
Appearance
Exercise 1: Ingest Unstructured Data
Coral Cloud Resorts stores various types of information as PDFs in Amazon S3. Check out some of these PDFs below to familiarize yourself with their content:
In this exercise, you'll ingest the unstructured data from those PDFs into Data Cloud.
Step 1: Create an unstructured data lake object
Unstructured data is stored in an unstructured data lake object (UDLO). A UDLO functions like a DLO, but it is specifically designed to define unstructured data.
Using the App Launcher, open the Data Cloud application.
Click Data Lake Objects, then click New.
Select From External Files and click Next.
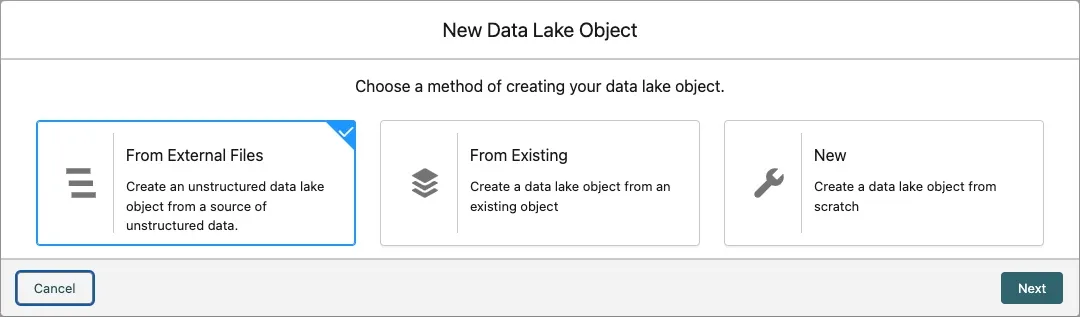
Select Amazon S3 and click Next.

Fill out the connection details as follows:
Label Value Select connection Coral Cloud S3 ConnectionDirectory /agentforce-ragFile Name Pattern *.pdfUse the screenshot below to confirm that you entered all the values correctly.
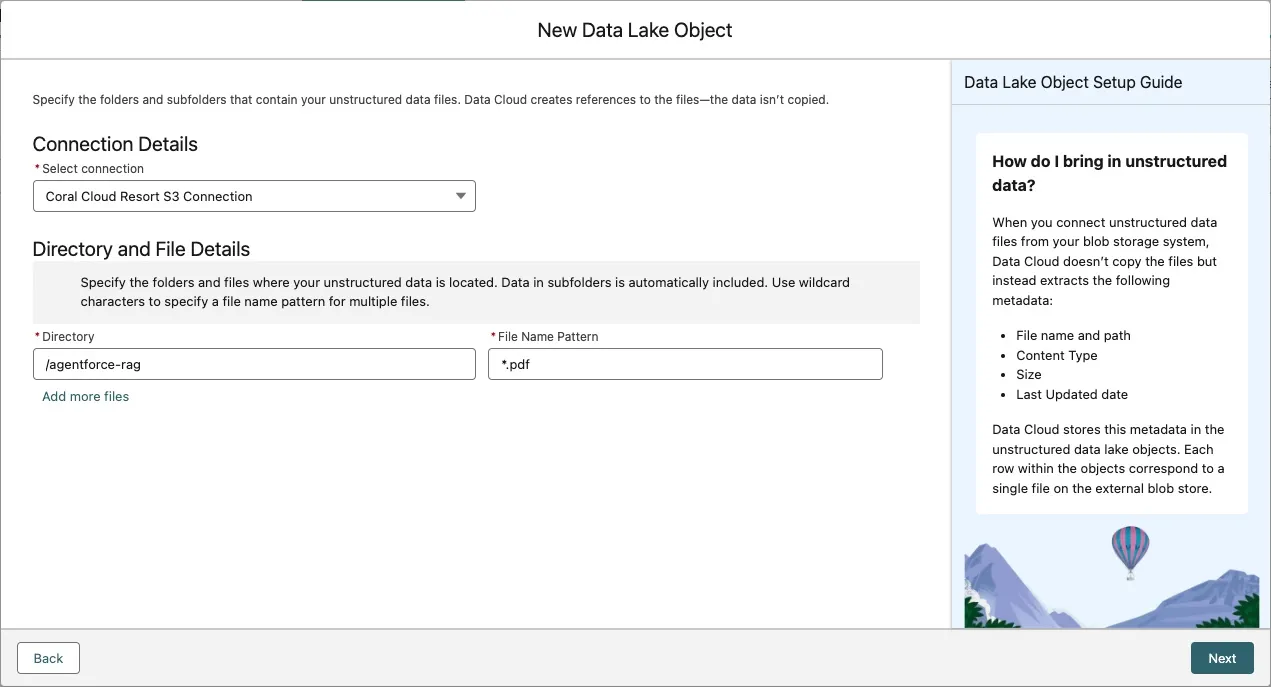
Click Next.
