

Technical decisions on a project rarely get documented at the point when they are made. By the time someone asks “why did we choose X?”, the reasoning lives in a Slack thread, a meeting memory, or the head of someone who may not be in the team anymore.
Instead of letting critical project context vanish, you can leverage AI to enforce architectural rigour. By implementing a decision-scoring skill, project teams can transform their coding agents into guardrails for engineering design. In this post, you’ll learn how to build the /decide pipeline, a structured framework that moves you from broad discovery to verifiable decision record.
A skill to guide technical decisions
Salesforce Ada Agent Skills is an open source skill repository for agent skills beyond writing code. /decide is a structured pipeline that demonstrates how to use AI to drive technical decisions. Type ‘/decide managed package vs. unlocked package vs. unpackaged metadata for distributing utilities across 3 orgs’ and your coding agent runs you through discovery, options grounded in official documentation, a risk matrix you challenge based on real-world experience, and a scored recommendation written to disk as a decision record.
The output is a file: versioned, reviewable, and available to the next person who asks.
The underlying pattern of discovery, debating assessment criteria, and scoring works for any technical decision for admins, developers and architects — hence the ada acronym. I’ll be using Claude Code in the examples below, but it has been designed to be used in any agent you choose with scaffolding in GitHub for Gemini and Codex CLIs.
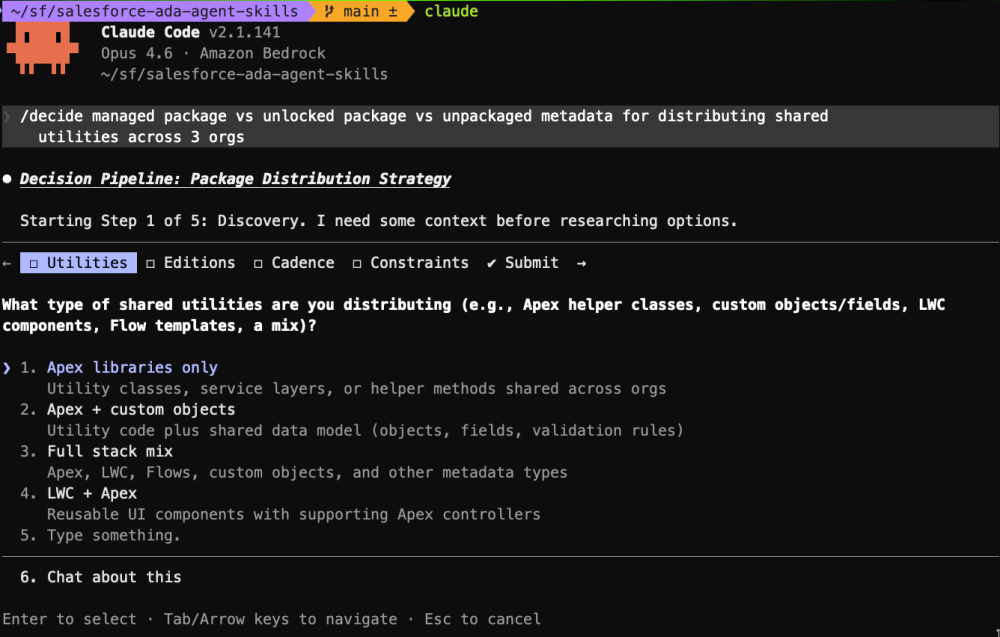
How the pipeline works
Each step of the pipeline further refines the scope and context of a decision. Each step’s output constrains the next step’s input, narrowing from broad research to a single verifiable number.
