



※本記事は2026年2月17日に米国で公開された Agent Script Decoded: Intro to Agent Script Language Fundamentalsの抄訳です。本記事の正式言語は英語であり、その内容および解釈については英語が優先されます。
エンタープライズグレードのAIエージェントの構築には、根本的なジレンマがあります。大規模言語モデル(LLM)は、自然な会話を得意としているものの、エンタープライズ規模のワークフローに必要な一貫性には欠けています。注文の詳細を伝える前に顧客の本人確認を行うように指示しても、LLMが毎回その手順を守るとは限りません。この問題は、従来のプロンプトエンジニアリングでは解決できません。プロンプトが長くなり、指示が増えると、AIエージェントの振る舞いが予測しにくくなることもあります。
Agent Script(英語)は、AIエージェントを構築するためのSalesforceの新しい言語です。Agent Scriptにはハイブリッド推論が導入されており、同じ命令ブロックの中で決定論的なコードと自然言語のプロンプトを組み合わせることができます。Agent Scriptを使えば、ビジネスに重要なロジックを毎回確実に実行しながら、柔軟な会話を維持できます。
Agent Scriptは、コンテキストエンジニアリングのためのツールでもあります。LLMが重要な情報をくみ取ることを漠然と期待するのではなく、変数、条件、会話の状態に応じて、LLMに渡すプロンプトをプログラムで組み立てられます。LLMは、その時点で必要な情報だけを参照します。
この記事では、Agent Scriptの基礎とAIエージェントの基本的な構成ブロックについて説明します。構文を学び、制御の流れを理解し、Agent Scriptが実行時にプロンプトを構築する仕組みを見ていきます。
Agent Scriptの基礎
AIエージェントの構築を始める前に、Agent Scriptの基本的な構文を押さえておきましょう。基本を理解しておくと、この後の記事の内容がわかりやすくなります。
プロパティベースの構文
Agent Scriptは、すべてkey: valueのペアで記述されます。読みやすい、宣言型の言語です。
スペースの重要性
Agent Scriptは、Pythonと同様に、インデントを使って構造を定義します。タブではなく、スペースを使用する必要があります。スクリプトが正しく解析されるには、インデントが一貫していることが重要です。推奨される記述方法は、インデントの各レベルを3つのスペースで表すことです。
注 – インデントに一貫性がないと、スクリプトがコンパイルされません。コードをコピー&ペーストするときは、特にこの点に注意してください。
@でリソースを参照
Agent Scriptでは、@記号を使って、変数、アクション、トピック、出力などのリソースを参照します。この仕組みで、AIエージェントを構成する各要素が情報をやり取りします。
注 – @がSalesforceの差し込み項目のように機能し、どの組織のリソースも参照できると思われるかもしれませんが、これはよくある間違いです。たとえば、@actions.get_orderが機能するのは、トピックのactions:ブロックでget_orderが定義されている場合だけです。@Account.Nameのような記述は、スクリプト内のブロックでも、組み込みのユーティリティでもないため、機能しません。
コメントアウトは#で
#記号を使うと、スクリプト内のどこにでもコメントを追加できます。その行の#以降の内容はすべて、コンパイラーに無視されます。AIエージェントのロジックを説明するために、コメントは積極的に使いましょう。Agent Scriptには、複数行のコメント専用の構文はありません。コメントが複数行にわたる場合は、各行の先頭に#を付けてください。
矢印構文(->)で手続き型ロジックを記述
条件分岐、アクションの実行、変数の設定など、段階的なロジックを記述する場合は、矢印構文を使用します。これにより、ブロックが宣言型モードから手続き型モードに切り替わります。
矢印は、「この後に続くのは、単なる設定ではなく、実行可能なロジックである」ことをAgent Scriptに伝えます。
注 – :も使用できますが、表記を明確にするために->の方がよく使われます。
