Analytics SAQL リファレンス
 j
j文字列関数
関数
次に、SAQL 文字列関数のリストを示します。
ends_with(string, suffix)
1ends_with("FIT", "T") == true
2ends_with("FIT", "BIT") == falseindex_of(string, searchStr [,position [, occurence]])
position のデフォルト値は 1 です。つまり、関数は string の最初の文字から検索を開始します。position が負または 0 の場合、エラーが発生します。
指定されている場合、occurrence は string 内の何番目の一致を検索するかを示す整数です。occurrence の値は正にする必要があり、省略した場合はデフォルトで 1 が設定されます。たとえば、複数の一致があり、occurence が 2 の場合は、2 番目に一致した位置のインデックスを返します。
position および occurrence では定数値がサポートされ、任意の式はサポートされていません。
searchStr が空の文字列の場合、関数は null を返します。1index_of("Hawaii", "a") == 2
2index_of("Hawaii", "a", 2) == 2
3index_of("Hawaii", "a", 3) == 4
4index_of("Hawaii", "a", 3, 2) == 0
5index_of("Hawaii", "i", -1, 1) == error
6index_of("Hawaii", "i", -3, 1) == error
7index_of("", "i") == null
8index_of("i", "") == nulllen(string)
len は、string の長さを文字数で返します。string が null の場合、len(string) も null になります。
先頭および末尾の空白文字は、返される長さに含まれます。1len("starfox") == 7
2len(" rocket ") == 8
3len("謝") == 1
4len("") == 0lower(string)
1lower("JAVA") == "java"ltrim(string,chars)
ltrim は、chars に含まれない文字の最初の位置より左側を削除した string の値を返します。
chars には複数の文字を含めることができます。chars を省略した場合、先頭の空白文字が削除されます。string または chars が null の場合、結果は null になります。1ltrim("__c__val__", "_") == "c__val__"
2ltrim(string, " \t\r") == ltrim(string)
3ltrim("aabcd", "ab") == "cd"number_to_string(number, number_format)
-
number_to_string(number, number_format)
number_format で指定された形式は、正と負の両方の数値で使用されます。
-
number_to_string(number, <POSITIVE>;<NEGATIVE>)
number が正の場合、<POSITIVE> で指定した数値形式が使用されます。number が負の場合、<NEGATIVE> で指定した数値形式が使用されます。指定する 2 つの形式はセミコロンで区切ります。
たとえば、Amount (金額) を通貨で表示できます。
1q = foreach q generate 'Amount' as 'Amount', number_to_string('Amount',"$#,###.00") as 'NumberAmount';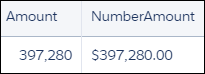
または、number_to_string('PercentAttained',"#.00%") を使用して、PercentAttained をパーセント (99.99% など) で表示できます。
| 数値リテラル | 必須の文字列リテラル | 使用する number_format |
|---|---|---|
| 1234.56 | 1234.6 | ####.# |
| 8.9 | 8.900 | #.000 |
| .631 | 0.6 | 0.# |
| 12 | 12.0 | #.0# |
| 1234.568 | 1234.57 | #.0# |
| 12000 | 12,000 | #,### |
| 12000 | 12 | #, |
| 12200000 | 12.2 | 0.0,, |
| 12 | 00012 | 00000 |
| 0.03457 | 3.46% | #.00% |
| 12.3 | $12.30 | $#.00;($#.00) |
| -12.3 | ($12.30) | $#.00;($#.00) |
| 32 | + | +;- |
| -32 | - | +;- |
replace(string、searchStr、replaceStr)
この関数は、一致するすべての searchStr を replaceStr で置き換えた string を返します。いずれかのパラメータが null の場合、関数は null を返します。searchStr が空の文字列の場合、null が返されます。この関数では、大文字と小文字が区別されます。
1replace("Watson, come quickly.", "quickly", "slowly") == "Watson, come slowly."
2replace("Watson, come quickly.", "o", "a") == "Watsan, came quickly."
3replace("Watson, come quickly.", "", "Mr.") == nullrtrim(string,chars)
rtrim は、chars に含まれない文字の最後の位置より右側を削除した string の値を返します。
chars には複数の文字を含めることができます。chars を省略した場合、末尾の空白文字が削除されます。string または chars が null の場合、結果は null になります。1rtrim("__c__val__", "_") == "__c__val"
2rtrim(ltrim(string, " \t\r"), " \t\r") == trim(string, " \t\r")starts_with(string, prefix)
この関数は、string が prefix で開始する場合は true、それ以外の場合は false を返します。文字列の比較では、大文字と小文字は区別されません。いずれかのパラメータが null の場合、関数は null を返します。prefix が空の文字列の場合、関数は null を返します。
1starts_with("FIT", "F") == true
2starts_with("FIT", "BIT") == falsestring_to_number(string)
これは number_to_string 関数の逆です。変換が失敗した場合、null が返されます。
substr(string,position[, length])
substr は、string から文字位置 position で開始する length 文字を返します。length を省略した場合、length = len(string) になるため、position から文字列の末尾までのすべての文字が返されます。いずれかのパラメータが null の場合、関数は null を返します。
string の最初の文字の位置は 1 です。position が負の場合、位置は文字列の末尾に対する相対位置になります。したがって、-1 のposition は最後の文字を示します。
length が負の場合、関数は null を返します。position > len (string)、position < -len(string)、または position = 0 の場合、空の文字列が返されます。1substr("CRM", 1, 1) == "C"
2substr("CRM", 1, 2) == "CR"
3substr("CRM", -1, 1) == "M"
4substr("CRM", -2, 2) == "RM"
5substr("CRM", 4, 1) == ""
6substr("2018-03-16T00:00:03.000Z",10) == "2018-03-16"trim(string,chars)
trim は、chars に含まれない文字の最初と最後の位置より外側を削除した string の値を返します。
chars には複数の文字を含めることができます。chars を省略した場合、先頭と末尾の空白文字が削除されます。string または chars が null の場合、結果は null になります。1trim("__c__val__", "_") == "c__val"
2trim("__c__val__", "_c") == "val"
3trim(" c__val ") == "c__val"
4trim(" c__val ") == ltrim(rtrim(" c__val "))
5trim("aaaaaa", "a") == ""upper(string)
1upper("go") == "GO"
2upper ("große") == "GROßE"