is to use Salesforce Functions. Functions are designed to process data beyond the limits of Apex. Since Functions run outside of core Platform transactions, more permissive limits apply. This means that Functions can run for longer periods of time and consume more CPU and memory than Apex. They are a great fit for interacting with documents at scale.
Thanks to Functions, you can transfer documents to S3 with the following integration scenario:
- User uploads and attaches a document to a record in Salesforce
- Apex trigger kicks in after the document is saved and calls a handler class with the document metadata (not the document content, to avoid Apex limits)
- Apex trigger handler class invokes a Salesforce Function asynchronously with the document metadata
- Function retrieves the document content using the Salesforce REST API
- Function uploads the document content to an Amazon S3 bucket thanks to the S3 JavaScript client
- Once the document is uploaded, the function creates a Salesforce record that links the document stored in S3 to the record and it calls an Apex callback method on the trigger handler class
- Apex callback method removes the original document from Salesforce

Let’s now shift to a user experience point of view. The flow starts with the user uploading the document on the record using the standard file upload button in Notes & Attachments.
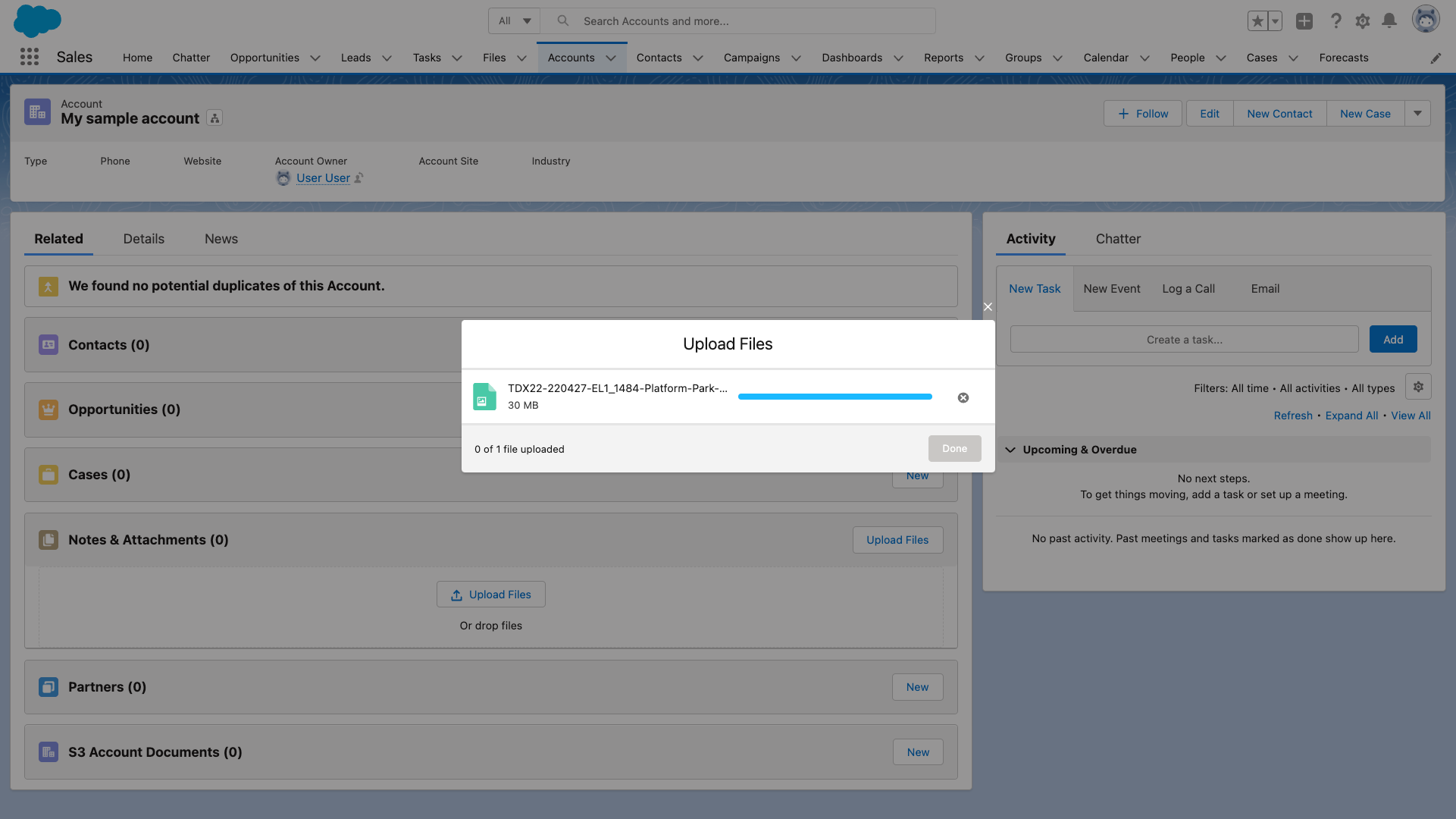
After attaching a document to a record, the user will see the document moved from the standard Notes & Attachments section to a new S3 Account Documents list. From there, they can see the document metadata, such as name, S3 storage URL, owner, and created date.