Configure the unstructured data lake object and the unstructured data model object:
Label Value UDLO Object Name Resort InformationUDLO Object API Name Leave default value UDMO Object Name Resort InformationUDMO Object API Name Leave default value Uncheck Enable semantic search with system defaults.
Use the screenshot below to confirm that you entered all the values correctly.
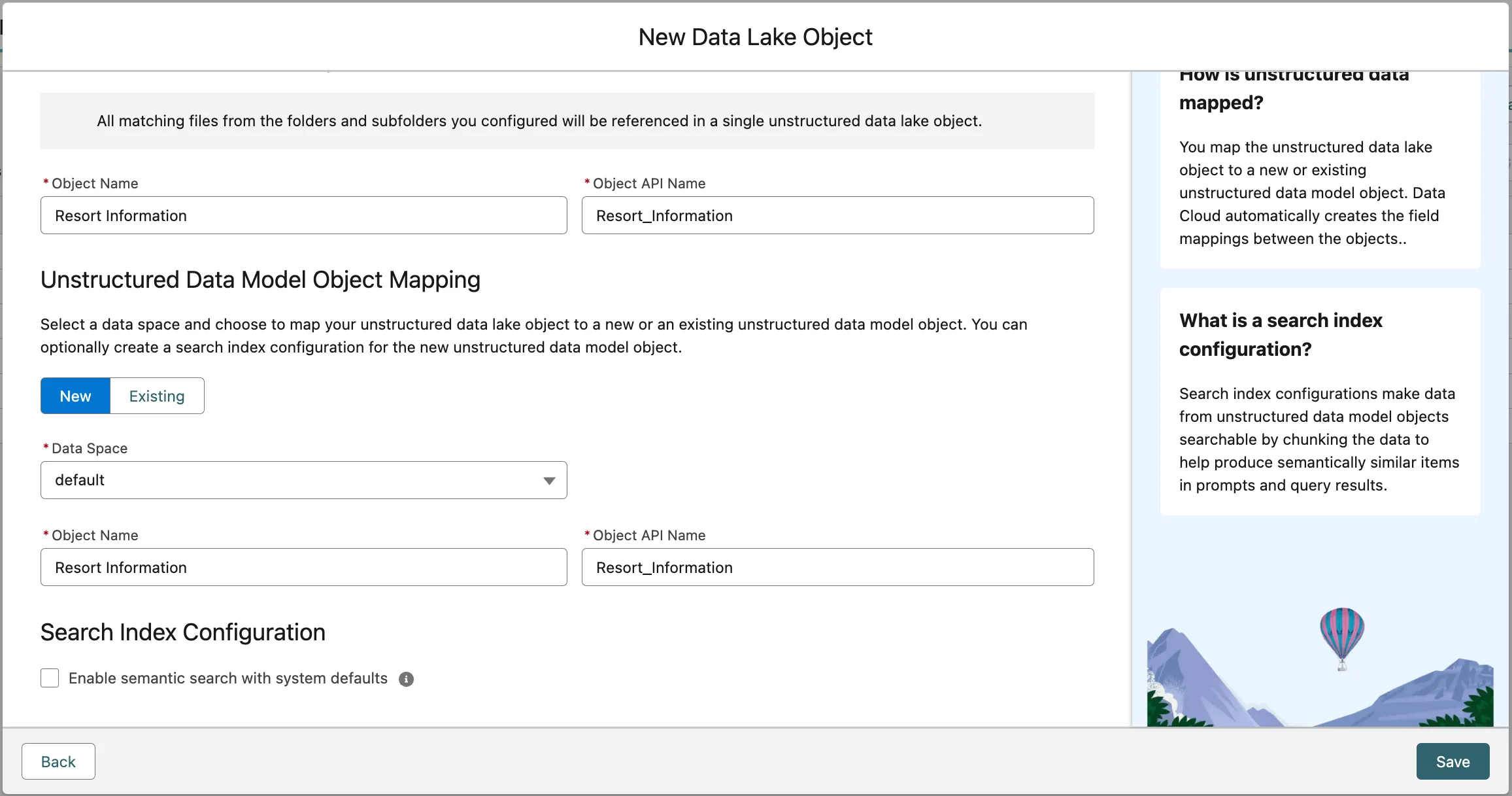
Click Next.