プロンプトテキストにはパイプ構文(|)を使用
パイプ記号は、プロンプトの一部としてLLMに渡されるテキストを示します。自然言語の指示は、この方法で記述します。
パイプは、手続きブロックの外側で複数行の文字列を表す場合にも使用できます。
重要なポイントは、ロジックは決定論的に実行される一方で、パイプテキストはLLM向けのプロンプトとして組み立てられるということです。この分離が、ハイブリッド推論の中核を成しています。
動的な値を埋め込むためのテンプレート式({! })
変数の値または式をプロンプトテキストに埋め込むには、数式構文{! }で囲みます。Agent Scriptは、実行時にそれらを実際の値に置き換えます。
上記のスクリプトで、customer_nameが「ジョン」で、order_statusが「出荷済み」、order_totalが「150」の場合、LLMは以下のような入力を受け取ります。
こんにちは、ジョンさん。ご注文の状況は、出荷済みです。
ご注文の合計金額は150ドルです。
LLMは変数名ではなく、具体的な値を受け取ります。これにより、LLMの処理が簡単になり、AIエージェントの信頼性が高くなります。
注 – テンプレート値に使えるのは、変数だけはありません。演算子を使った式にすることもできます。サポートされている演算子の詳細については、こちらのドキュメント(英語)を参照してください。
...による入力値の抽出
アクションをツールとしてLLMに公開する場合、会話の中から必要な入力値をLLM自身に抽出させたいことがあります。...構文は、LLMにパラメーターの値をユーザー入力から抽出する(スロットフィリング)ように指示します。
この例では、LLMが会話の内容からorder_idを特定し、変数からcustomer_idを取得し、定数のlimitを10に設定します。
注 – ...構文は、アクション入力のスロットフィリングでのみ使用できます。よくある間違いですが、変数のデフォルト値としては使えません。
式の演算子
Agent Scriptは、比較と論理式に使われる一般的な演算子をサポートしています。これらの演算子は、if文やavailable when条件で使用します。
注 – Agent Scriptは、算術演算子として+と-をサポートしていますが、現時点では*、/、%はサポートしていません。複雑な計算が必要な場合は、FlowまたはApexのアクションを使ってください。
条件分岐
条件分岐(if/else)は、どの命令を実行するか、またはどのプロンプトを組み立てるかを制御します。
注 – else ifは現時点ではサポートされていません。代わりに、複数のif文を個別に使用してください。
基本のブロック
Salesforce DXプロジェクトでは、Agent ScriptはaiAuthoringBundlesディレクトリ内に配置されます。たとえば、「HelloWorld」エージェントを構築している場合、スクリプトは次のパスにある.agentファイルに��置されます。
force-app/main/aiAuthoringBundles/HelloWorld/HelloWorld.agent
このファイルは、AIエージェントの頭脳で、これから取り上げる設定、変数、会話トピックを含んでいます。
すべてのAgent Scriptファイルは、ブロック単位で構成されます。ブロックは、特定の順序で記述する必要があります。以下は、最上位のブロックを順番に並べた全体像です。
注 – この記事では、languageとconnectionは扱いませんが、connectionの使い方については、別の機会に詳しく説明する予定です。
では、顧客の注文情報を照会する「Order Management」エージェントを例として、順番に各ブロックを見ていきましょう。
1. config – AIエージェントの識別情報
configブロックでは、AIエージェントに関する基本的なメタデータを定義します。少なくとも、agent_nameを指定する必要があります。外部の顧客とやり取りするAgentforceサービスエージェントの場合は、default_agent_userも必要です。従業員支援エージェントでは、default_agent_userは必須ではありません。
