Apex 開発者ガイド
 j
jNewer Version Available
String クラス
String のメソッド
String のメソッドは次のとおりです。
abbreviate(maxWidth, offset)
署名
public String abbreviate(Integer maxWidth, Integer offset)
パラメータ
戻り値
型: String
例
capitalize()
署名
public String capitalize()
戻り値
型: String
使用方法
このメソッドは、Character.toTitleCase(char) Java メソッドに基づいてます。
例
charAt(index)
署名
public Integer charAt(Integer index)
パラメータ
- index
- 型: Integer
- 値を取得する文字のインデックス。
使用方法
charAt メソッドは、指定されたインデックスで参照される文字の値を返します。インデックスがサロゲートペアの先頭 (上位サロゲートコードポイント) を参照している場合、このメソッドは上位サロゲートコードポイントのみを返します。サロゲートペアに対応する補助コードポイントを返すには、代わりに codePointAt をコールします。
例
次の例では、インデックス 0 にある最初の文字の値を取得します。
次の例では charAt と codePointAt の違いを示します。この例ではこれらのメソッドをエスケープされた補助 Unicode 文字に対してコールします。charAt(0) は、上位サロゲート値 (\uD835 に対応) を返します。codePointAt(0) は、サロゲートペア全体の値を返します。
codePointAt(index)
署名
public Integer codePointAt(Integer index)
パラメータ
- index
- 型: Integer
- 文字列に含まれる文字 (Unicode コードユニット) のインデックス。インデックス範囲は 0 ~ (文字列長 - 1) です。
使用方法
index がサロゲートペアの先頭 (上位サロゲートコードポイント) を参照していて、その次のインデックスの文字値が下位サロゲートコードポイントを参照している場合、このメソッドはサロゲートペアに対応する補助コードポイントを返します。それ以外の場合、このメソッドは所定のインデックスにある文字値を返します。
Unicode とサロゲートペアについての詳細は、「ユニコードコンソーシアム」を参照してください。
例
次の例では、インデックス 0 にある最初の文字のコードポイント値を取得します。この場合は、エスケープされたオメガ (Ω) 文字です。また、この例ではインデックス 20 のコードポイントも取得します。これはエスケープされた補助 Unicode 文字 (文字のペア) に対応します。さらに、オメガのエスケープされた形式とエスケープされていない形式のコードポイント値が同じであることを検証します。
この例の補助文字 (\\uD835\\uDD0A) は、次の数学用フラクトゥール大文字 G に対応します。 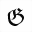
codePointBefore(index)
署名
public Integer codePointBefore(Integer index)
パラメータ
- index
- 型: Integer
- 返される Unicode コードポイントの前のインデックス。インデックス範囲は 1 ~文字列長です。
使用方法
index-1 の文字値が下位サロゲートコードポイントで、index-2 が負ではなく、このインデックス位置にある文字が上位サロゲートコードポイントである場合、このメソッドはこのサロゲートペアに対応する補助コードポイントを返します。index-1 の文字値がペアになっていない下位サロゲートまたは上位サロゲートコードポイントである場合、そのサロゲート値が返されます。
Unicode とサロゲートペアについての詳細は、「ユニコードコンソーシアム」を参照してください。
例
次の例では、最初の文字 (インデックス 1 の前) のコードポイント値を取得します。この場合は、エスケープされたオメガ (Ω) 文字です。また、この例ではインデックス 20 のコードポイントも取得します。これはエスケープされた補助文字 (インデックス 22 の前の 2 文字) に対応します。
codePointCount(beginIndex, endIndex)
署名
public Integer codePointCount(Integer beginIndex, Integer endIndex)
使用方法
指定された範囲は beginIndex で開始し、endIndex—1 で終了します。テキスト範囲内のペアになっていないサロゲートは、それぞれ 1 つのコードポイントと見なされます。
例
次の例では、エスケープされた Unicode 文字が含まれるサブ文字列と、1 つのコードポイントと見なされる複数の Unicode 補助文字が含まれる別のサブ文字列内のコードポイントの件数を出力します。
compareTo(secondString)
署名
public Integer compareTo(String secondString)
パラメータ
- secondString
- 型: String
戻り値
型: Integer
使用方法