Leave the Search Index Configuration Details as is, and click Save.
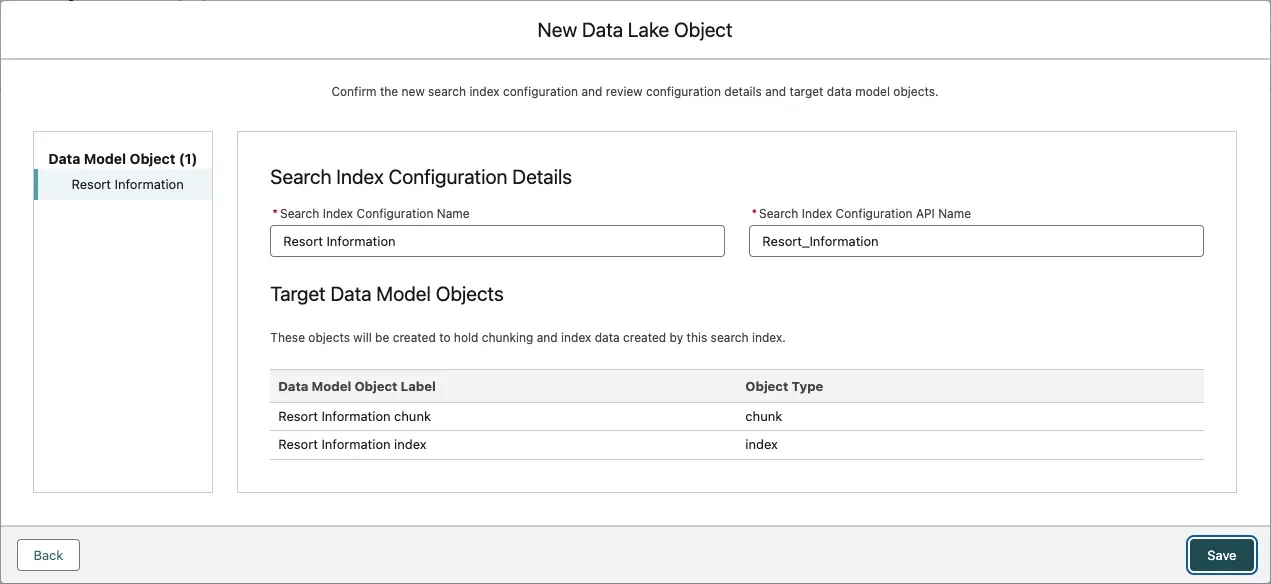
Step 2: Create a search index
In this step, you will create vector index using an index and chunk DMO.
In the Data Cloud App, Click Search Index Tab, then click New.
Select Easy Setup and click Next.