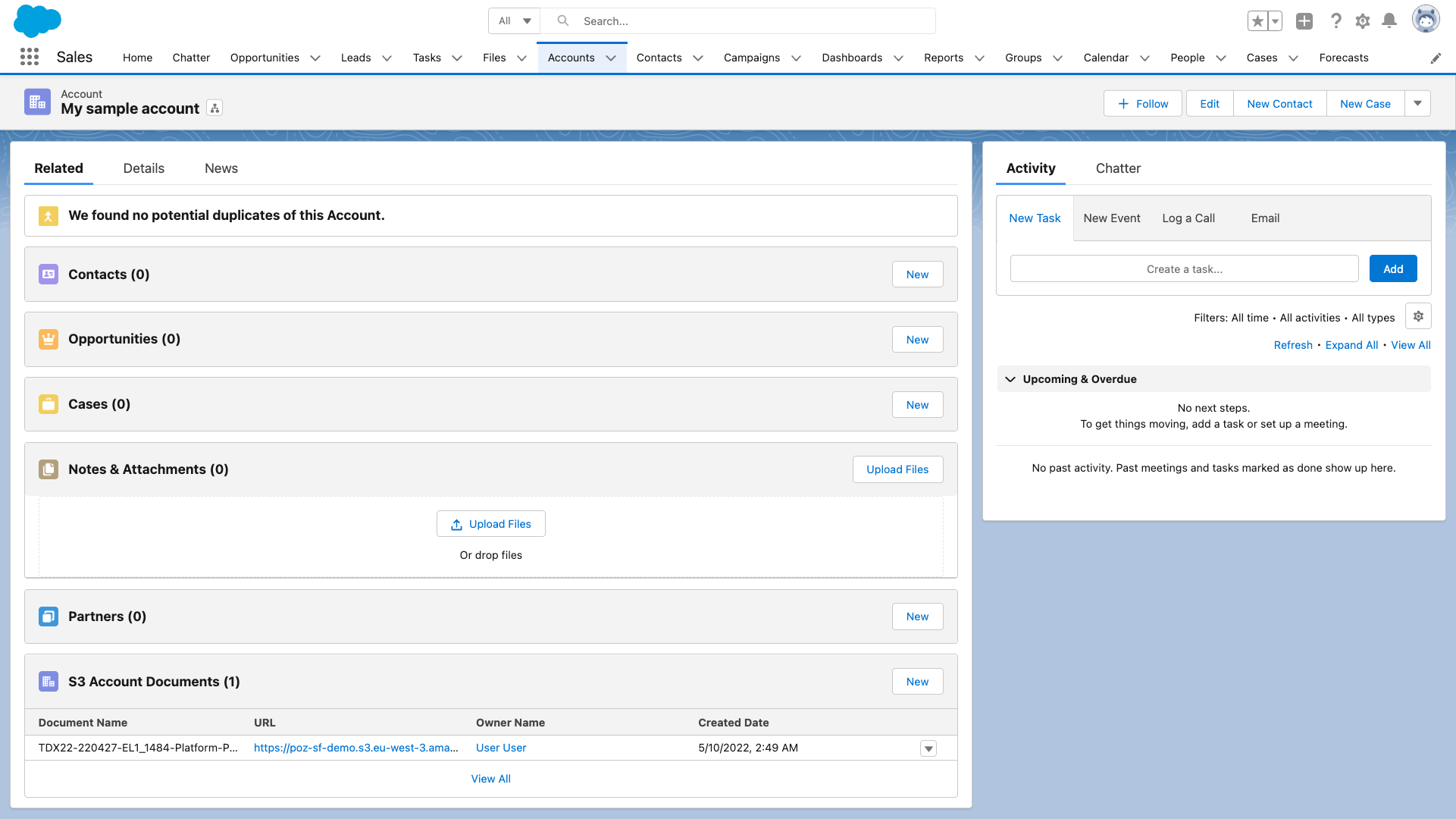
You can find an implementation of the scenario that we just shared in this sample GitHub repository. You’ll find detailed setup instructions that guide you through the deployment of the environments and explain how to configure the solution to support documents for multiple objects.
