Caching Strategies for Salesforce B2C Commerce
Every merchant strives to have a fast and reliable website as the foundation of their shopper experience. One essential part of achieving great website speed is implementing efficient caching strategies that move content delivery as close to the consumer as possible.
A common misperception is that caching in Salesforce B2C Commerce means adding to a few templates, but there’s a lot more to it than that. First of all, you must understand the different layers of caching, which include:
- the shopper’s browser
- the CDN
- the web server
- the application server
- the storage layer (database)
An efficient caching strategy tries to move the cached content up this ladder as much as possible. The more layers being traversed, the slower the response times and the smaller the potential throughput of the website.
Let’s consider some examples that illustrate what an effective caching strategy looks like. Often developers work in silos or have a limited understanding of all the available architectural layers (while having a good understanding of one or two of the layers). This situation leads to solutions with limited scalability. The following example illustrates the power of using a combination of layers, instead of trying to solve the problem as a single one.
Show a heart icon (with a red outline) for each product of a search result, but show a heart icon that’s solid red for items the shopper saved to a wishlist.
A common approach is that the backend developer implements a solution that renders HTML representing the wishlist state of a given product. This approach is functionally correct but problematic. Because the result is specific to each shopper, the application needs to dynamically calculate this information for each product tile (the small product area shown in search results), traversing all the architectural layers.
By looking at the requirement, you notice that the wishlist contents don’t change frequently, and for scalability reasons, it’s desirable to have product tiles cached (without any dynamic calculations). With this in mind, a better solution exposes the wishlist content as an HTML data attribute in a pre-existing dynamic include (such as shopper information or login state in the header), and then updates the heart icon status via client-side JavaScript. On the server side, this approach comes at almost no additional cost, and the operation on the client side is relatively minor, too.
As a result, we have a solution that more efficiently leverages the available layers to achieve great end-consumer performance and allows for much better scalability compared to the server-side solution.
Now that we’ve addressed caching fundamentals, let’s focus on some of the specifics in Salesforce B2C Commerce. The following architectural layers manage caching.
- Web Server Layer > Page Cache
- Application Server Layer > Custom Caches (CacheMgr)
- Storage Layer > Custom Attributes or Custom Objects.
Let’s consider how you’d leverage each of these layers.
Page caching is one of the most critical concepts of the cache mix as it represents the topmost layer of the platform. Requests served from the page cache don’t create load on the application or storage layers. Remote includes make this concept even more powerful. These Server Side Includes (SSI) are placeholders in the page for which the web tier issues a new request, which can have its own cache policy.
For example, assume you have a static content page, which is entirely cacheable, and you want to include dynamic information like the shopper’s login state. Do this by using a remote include. While the main request might be cached for a number of days, another request is issued that dynamically retrieves the shopper information to display in the header. This subrequest isn’t cached. The web tier inserts the dynamically computed piece of the page into the cached frame. The result is a whole page that contains both cached and uncached elements.
In essence, the page cache is a key value store. The key is the full URL including query string and the value is the cached page. The page can contain markers for remote includes that are resolved the same way. The high-level processing logic is as follows.
-
The request is made.
-
Check if the cache entry for the given request path exists.
-
If Yes: Use the cached response and continue with processing remote includes. For each remote include, start at 1.
-
If No:
- Call the application layer to obtain a response.
- Check if the response is marked for caching. If yes, save in the page cache.
- Return the response.
-
The following URLs all create different cache entries and can (involuntarily) contribute to excessively high amounts of cache entries and a lower cache hit rate, because all those results are computed first. As such, it’s important to avoid adding dynamic parameters to includes, which are likely to change frequently (but don’t impact the response).
https://www.domain.com/path?param1=1
https://www.domain.com/path?param1=2 (change in parameter)
https://www.domain.com/path?param1=1¶m2=abc (additional parameter)
https://www.domain.com/path?param2=abc¶m1=1 (change in parameter order)
https://www.domain.de/path?param1=1 (different domain)
https://www.domain.com/otherpath?param1=1 (different path)
One commonly applied anti-pattern is adding a position parameter to product tiles in a search result, which causes ineffective tile caching. Each tile is cached numerous times depending on its positioning in the search result, even though the same product is always displayed. This implementation allows navigation of the search result on the product detail page (PDP) by passing the search information via the product detail page URL. Also achieve this use case by applying a client-side solution, which drastically increases the throughput of the search pages.