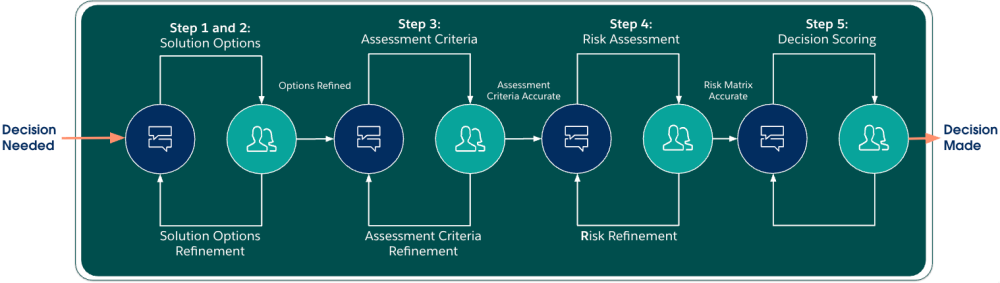
| Step | Description |
| 1. Discovery | Gather what makes this decision unique, things like data volumes, timelines, team skills, and constraints. The agent asks structured questions and skips anything already answered in the slash command argument. |
| 2. Solution options | Research official documentation in a single broad search, then present it as a table. A person confirms, adds, removes, or modifies before proceeding. |
| Check and review | |
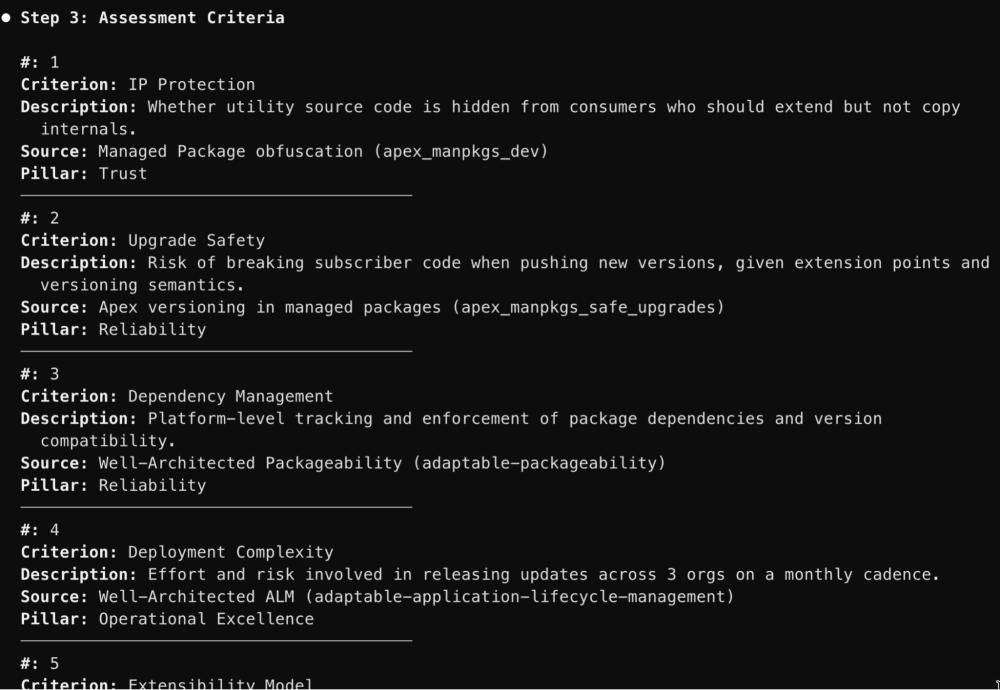
| 3. Assessment criteria | Define what “better” means for this specific decision, generated from the research results, confirmed by you. If a criterion is missing, the final score may be lacking context to that dimension. |
| Check and review | |
| 4. Risk assessment | Rate each option against each criterion as Low, Medium, or High risk with cited rationale. This is the data that drives the decision — a matrix that a person challenges before scoring happens. |
| Check and review | |
| 5. Decision scoring | Create a weighted sum of the risk ratings across well-architected pillars. The highest score wins. No narrative override. |
| Create a persistent document (optional) | |
Key design patterns
The pipeline above is what the skill does. The patterns below are how it’s implemented and the design choices to make a skill like this reliable, adaptable and worth trusting with a technical decision. Together, they give you output that you can verify, share and build on.
The folder structure
The skill is a directory of markdown files.