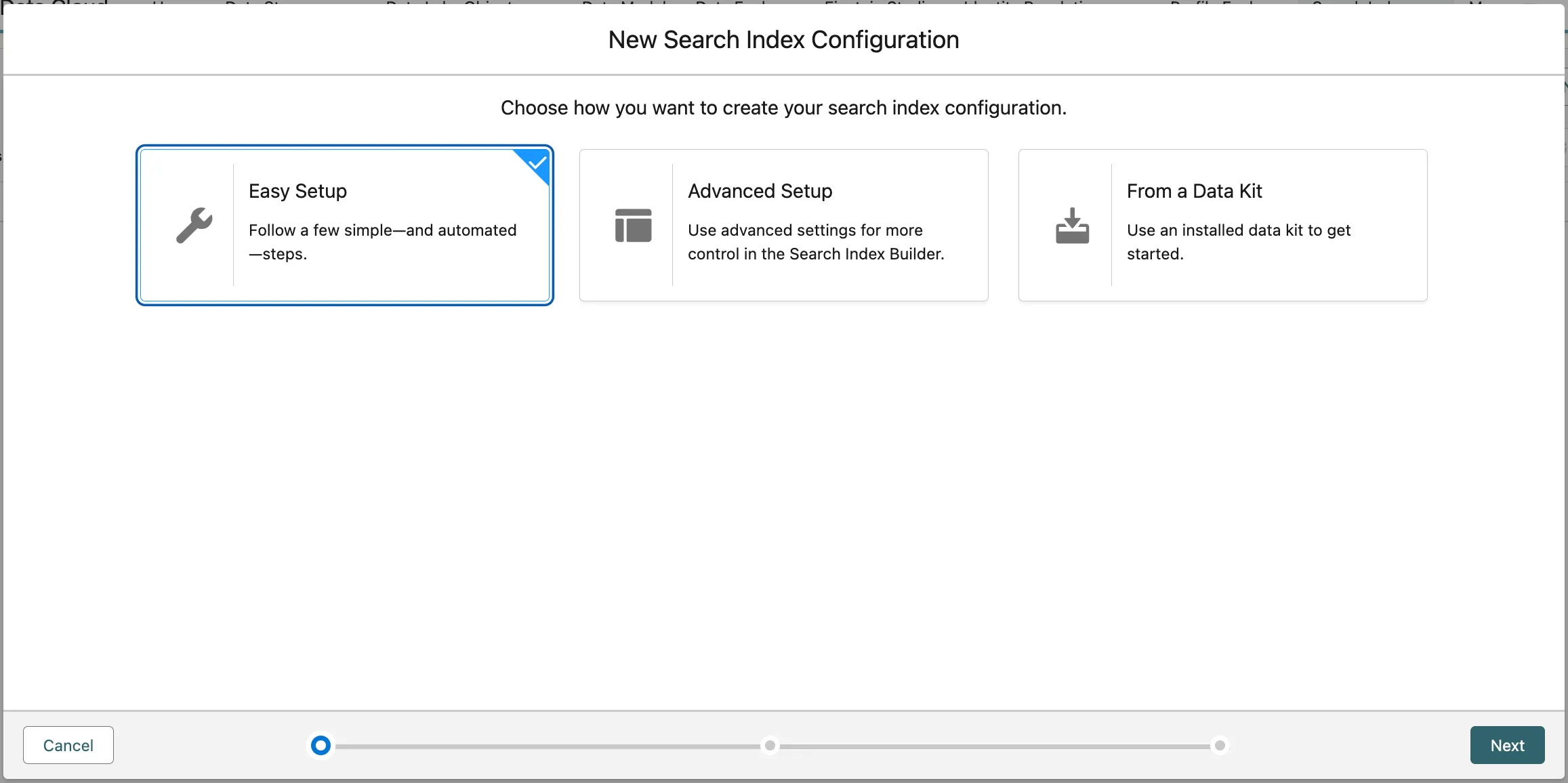
Select Resort Information and click Next.