結果は次のとおりです。
- メソッドをコールした string が辞書編集的に secondString の前に来る場合は負の Integer
- メソッドをコールした string が辞書編集的に compsecondStringString の後に来る場合は正の Integer
- string が等しい場合は 0
string が異なるインデックス位置がない場合、辞書編集的に短い string が長い string の後になります。
equals メソッドが true を返す場合、このメソッドは 0 を返します。
例
containsWhitespace()
署名
public Boolean containsWhitespace()
戻り値
型: Boolean
例
equals(secondString)
署名
public Boolean equals(String secondString)
パラメータ
- secondString
- 型: String
戻り値
型: Boolean
使用方法
compareTo メソッドが 0 を返す場合、このメソッドは true を返します。
このメソッドを使用して、大文字と小文字を区別する比較を実行します。他方、== 演算子は、Apex セマンティックを一致させるために大文字と小文字を区別しない比較を実行します。
例
equals(stringOrId)
署名
public Boolean equals(Object stringOrId)
パラメータ
- stringOrId
- 型: Object
戻り値
型: Boolean
使用方法
ID 値を比較する場合、ID の長さが同じである必要はありません。たとえば、15 文字の ID 文字列を同等の 18 文字の ID 値を表すオブジェクトと比較した場合、このメソッドは true を返します。15 文字と 18 文字の ID についての詳細は、「ID データ型」を参照してください。
このメソッドを使用して、大文字と小文字を区別する比較を実行します。他方、== 演算子は、Apex セマンティックを一致させるために大文字と小文字を区別しない比較を実行します。
例
次の例は、さまざまな種別の変数を比較して、値が等価であった場合と等価ではなかった場合の両方を示しています。また、Apex によって比較される前に、特定の値がどのように自動変換されるかも示しています。
escapeCsv()
署名
public String escapeCsv()
戻り値
型: String
使用方法
string にカンマ、改行、または二重引用符が含まれる場合、返される string は二重引用符で囲まれます。また、文字列内のすべての二重引用符はさらにもう 1 つの二重引用符でエスケープされます。
string にカンマ、改行、二重引用符が含まれない場合、string が変更されずに返されます。
例
escapeEcmaScript()
署名
public String escapeEcmaScript()
戻り値
型: String
使用方法
Apex string と EcmaScript string の唯一の違いは、EcmaScript では単一引用符とスラッシュ (/) がエスケープされる点です。
例
escapeJava()
署名
public String escapeJava()
例
escapeUnicode()
署名
public String escapeUnicode()
例
escapeXml()
署名
public String escapeXml()
戻り値
型: String
使用方法
5 つの基本 XML エンティティ (gt、lt、quot、amp、apos) のみをサポートします。DTD または外部エンティティはサポートしていません。0x7f より大きい Unicode 文字はエスケープされません。
例
format(stringToFormat, formattingArguments)
署名
public static String format(String stringToFormat, List<Object> formattingArguments)
戻り値
型: String
バージョン管理動作の変更
バージョン 51.0 以降、format() メソッドは、stringToFormat パラメータの単一引用符をサポートし、formattingArguments パラメータを使用して���式設定された文字列を返します。バージョン 50.0 以前では、単一引用符はサポートされていませんでした。
例
getLevenshteinDistance(stringToCompare, threshold)
署名
public Integer getLevenshteinDistance(String stringToCompare, Integer threshold)
戻り値
型: Integer
使用方法
レーベンシュタイン距離は、ある文字列から別の文字列に変更するために必要な変更の回数です。1 文字の変更 (削除、挿入、または置換) が 1 つの変更としてカウントされます。
例:
この例では、レーベンシュタイン距離は 3 ですが、しきい値の引数が 2 でこの距離よりも小さいため、このメソッドは -1 を返します。
例
hashCode()
署名
public Integer hashCode()
戻り値
型: Integer
使用方法
この値は、Java String.hashCode の同等メソッドによって計算されるハッシュコードに基づきます。