1salesforce-ada-agent-skills/
2 ├── CLAUDE.md # Global rules
3 ├── .mcp.json # MCP server config
4 ├── .claude/
5 │ └── skills/
6 │ ├── learn/
7 │ │ └── SKILL.md # Learning workflow
8 │ └── decide/
9 │ └── SKILL.md # Pipeline steps, constraints
10 ├── knowledge/
11 │ ├── formats/ # Shared output templates
12 │ │ ├── options-format.md # Template for solution options table
13 │ │ ├── criteria-format.md # Template for assessment criteria
14 │ │ ├── risk-matrix-format.md
15 │ │ └── decision-format-*.md # Templates for decision record output
16 │ ├── scoring/ # Decision score methodology
17 │ └── modifiers/ # Composable lenses
18 └── output/
19 └── decisions/ # Generated decision recordsCLAUDE.md at the repo root defines the scoring pillar weights, MCP source-selection rules, and hard constraints that apply across the decision skill. The skill file (SKILL.md) handles pipeline sequencing; CLAUDE.md handles the rules that govern every step.
SKILL.md loads when you type /decide and controls the pipeline sequence. Format files are templates that the agent copies rather than interprets, producing consistent output regardless of conversation length. The scoring methodology loads only at the final step. This is about 350 lines of rubric detail that would compete for attention during discovery if inlined earlier.
Splitting files this way means you can iterate on a format without touching pipeline logic, swap scoring dimensions without changing steps, and keep the context window lean at each stage.
You are the expert
At every transition the agent pauses and asks whether you’re happy to proceed. You can reshape the analysis at any gate: add an option, remove a criterion, or challenge a rating. The pipeline prevents a flawed assumption in step one from propagating unchallenged to the recommendation. It makes the most of your real-world experiences and helps produce a higher quality output.
Research early and broadly, then verify claims