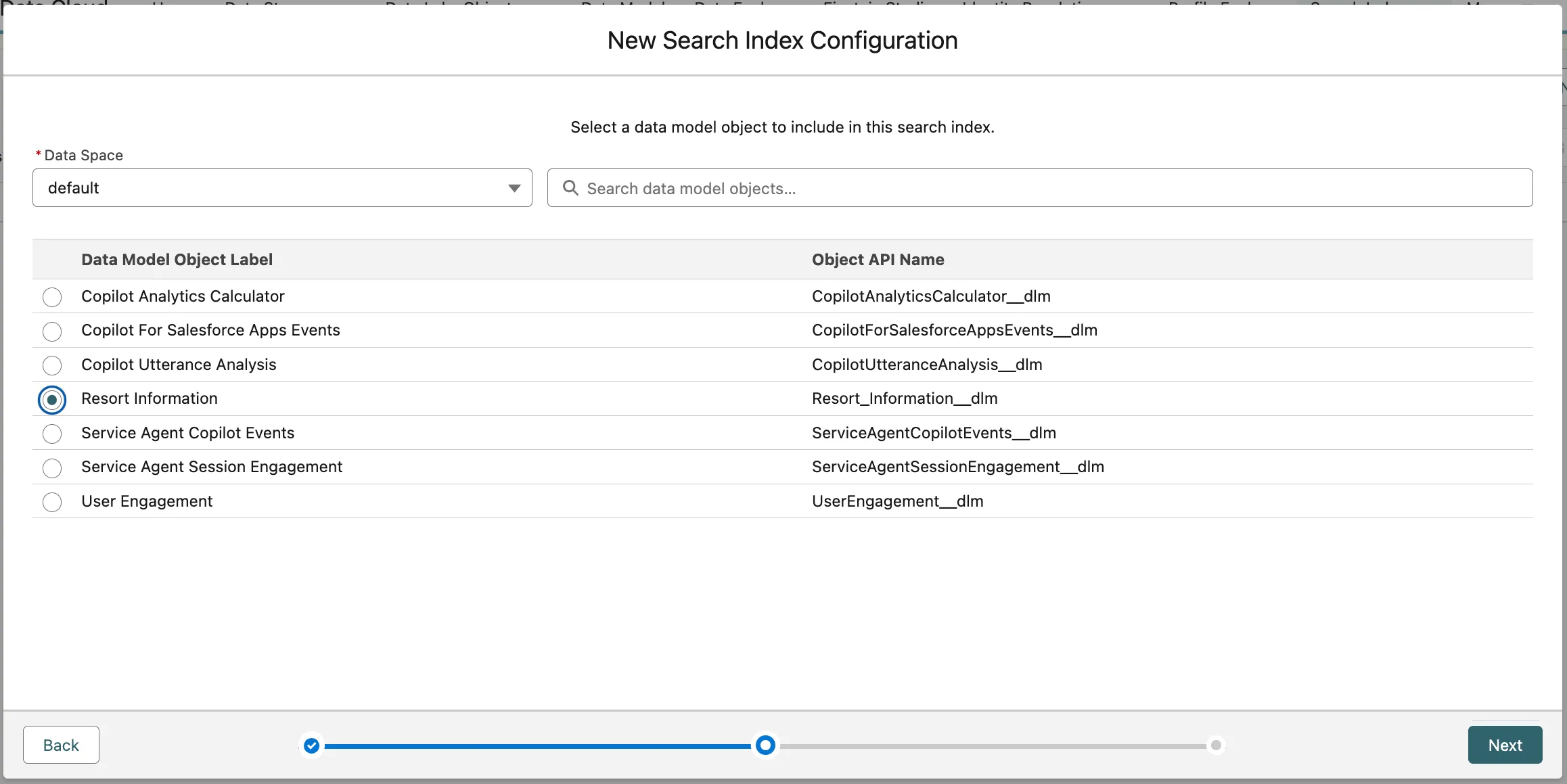
Leave the default values and click Save.