このメソッドを使用して、String メンバー変数を含むカスタム型に対してハッシュコードの計算を簡単にすることができます。各 String 変数のハッシュコードに基づいて、使用しているデータ型のハッシュコードを計算できます。次に例を示します。
カスタム型を持つハッシュコードメソッドの使用の詳細については、「対応付けのキーとセットでのカスタムデータ型の使用」を参照してください。
例
indexOfChar(character, startIndex)
署名
public Integer indexOfChar(Integer character, Integer startIndex)
使用方法
このメソッドは、Unicode コードユニットでインデックスを返します。
例
次の例では、さまざまな方法でオメガ (Ω) 文字のインデックスを検索します。indexOfChar への最初のコールでは、開始インデックスを指定しないため、返されるインデックスは、文字列全体でオメガが最初に出現した位置を示す 0 です。後続のコールでは、開始イン��ックスを指定して、指定されたインデックスから開始するサブ文字列内でオメガが最初に出現した位置を検索します。
isAllLowerCase()
署名
public Boolean isAllLowerCase()
戻り値
型: Boolean
例
isAllUpperCase()
署名
public Boolean isAllUpperCase()
戻り値
型: Boolean
例
isAlpha()
署名
public Boolean isAlpha()
戻り値
型: Boolean
例
isAlphaSpace()
署名
public Boolean isAlphaSpace()
戻り値
型: Boolean
例
isAlphanumeric()
署名
public Boolean isAlphanumeric()
戻り値
型: Boolean
例
isAlphanumericSpace()
署名
public Boolean isAlphanumericSpace()
戻り値
型: Boolean
例
isAsciiPrintable()
署名
public Boolean isAsciiPrintable()
戻り値
型: Boolean
例
isNumeric()
署名
public Boolean isNumeric()
戻り値
型: Boolean
例
isNumericSpace()
署名
public Boolean isNumericSpace()
戻り値
型: Boolean
使用方法
小数点 (1.2) は Unicode 数字ではありません。
例
isWhitespace()
署名
public Boolean isWhitespace()
戻り値
型: Boolean
例
lastIndexOf(substring, endPosition)
署名
public Integer lastIndexOf(String substring, Integer endPosition)
戻り値
型: Integer
使用方法
サブ文字列がない場合または endPosition が負の場合、このメソッドは -1 を返します。endPosition が現在の string の最後のインデックスよりも大きい場合、string 全体が検索されます。
例
lastIndexOfChar(character, endIndex)
署名
public Integer lastIndexOfChar(Integer character, Integer endIndex)
使用方法
このメソッドは、Unicode コードユニットでインデックスを返します。
例
次の例では、さまざまな方法でオメガ (Ω) 文字が最後に出現した位置のインデックスを検索します。lastIndexOfChar への最初のコールでは、終了インデックスを指定しないため、返されるインデックスは、文字列全体でオメガが最後に出現した位置を示す 12 です。後続のコールでは、終了インデックスを指定して、サブ文字列内でオメガが最後に出現した位置を検索します。
lastIndexOfIgnoreCase(substring, endPosition)
署名
public Integer lastIndexOfIgnoreCase(String substring, Integer endPosition)
戻り値
型: Integer
使用方法
サブ文字列がない場合または endPosition が負の場合、このメソッドは -1 を返します。endPosition が現在の string の最後のインデックスよりも大きい場合、string 全体が検索されます。
例
mid(startIndex, length)
署名
public String mid(Integer startIndex, Integer length)
パラメータ
戻り値
型: String
使用方法
このメソッドは、substring(startIndex) メソッドと substring(startIndex, endIndex) メソッドに類似していますが、2 番目の引数が返される文字数である点が異なります。
例
normalizeSpace()
署名
public String normalizeSpace()
戻り値
型: String
使用方法
このメソッドは、空白文字 (スペース、タブ (\t)、改行 (\n)、行頭復帰 (\r)、およびフォームフィード (\f)) を正規化します。