Sometimes parameters are appended to your URLs that have no meaning for your page, such as the campaign ID of a newsletter campaign. The platform can ignore certain parameters for the purpose of caching. Configure this option in Business Manager by going to Administration > Feature Switches. In the same section, enable caching of 404 responses, which can positively contribute to your site’s scalability as well.
The platform also offers an out-of-the-box solution to personalize caching. With personalized caching the cache key is amended by the currently active price books and the applicable promotions.
Let’s look at what that means for two shoppers looking at the same page (as in, the same URL). In this example, shopper A has price book X registered, and shopper B has price book Y registered. The same product (no change in URL) is cached twice. All shoppers with price book X registered are subsequently served with the respective cache entry, as are shoppers with price book Y. Depending on the number of price books and promotions, this scenario can lead to a large increase in the number of cache entries, regardless of the price of the product being different. Thus, consider using personalized caching only when necessary.
Two APIs can control the caching behavior of the response.
- the
dw.system.Response#setExpires(milliseconds)script API - the
<iscache>tag
Note: SFRA provides decorators that you can use instead of 1. The decorators apply to preconfigured caching times. Historically, the ISML tag was the only option, and the script API was introduced later. As a best practice, we strongly recommend discontinuing usage of the ISML tag, and leveraging the script API instead. Both approaches control the caching of the entire response, not individual templates. Although both APIs have the same effect, using the script API is recommended for a number of reasons.
By using the script API, you define the caching behavior in the controller and avoid some of the challenges of the ISML tag. For example, using the <iscache> tag can be confusing, as it might suggest you’re just caching a template. In addition, it’s often difficult to understand which template defines the caching behavior of a response, because they can be nested, and each template can have its own <iscache> tag. (If so, the lowest defined cache time is applied.) Finally, a template might be used in different contexts that require different cache policies, making the implementation even more complex.
Some endpoints (entire pages or remote includes) must serve dynamic information, such as consumer data or cart information, so page caching can’t be applied. However, expensive calculations can still happen on those pages, and the results can be cached to reduce the overall processing time of the dynamic request.
A prominent example is configuration as code. This is typically (but not exclusively) used by companies with many brands in multiple countries. The configuration is stored in JSON files and can be extended by brand- and country-specific overrides. While reading a JSON file and merging JavaScript objects isn’t an expensive operation, the frequency of this operation makes it consume a significant amount of processing time. By caching the configuration for each brand and country combination, avoid this recalculation across every request (and every remote include), and the site benefits from faster page rendering times.
Let’s consider the various options for caching information at the application layer.
To save information within a single request, store data inside a module. In case the data is required again, this approach keeps its state. You save the data in the request with the additional logic attached. Request caching is useful, for example, if you want to save the shopper’s selected store but don’t want developers to directly interact with that data. The module saves the store ID internally and only exposes methods to return the store object, or to perform actions with the store, while hiding the implementation specifics (and keeping them in a single, central place). If your use case is to store just a small piece of data, use request.custom to save and read the information.
Custom objects are very versatile. Import and export custom objects. You can both write to and read them, and custom objects are persistent and consistent across all application servers. Common use cases for using custom objects include a scenario where the cached data must not get lost, or when a custom object acts as intermediate storage for data that’s processed later. The downside of custom objects is that they’re stored in the database, and therefore, all architectural tiers are traversed.
Custom caches enable developers to store a limited amount of information. Because they aren’t shared across application servers, the data isn’t synchronized. Use custom caches to save intermediate results of expensive operations that must happen within dynamic requests, or operations that happen frequently.
File caches are great for build-time optimizations. Use file caches, for example:
- To generate templates (in scenarios where template languages other than ISML are used)
- To optimize development code
- To create environment-specific configurations
If you want to cache smaller pieces of information for a shopper, consider using a session. Sessions are easy to implement, and you can use the data for building dynamic customer groups. Use the following options to store data in a session.