The initial research in the options step uses a broad query, so competing approaches surface together rather than being cherry-picked individually. Each proposed option is validated against documentation before being presented, and every factual claim in the risk matrix is verified with a targeted search before a rating is assigned. This layered approach balances breadth (discover all options fairly) with depth (no ungrounded claim reaches the final score).
The skill works without any MCP (Model Context Protocol) server that can search documentation. It falls back to web search or the agent’s training knowledge and clearly states which grounding method it’s using. But documentation quality drives decision quality, so I built salesforce-content, a custom MCP server that provides keyword and vector search across recent official documentation from the admin, developer, and architect ecosystems. Any documentation on MCP will work (the repo ships with a Context7 configuration as a zero-setup alternative), but salesforce-content is preferred because it indexes trusted Salesforce sources directly rather than relying on web search, which often misses key information when the source is hard to parse.
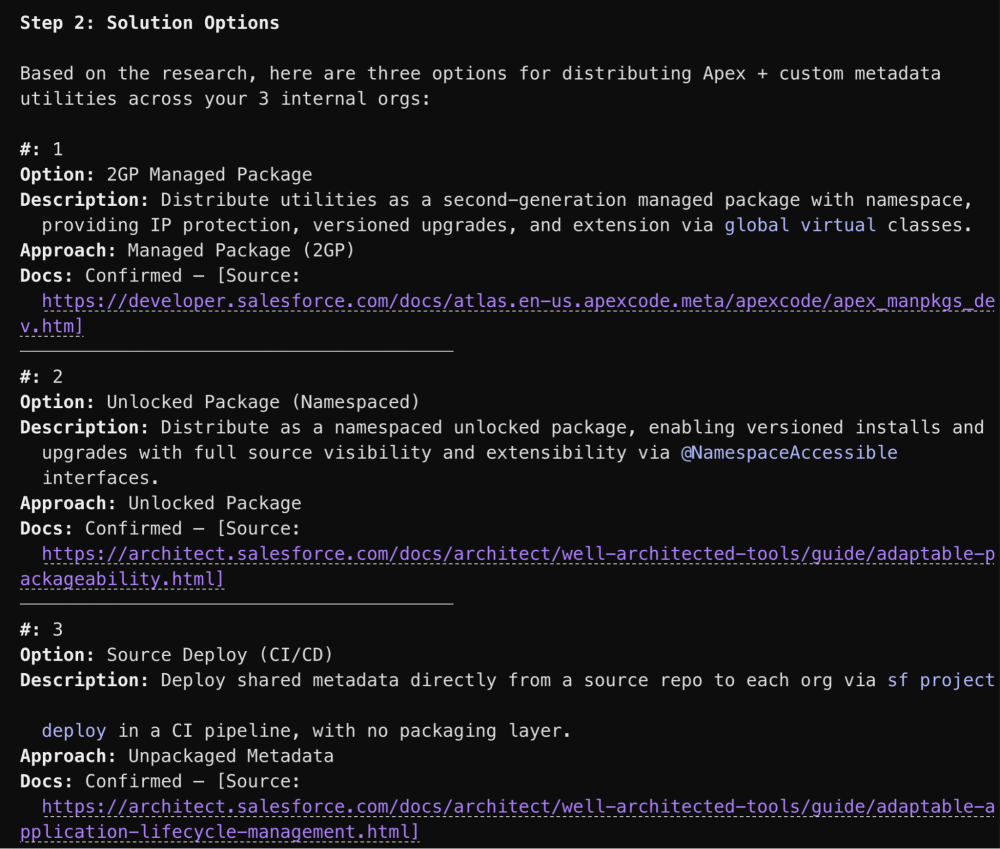
Separate format files for every output step
Each step has its own template file specifying the exact table structure. The agent follows a concrete template more reliably than prose instructions. Splitting them from the pipeline logic means you can iterate on a format without touching the steps.
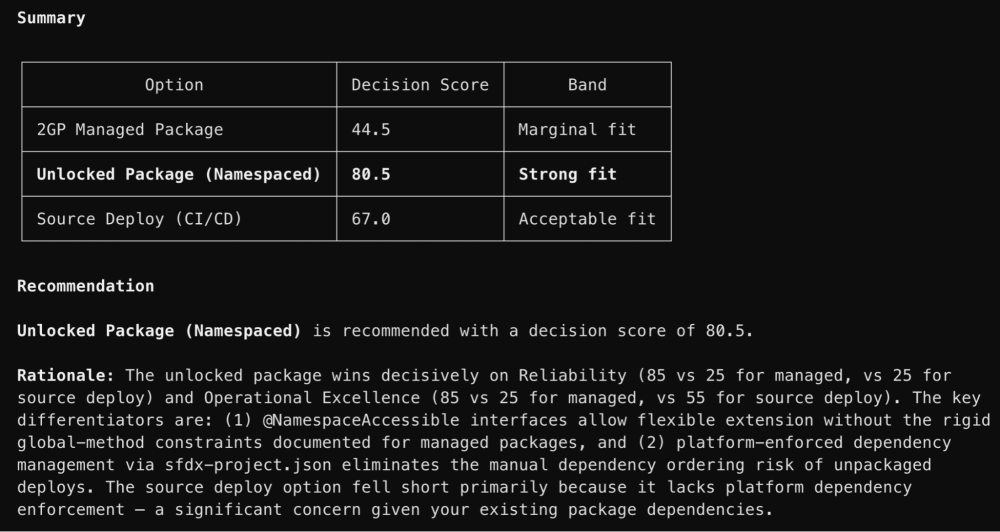
A mechanical score the agent can self-verify
Risk ratings map to fixed confidence values (Low risk = 85, Medium risk = 55, High risk = 25), weighted across pillars (Trust 20%, Reliability 20%, Operational Excellence 20%, Resource Optimization 15%, Cost Optimization 15%, Fairness 10%), and summed up into a single decision score per option. The invariant: the highest score must be the recommendation. The agent verifies this by comparing two numbers and prompt instructions to make sure there is no judgement or reasoning applied. Fixed values remove ambiguity. Pinning each level to a single value makes the score fully deterministic from the risk matrix.
I am using optimized bands based on the direction being taken by the Well-Architected framework, but these can be changed based on your preference.