agent_nameは、AIエージェントの一意の識別子として機能します。
2. variables – 状態管理
変数を使うと、AIエージェントが会話の複数のターンにわたって情報を保持できます。これはきわめて重要です。LLMは本来、過去のやり取りを記憶しません。そのため、状態を明示的に管理する必要があります。
Agent Scriptには、2種類の変数があります。
- 可変変数 – AIエージェントが読み書きできる変数です。可変変数には、デフォルト値を設定することが推奨されます。
- リンク変数 – 読み取り専用の変数で、外部コンテキスト(現在のセッションなど)から値を取得します。リンク変数には
sourceが必要で、デフォルト値は設定できません。
サポートされるデータ型の詳細については、公式ドキュメント(英語)を参照してください。
以下の点に注意してください。
- ブール値は、
True、Falseのように、先頭を大文字にする必要があります。true、falseは使用できません。 descriptionフィールドを使用すると、LLMが変数の内容を理解しやすくなり、スロットフィリングの精度が向上します。- 可変変数にはデフォルト値を設定することが推奨されますが、リンク変数にはデフォルト値を指定できません。
3. system – グローバルな指示とメッセージ
systemブロックでは、AIエージェントの性格を定義し、2つの必須メッセージであるwelcome(会話の開始時に表示)とerror(問題の発生時に表示)を指定します。
注 – これらの指示は、すべてのトピックに対してグローバルに適用��れます。ただし、特定のトピックでAIエージェントの振る舞いを変えたい場合は、トピックレベルで指示を上書きできます。以下は、トピックレベルで指示を上書きする例です。トピックについては、後ほど詳しく説明します。
トピックで独自のsystem.instructionsを定義している場合、そのトピックではグローバルな指示がトピック独自の指示に置き換えられます。この方法は、会話領域ごとにAIエージェントの性格や振る舞いを変えたい場合に便利です。
4. start_agent – 開始点
start_agentブロックには、独特の機能があります。すべてのユーザーメッセージは、1番目であっても50番目であっても、ここから実行が開始されます。AIエージェントの入り口となるところです。
通常、start_agentは、ユーザーを迎え入れ、その目的にもとづいて適切なトピックへ振り分けるために使用します。
available when条件に注目してください。go_to_order_statusへの遷移は、顧客の本人確認がすでに完了している場合にのみ、選択肢として表示されます。これが、状態に応じてフローを制御する仕組みです。
注 – アクションと遷移については、後ほど別のセクションで説明します。
5. トピック – 会話領域
トピックは、AIエージェント内の個別の機能領域を表します。たとえるなら、「本人確認」、「注文状況の確認」、「返品手続き」など、1つの会話の中のチャプターのようなものです。各トピックには、固有のアクション、指示、ツールがあります。この例では、AIエージェントはverificationとorder_statusという2つのトピックを使用します。
descriptionは重要です。特にstart_agentブロックでトピックを分類する際に、トピックが適切であるかどうかをLLMが理解する助けとなります。
重要な原則 – すべてのユーザーメッセージはstart_agentから始まります。そこから、AIエージェントはコンテキストにもとづいて適切なトピックに遷移します。
6. アクション – トピックが実行できることを定義
アクションは、トピックが呼び出せる機能を定義します。たとえば、FlowやApexクラス、APIなどです。アクションは、トピックごとにactions:ブロックで定義されます。
アクションは、いわば定義レイヤーです。存在する外部インターフェースを宣言し、その入力と出力を定義します。
上記の例では、Agentforceに「このトピックでは2つのアクションを利用できる。そのアクションはどう呼ばれるものか、どのような入力が必要か、どのような出力を返すか」を伝えています。ターゲットの種類とサポートされるデータ型については、公式ドキュメントのこちら(英語)を参照してください。
