Analytics SAQL リファレンス
 j
jgroup
1 つ以上の項目を基準にしてデータストリーム内のデータをグループ化します。
構文
1result = group data_stream_1 by rollup(field1, [field2]);-
rollup - 省略可能。グループ化されたデータの合計を計算します。null 値のディメンションと、基準の合計結果を含む行がクエリ結果に追加されます。
rollup 修飾子では、group ステートメントのすべての項目を含める必要があります。サポート無し: q = group q by rollup('Type'), 'LeadSource';。サポート有り: q = group q by rollup('Type', 'LeadSource');。
rollup 修飾子では、次の集計がサポートされています。- Count
- Sum
- Average
- Min
- Max
- Unique
他の集計またはウィンドウ関数で rollup を使用すると、エラーが返されます。
- field - データのグルーピングの基準となる項目
例 - 1 つの項目を基準にしてグループ化する
各取引先所有者が抱えている商談の数を確認するとします。取引先所有者を基準にして、次のようにグループ化します。
1q = load "DTCOpps";
2q = group q by 'Account_Owner';
3q = foreach q generate 'Account_Owner' as 'Account_Owner', count() as 'count';
4q = order q by 'count' asc;
例 - グループ化されたデータの合計の計算
商談の金額をフェーズ別に確認する必要があるとします。フェーズ名でグループ化し、グループを積み上げ集計します。
1q = load "opportunityData";
2q = group q by rollup('StageName');
3q = order q by ('Stage Name');
4q = foreach q generate
5 'StageName' as 'Stage Name',
6 sum('Amount') as 'sum_Amount';クエリ結果では、すべての商談の金額合計が、商談フェーズ名ごとにグループ化した金額の合計を下回っています。合計行には、null 値のディメンションがあります。
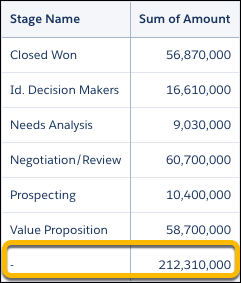
合計の表示ラベルに null 値が使用されていると、クエリ結果について誤解をまねく可能性があります。この誤解を避けるために、case ステートメントで grouping() 関数を使用し、合計として「All Stages (全フェーズ)」の表示ラベルを付けます。
1q = load "opportunityData";
2q = group q by rollup('StageName');
3q = order q by ('Stage Name');
4q = foreach q generate
5 (case
6 when grouping('StageName') == 1 then "All Stages"
7 else 'StageName'
8 end) as 'Stage Name';これでクエリ結果に表示ラベル付き合計が含まれます。