- Use
session.customwhen data is used for building dynamic customer groups. When data is stored insession.custom, the platform updates the dynamic customer groups. Use this option sparingly, as it can consume many system resources. - Use
session.privacywhen data isn’t used for building dynamic customer groups. This option doesn’t trigger customer group updates, and consumes fewer resources. The data is cleared out after logout.
Static content caching is a slightly different form of caching. Static content refers to images, style sheets, and client-side JavaScript — any files that are downloaded and consumed by the browser. Those files are delivered by the origin server and then cached within the eCDN. Static files are either managed directly in the environment or included in the code. For the latter, they are often generated during the build process. After those sources are on the server, they are served as-is and can’t contain any dynamically calculated information.
All of the caches covered so far can be cleared or flushed. This point is important to understand, because you want to make sure that data isn’t cached longer than needed. But also, frequent cache clears negatively impact performance and scalability.
| Caching Time | Configuration | How the cache is cleared | |
|---|---|---|---|
| Page Cache | Controlled via code. | Enable in Business Manager. Always on in production. | Via Business Manager, or implicitly when replication occurs. |
| — | — | — | — |
| Static Content Cache | Fix (on production) | Enable in Business Manager. Always on in production. | Via Business Manager, or implicitly when replication occurs. |
| Custom Objects | Controlled via code. | Control via metadata. | Custom objects exist until explicitly deleted, or based on retention settings in Business Manager. |
| Custom Caches | Controlled via code. | Enable in Business Manager. | Via Business Manager, or implicitly when replication occurs. |
Shoppers typically spend most of their time on certain key pages. Those pages translate into controller or pipeline endpoints, which you should monitor closely.
- Homepage:
Default-StartandHome-Show - Product Listing Pages (Search & Category Navigation):
Search-Show - Product Detail Pages:
Product-Show - Content Pages:
Page-Show
Make sure that all of these pages have a high cache hit rate and fast response times. Quantifying high and fast is challenging, as many factors play into these numbers, and numbers don’t necessarily mean a positive shopper experience.
Consider this scenario. An implementation generates links to variants on listing pages while the product detail page (PDP) always redirects to the primary product as a best practice. This solution likely leads to fast PDP metrics, because each call is effectively two requests: One to a variant that responds with a fast redirect, and the other is the PDP. As a result, the reported PDP average response time is skewed and appears twice as fast as it actually is (assuming the redirect response time is close to zero). The actual shopper experience, however, won’t be optimal, because not only is the PDP slow, there’s an additional redirect.
A wide variety of situations can impact the average response times, so it’s important to look holistically at performance rather than focusing on a single number as an indicator.
Use percentage of processing time as a good indicator, because it offers the best potential for optimization. Either improve page caching or optimize processing times by using other forms of caching or code optimizations.
A common pitfall is missing cache directives, like ones that have been either removed from the code by developers, or not added when new endpoints were created. Detect missed cache directives by using the Reports & Dashboards tool to identify endpoints that have a 100 percent cache miss rate.
As a best practice, review all endpoints a few days after site launch to make sure that endpoints are being cached as expected.
- Product Tile:
Product-Tile(can vary) - Content Snippets:
Page-Include - Content Slots:
__Slot-Render
All three key includes should have a very high cache hit rate and fast response times. Ideally, product search hit tiles have at least a 99 percent cache hit rate and a response time of <=1 ms. This time might sound very high at first, but in practice, it’s quite achievable due to the high request amount to product tiles. A drop of only a few percentage points leads to slow search result pages and reduced scalability.
The issue of missing cache directives applies to key pages just as it does for key includes. Use the Reports & Dashboards tool to identify endpoints that have a 100 percent cache miss rate.
When PageMgr.renderPage() renders a Page Designer page, the rendering process uses two nested remote includes.
- The first-level remote include is the system controller
__SYSTEM__Page-Include. This remote include determines the visibility fingerprint of the page and its components based on schedules, customer groups, or other visibility settings. This remote include passes the visibility fingerprint to the second-level remote include. - The second-level remote is the system controller
__SYSTEM__Page-Render. This remote include invokes therenderfunction to render the page.
Based on different visibility settings, each variation of the page is cached separately. For more information, see Page Designer Caching.
Content slots are served within remote includes to allow independent cache control. Developers can use cache directives in the rendering template, which controls the caching for the slot content. The system automatically recalculates the slot configuration to display, regardless of the cache settings in the rendering template, through an additional dynamic include.