Once you’ve put in place such an integration to save on Salesforce file storage consumption, you’ll want to look into accessing files from S3.
Accessing documents from Amazon S3
As an AWS administrator, you can access the document stored in S3 from the AWS Console. But what about your users?
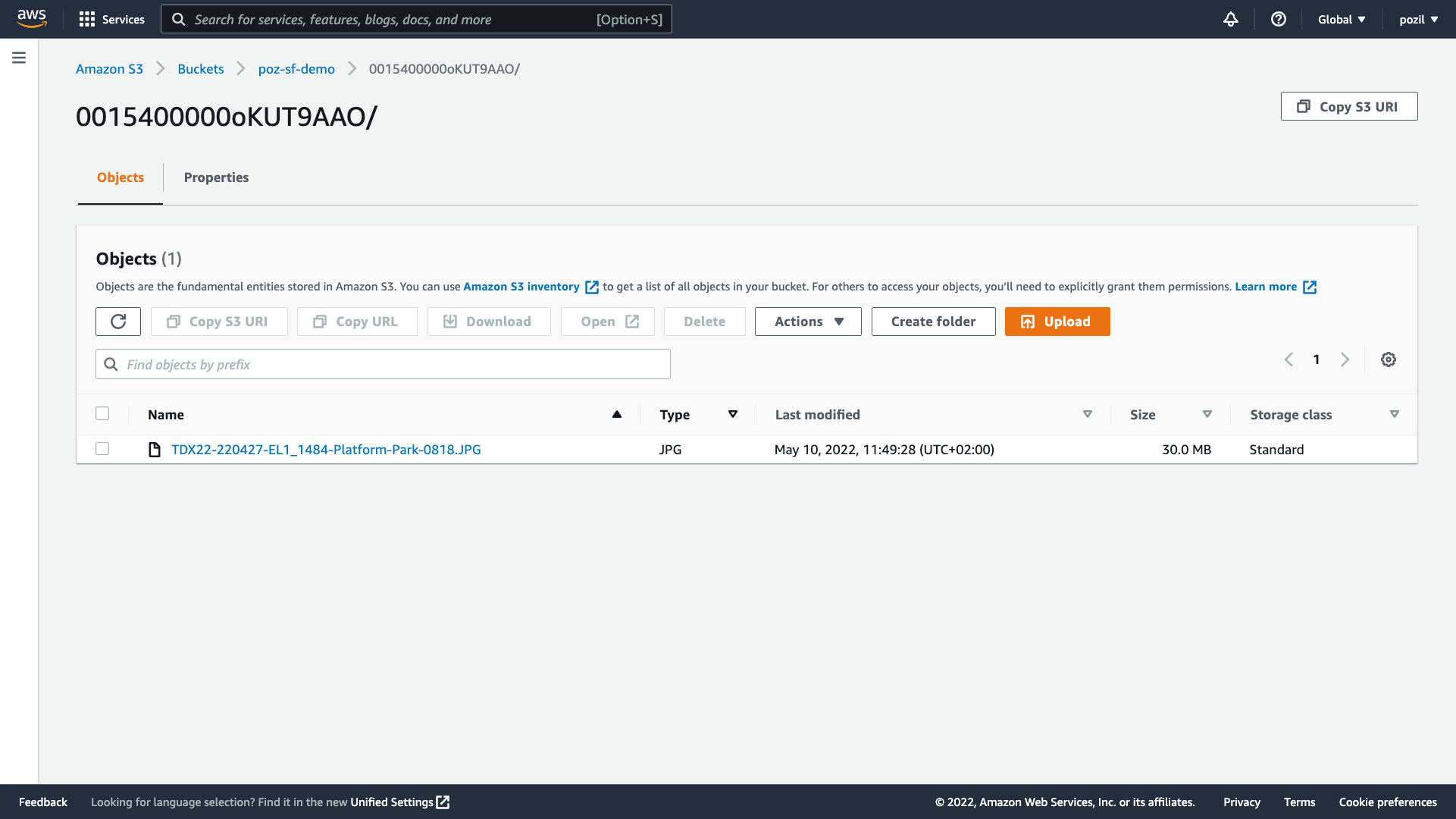
You can grant users access to S3 by setting up IAM (Identity and Access Management) users and policies from the AWS Console, or you can implement middleware integration solutions that provide access to the documents. You won’t be able to use Salesforce Functions to retrieve documents.