例
offsetByCodePoints(index, codePointOffset)
署名
public Integer offsetByCodePoints(Integer index, Integer codePointOffset)
使用方法
index で指定されたテキスト範囲内でペアになっていないサロゲートは、codePointOffset でそれぞれ 1 つのコードポイントとして数えられます。
例
次の例では、開始インデックス 0 (最初の文字から開始) で 3 コードポイントをオフセットした位置から始まる文字列に対して offsetByCodePoints をコールします。文字列には、エスケープされた形式の補助文字のシーケンスが 1 つ (文字のペアが 1 組) 含まれます。文字列の先頭から数えて 3 コードポイントをオフセットした結果、返されるコードポイントインデックスは 4 です。
split(regExp)
split(regExp, limit)
署名
public String[] split(String regExp, Integer limit)
戻り値
型: String[]
使用方法
例
- s.split(':', 2) は {'boo', 'and:moo'} を生成します。
- s.split(':', 5) は {'boo', 'and', 'moo'} を生成します。
- s.split(':', -2) は {'boo', 'and', 'moo'} を生成します。
- s.split('o', 5) は {'b', '', ':and:m', '', ''} を生成します。
- s.split('o', -2) は {'b', '', ':and:m', '', ''} を生成します。
- s.split('o', 0) は {'b', '', ':and:m'} を生成します。
splitByCharacterType()
署名
public List<String> splitByCharacterType()
使用方法
使用される文字の種別についての詳細は、java.lang.Character.getType(char) を参照してください。
例
splitByCharacterTypeCamelCase()
署名
public List<String> splitByCharacterTypeCamelCase()
使用方法
使用される文字の種別についての詳細は、java.lang.Character.getType(char) を参照してください。
例
stripHtmlTags()
署名
public String stripHtmlTags(String htmlInput)
戻り値
型: String
使用方法
例
swapCase()
署名
public String swapCase()
戻り値
型: String
使用方法
大文字およびタイトルの文字を小文字に変換し、小文字を大文字に変換します。
例
toLowerCase()
署名
public String toLowerCase()
戻り値
型: String
例
toUpperCase()
署名
public String toUpperCase()
戻り値
型: String
例
trim()
署名
public String trim()
戻り値
型: String
使用方法
タブや改行文字など、先頭と末尾の ASCII 制御文字も削除されます。文の開始と終了にない空白文字と制御文字は削除されません。
例
unescapeCsv()
署名
public String unescapeCsv()
戻り値
型: String
使用方法
文字列が二重引用符で囲まれていてカンマ、改行、または二重引用符が含まれる場合、二重引用符は削除されます。また、二重引用符でエスケープされた文字 (二重引用符のペア) は、エスケープが解除されて 1 つの二重引用符になります。
文字列が二重引用符で囲まれていない場合、または二重引用符で囲まれていてカンマ、改行、二重引用符が含まれない合、string が変更されずに返されます。
例
unescapeHtml4()
署名
public String unescapeHtml4()
戻り値
型: String
使用方法
認識されない場合、エンティティは返された文字列でそのまま保持されます。
例
unescapeJava()
署名
public String unescapeJava()
例
unescapeXml()
署名
public String unescapeXml()
戻り値
型: String
使用方法
5 つの基本 XML エンティティ (gt、lt、quot、amp、apos) のみをサポートします。DTD または外部エンティティはサポートしていません。
例
valueOf(toConvert)
署名
public static String valueOf(Object toConvert)
パラメータ
- toConvert
- 型: Object
戻り値
型: String
使用方法
引数が string でない場合、valueOf メソッドはその引数に対する toString メソッド (利用可能な場合)、または引数がユーザ定義型の場合は上書きされた toString メソッドをコールすることで、引数を string に変換します。それ以外の、toString メソッドが利用できない場合は引数の文字列表現を返します。