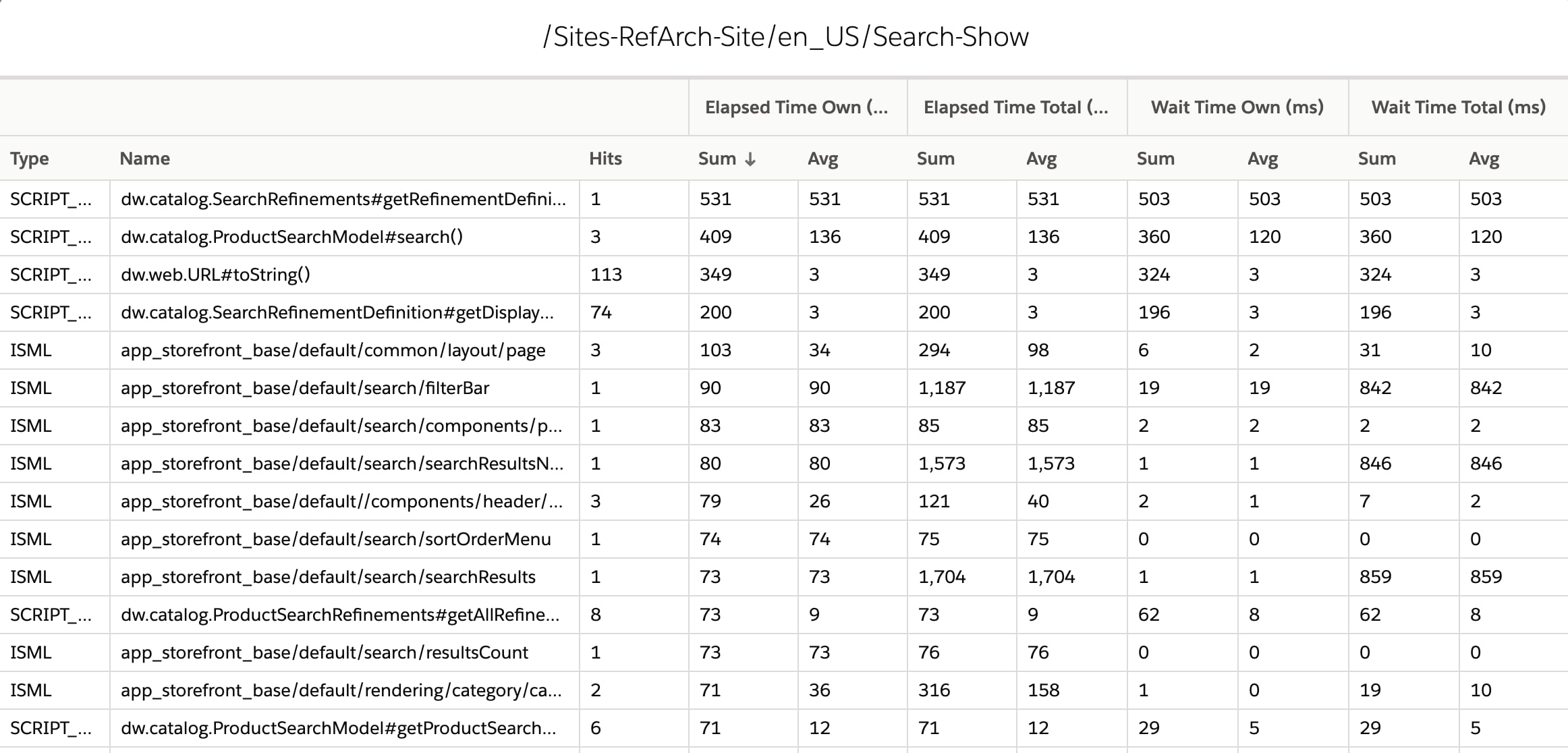
To optimize server-side performance, and increase the scalability and predictability of the system, start by referring to the Technical tab in the Reports & Dashboards tool. Focus on the top contributors of your overall processing time, and sort by that column (as shown in the following screen capture).