The first option involves configuring individual user access and permissions from the AWS Console. You would need to create separate credentials in AWS and use a Single Sign-on (SSO) solution to reconcile identities with Salesforce. You can invest in automation to help you scale, however, if you have specific access requirements, there are other options that can help.
The second option involves implementing a lightweight middleware application that’s connected to Salesforce with OAuth 2.0. The app would uses an API integration user for AWS with read-only access to load documents on demand. We’ve implemented such a solution using a Node middleware app in this sample GitHub repository.
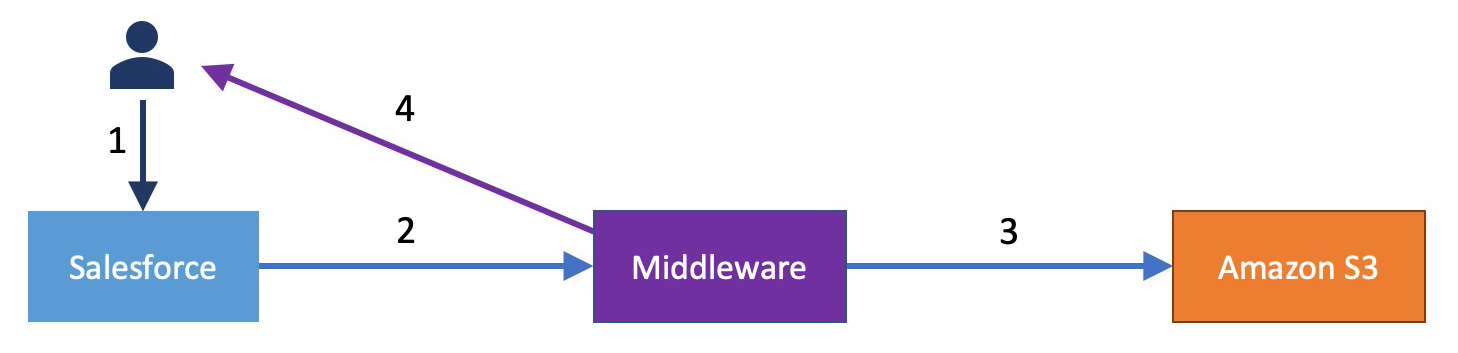
This approach can be summarized in four steps:
- A user clicks on a link on the S3 Document record in Salesforce.
- The link redirects the user to the middleware app where the user goes through OAuth authentication using their Salesforce credentials. The OAuth flow is implemented thanks to a Salesforce Connected App.
- The middleware runs some permission checks, and if the user is allowed to access the document, the middleware uses a S3 API client to retrieve the file from Amazon.
- The content of the file is then served back to the user. If the user was already logged in with the connected app before the original request in step 1, the document is sent seamlessly as a response (the user will not notice the intermediate steps).
Closing words
In this example, we outlined steps for leveraging Salesforce Functions to offload documents from Salesforce to Amazon S3 in order to reduce file storage consumption. And we’ve shown how you can retrieve the documents using a middleware app. This use case highlights the power of Salesforce Functions when processing large volumes of data and the flexibility of Amazon S3 for storage. Get started with Functions and S3 using the sample repositories.
Resources
- Sample GitHub repositories
- Salesforce metadata and a Function for exporting documents to Amazon S3
- Middleware Node app for downloading documents from Amazon S3
- Documentation
About the author
Philippe Ozil is a Principal Developer Advocate at Salesforce where he focuses on the Salesforce Platform. He writes technical content and speaks frequently at conferences. He is a full stack developer and enjoys working on DevOps, robotics, and VR projects. Follow him on Twitter @PhilippeOzil or check his GitHub projects @pozil.