アクションは、定義しただけでは実行されません。関数を宣言するのと同じで、呼び出されるまでは何も起きません。では、どのようにアクションを呼び出すのでしょうか。それを行うのが推論レイヤーです。
7. 推論 – オーケストレーションレイヤー
推論ブロックでは、トピックの振る舞いを組み立てます。推論ブロックは、アクションの定義と実際の実行を橋渡しする役割を担います。すべてのトピックには、reasoning:ブロックを含める必要があります。reasoningの中には、次の2つの重要なセクションがあります。
instructions– 各ターンで実行されるロジックとプロンプトactions– LLMに公開するツール(「公開レイヤー」)
推論の指示 – ロジックとプロンプト
reasoning内のinstructions:ブロックでは、オーケストレーションが行われます。ここでは、次の要素を組み合わせて記述します。
- 手続き型ロジック(
->または:を使用)– 上から下に決まった順序で決定論的に実行されます。 - プロンプトテキスト(
|を使用)– 組み立てられて、LLMに送信されます。
矢印(->)は、手続き型コードであることを示します。
注 – 矢印の使用は任意であり、「:」を使うこともできます。パイプ(|)は、プロンプトテキストであることを示します。
次のように実行されます。
- Agentforceが、ロジックを上から下へ処理します。
- 条件を満たしているかどうかに応じて、プロンプトテキストが追加されていきます。
- 最終的に組み立てられたプロンプトがLLMに渡されます。
シナリオA – order_id = ""
作成されたプロンプト → 「注文に関する顧客の問い合わせに対応してください。顧客に注文IDを質問してください。」
シナリオB – order_id = "12345"
作成されたプロンプト → 「注文に関する顧客の問い合わせに対応してください。顧客の注文IDは12345です。」
状態にもとづいて、プロンプトが動的に作成される点に注目してください。
注 – 条件を満たしたパイプテキストはすべて、個別のタスクとして並べられるのではなく、1つのプロンプトに追加されていきます。LLMは1つにまとめられた指示ブロックを受け取ります。ここで重要なのは、reasoningループがターンごとにこれらの指示を再実行することです。ターンが進んで変数が変化すると、一致する条件が変わり、それに応じてプロンプトも書き換えられます。これにより、LLMは過去の会話の中で積み重なった指示ではなく、常にその時点のコンテキストに適した新しい指示を受け取ります。
指示からのアクションの呼び出し
アクションを呼び出す方法は2つあります。
方法1 – runによる決定論的な実行
LLMの判断なしで、特定の条件下で必ずアクションを実行する必要がある場合は、reasoning.instructions内でrunを使用します。
runコマンド
- 処理がその箇所に到達すると、直ちに実行されます。
withを使用して入力を渡します。- 出力を変数に格納するには
setを使います。
用途 – データの自動取得、必須の検証、ユーザー入力が何であれ、必ず実行するあらゆるロジック
方法2 – reasoning.actions内のLLMツール
会話のコンテキストにもとづいて、アクションを呼び出すかどうかをLLMに判断させる場合は、reasoning.actionsを使います。
このスクリプトでは、lookup_orderという次のようなツールが作成されます。
- 定義されたアクション(
@actions.get_order)を参照する - LLMがいつアクションを呼び出すか判断するための
descriptionがある - LLMが会話から値を抽出できるように、
...を使用してスロットフィリングを行う setを使用して出力を取得する
用途 – ユーザー起点のアクション、任意の機能、または会話のコンテキストにもとづいて判断すべきシナリオ
注 – わかりやすくするために、上記の例では1つのアクションだけを示していますが、1つのトピックに複数のアクションを含めることができます。また、{!@actions}を使って、これらのアクションをプロンプトの中で参照することもできます。以下に例を示します。