Now, you know the endpoint that contributes most to overall processing and offers the biggest potential for improvement. The last three columns indicate how many requests have been read from cache, calculated and stored to cache, and always dynamically calculated. If the last column shows 100 percent, the endpoint is uncached. Check and fix this issue first, because perhaps some endpoints haven’t been cached that should be.
Next, validate the pages that are cached. If the last column is not zero percent, some requests aren’t being cached and can indicate errors or code issues. A page that’s cached has zero percent in this column, and only has either cache hits or misses getting stored to cache.
After this, review the cache hit rates for areas of improvement. Consider how the page cache works and possible optimizations.
Finally, after you’ve investigated page caching optimizations, focus on the (now updated) processing times again. Review the code for optimizations. You might want to leverage the detailed report (accessed by clicking an endpoint).
Besides the Reports & Dashboards tool, the Code Profiler is another tool that provides great insights (after optimizing page caching). To use the Code Profiler:
- Select Extended Script Development Mode.
- Filter by Category equals REQUEST.
- Sort by Elapsed time > Sum.
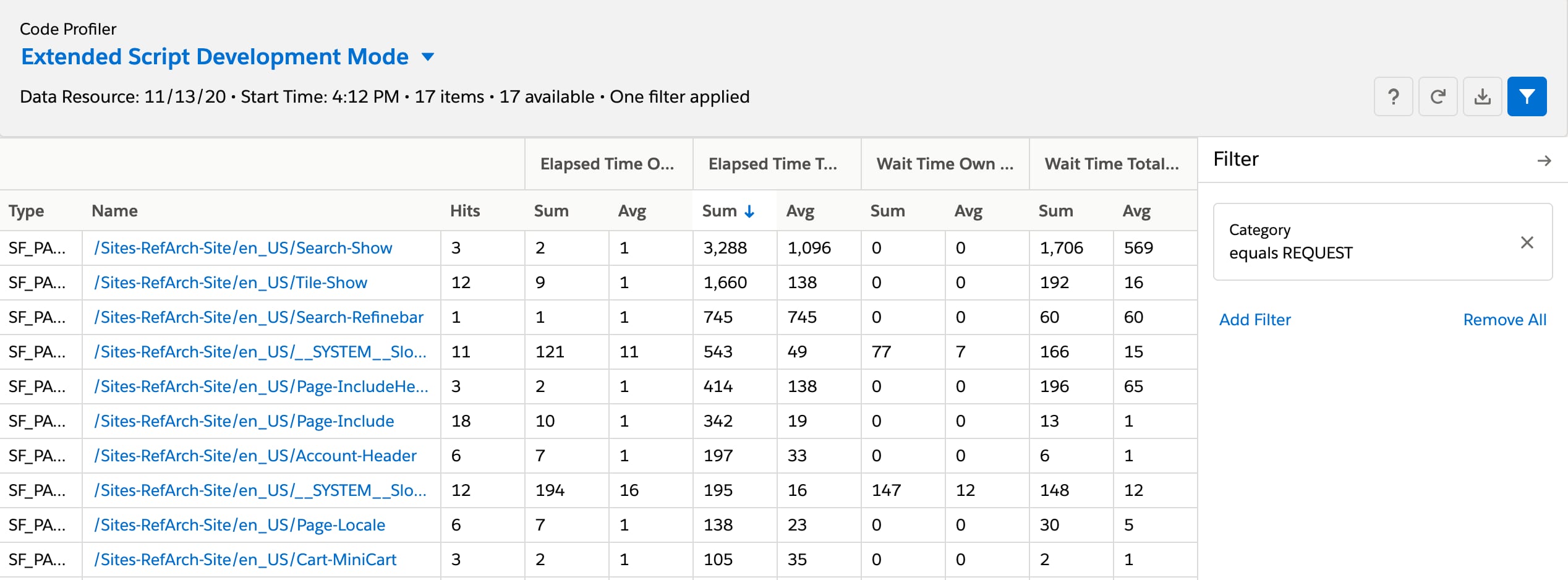
This list shows you the most calculation heavy requests at the top. Click to see the functions that contributed to the runtime. With production data, you usually find a short list of endpoints that contribute to a large part of the processing time. To identify which scripts and methods are contributing most to the total runtime, sort by Elapsed Time Own > Sum. Now, start at the top and investigate making those methods more efficient.