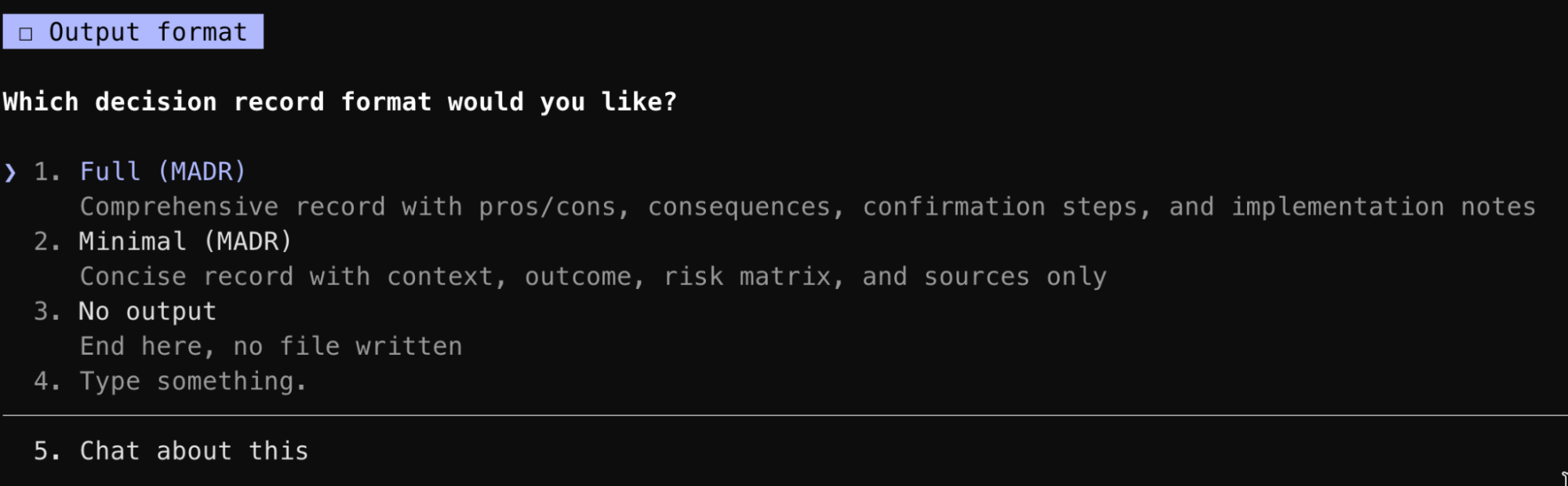
An output that can be shared
Key decisions should be documented. New team members should understand the reasons behind a technical choice and allowing the output to be persistently stored was a key design choice. For this skill, I chose an Architectural Decision Record (ADR) in markdown using the option for a minimal or verbose output.
Build your own decision-scoring skill
The skill is a transferable pattern. It can be adapted to your preferred steps, scoring mechanism, and agent.
| Step | What to consider |
| 1. Define pipeline steps | What context do you need before listing options? What dimensions matter for scoring? |
| 2. Choose dimensions and weights | What does your organization optimize for? Assign percentages that sum up to 100. |
| 3. Write format files | For each step that produces output, create a template showing the exact structure. Include a confirmation prompt. |
| 4. Write your scoring mechanism | Define risk-to-score bands. State the invariant: highest score wins. |
| 5. Ground in external data | Connect a documentation MCP server, or let the agent fall back to web search. Any MCP that returns docs works; the skill describes what to search for, not which tool to call. The quality of decisions depends on the quality of the sources. |
| 6. Repeat rules that matter | Your most important constraint should appear in at least two files. Agents lose track over long conversations. |
Get started
Clone the repo, follow the instructions from the readme, and type /decide followed by your question.
I built this because feedback loops matter. You can see the reasoning decomposed into a matrix of specific, citable claims, rather than a wall of persuasive prose. With a skill like this, you make better decisions, catch assumptions faster, and leave a record of the decision that the next person can actually use.
Resources
- Docs: Anthropic skills documentation
- Docs: Anthropic skills best practices
- Docs: Salesforce Well-Architected
- Video: The Next Chapter of the Well-Architected Framework
About the author
Dave Norris is a Developer Advocate at Salesforce. He’s passionate about making technical subjects broadly accessible to a diverse audience. Dave has been with Salesforce for over a decade, has over 40 Salesforce and MuleSoft certifications, and became a Salesforce Certified Technical Architect in 2013.