変数の設定
実行時に変数を設定する一般的な方法は2つあります。
- アクションの出力を取得する –
setを使用して、実行されたアクションの結果を格納します。 - LLMによるスロットフィリング –
@utils.setVariablesを使用して、LLMに会話から直接、値を抽出させます。
用途 – 外部システム、Flow、Apexのデータの場合は、アクションの出力を使用します。会話からユーザー入力を収集するには、setVariablesを使います。
制御の流れ – 実行の仕組み
以下の図は、トピック、アクション、推論が実行時に連携して動作する仕組みを示しています。
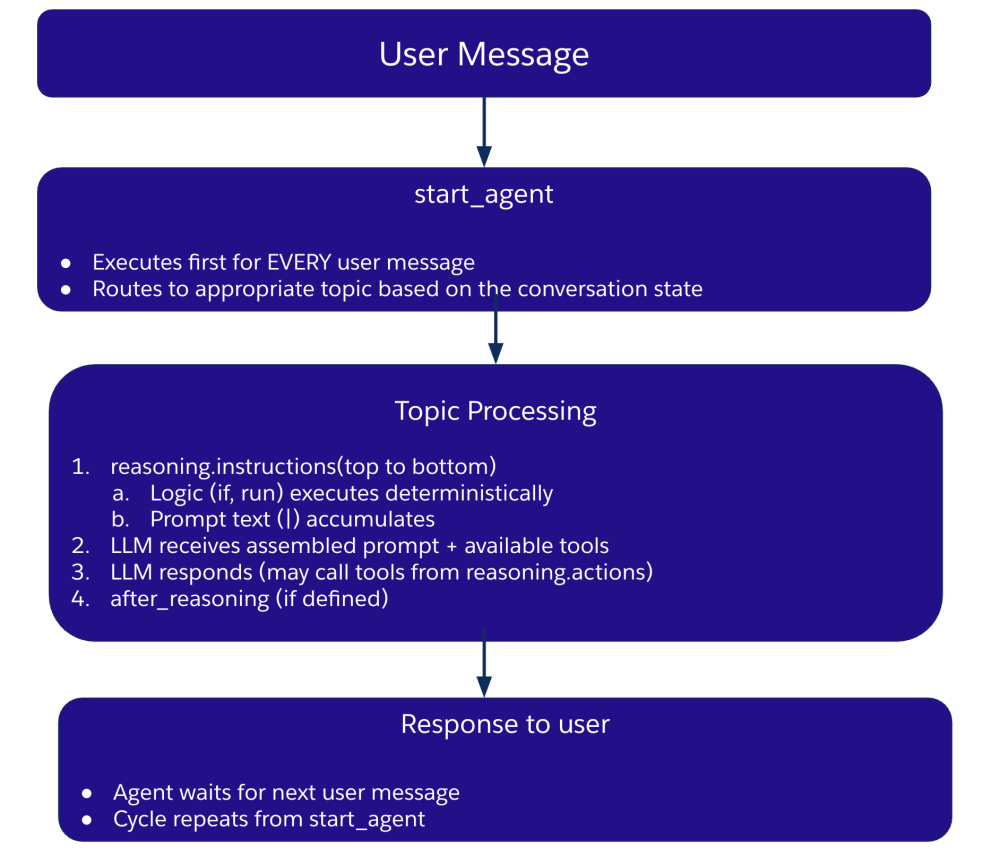
覚えておきたいポイント
- Agent Scriptでは、ハイブリッド推論を利用できます。ハイブリッド推論は、LLMの柔軟性とプログラムによる制御を組み合わせたものです。重要な思考モデルは次の3つです。
- トピック – 会話領域(AIエージェントが扱える会話の範囲)
- アクション – トピックレベルの定義(何を呼び出せるか)
- 推論 – 指示とLLMに公開されるツールを含む、オーケストレーションレイヤー
- すべてのメッセージは
start_agentから始まります。これは会話の途中であっても同様です。 - 指示は上から順に実行されます。LLMには、最終的に組み立てられたプロンプトのみが渡されます。
- 遷移は一方向です。
@utils.transitionでトピックを遷移すると、前のトピックに自動的に戻ることはありません。 - 完了後は入力を待機します。その後、フローは
start_agentに戻ります。
注 – トピックの委任を使って、元のトピックに戻る方法があります。この方法については、トピックの委任(呼び出し元に戻す)セクションで後述します。
推論後 – 後処理用のフック
オプションのafter_reasoningブロックは、LLMが応答を完了した後に実行されます。トピックが終了した後に必ず実行したいクリーンアップや遷移に使用します。
LLMが選択するreasoning.actionsとは異なり、after_reasoningは条件が満たされれば必ず実行されます。LLMが応答した後にガードレールや必須フローを強制する場合に最適です。
トピックの遷移
トピック間の移動には、コンテキストに応じて、異なる構文を使用します。
- LLMが選択 –
reasoning.actionsの中で@utils.transitionを使用
LLMはこれを利用可能なツールとして認識し、会話のコンテキストにもとづいて、使用するタイミングを判断します。
- 決定論的 –
reasoning.instructionsまたはafter_reasoningの中で、そのままtransition toを使用して即時に実行します。
上記の例では、LLMの判断を必要とせず、条件が満たされるとすぐに遷移が実行されます。
重要な構文のルール
@utils.transition to→reasoning.actionsの中でのみ使用すること- 単純な
transition to→reasoning.instructions:->またはafter_reasoningの中でのみ使用すること
注 – この2つを取り違えないようにしてください。使う場所を間違えると、エラーの原因になります。
トピックの委任(呼び出し元に戻す)
上記の方法は一方向ですが、直接の@topic.<name>参照を使うと、実行を別のトピックに委任できます。参照先のトピックが完了すると、フローは自動的に元のトピックに戻ります。
この方法は、別のトピックの専門的な対応を必要とし、その後に現在の会話を続けたい場合に便利です。
まとめ
この記事では、Agent Scriptの構文と基本的な構成ブロックを紹介しました。コードのサンプルをもっとご覧になりたい場合は、Agent Script Recipesサンプルアプリ(英語)を参考にしてください。次回の記事では、Agentforce DX(英語)や新しいAgent Builderなどの開発者向けツールを使って、AIエージェントを開発、デバッグ、テスト、デプロイする方法を詳しく見ていきます。