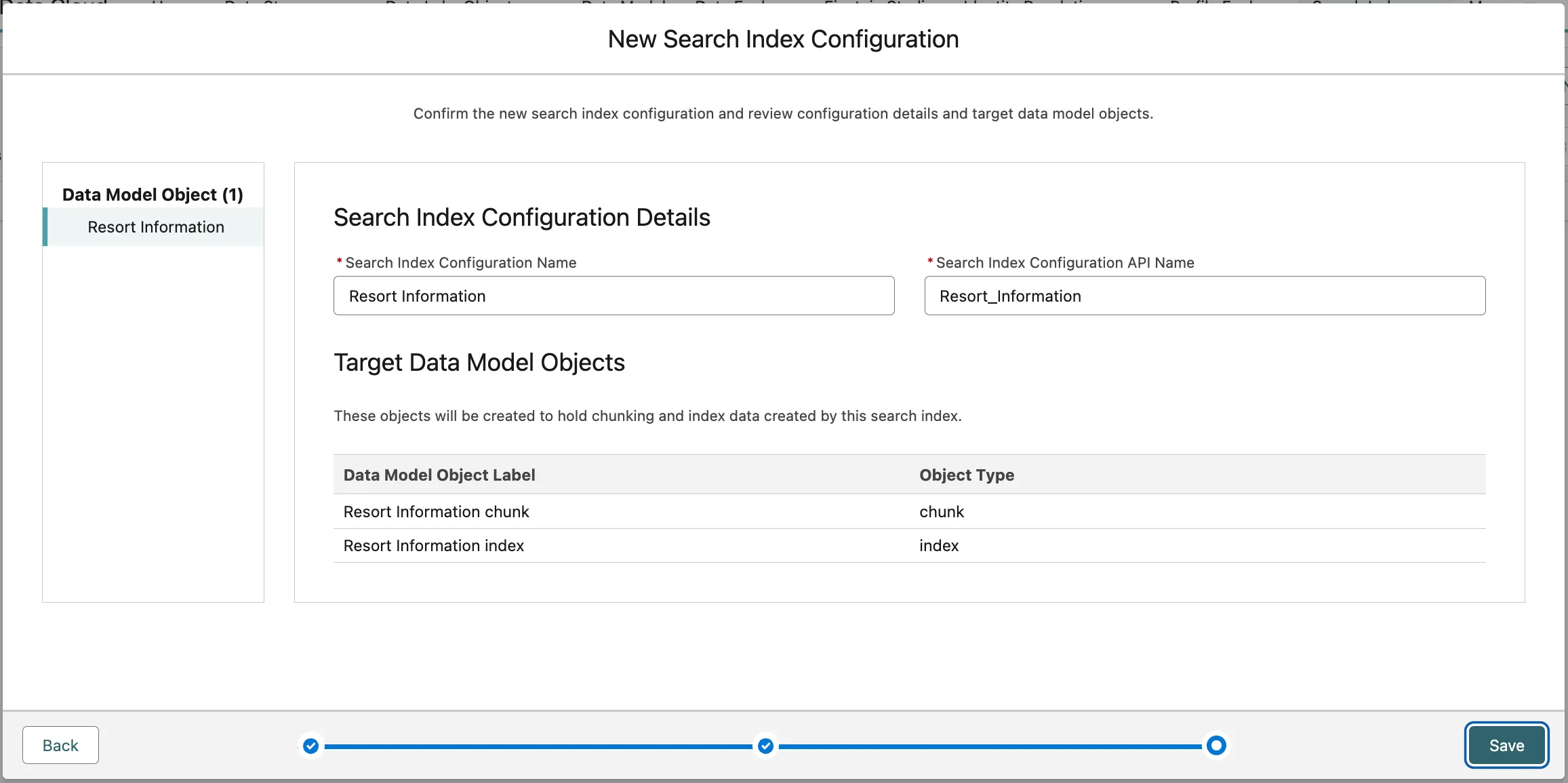
Your vector database is now configured and ready for documents to be indexed.
Step 3: Authenticate S3 file notifications
In this step, you'll authenticate a connected app with your Data Cloud org to allow S3 to send file change notifications.
In your browser window, replace the URL segment that comes after lightning.force.com with:
txt/services/oauth2/authorize?response_type=code&client_id=3MVG9suI4ZYS8sz7iwV98UZRCwt4F_Y6qfMuQsFD_oXbaD__oUpSTCdFbBJt2BRo2co0aro9kvAMGUF1UWZkN&scope=api refresh_token cdp_ingest_api&redirect_uri=https://salesforce.com&code_challenge=SHA256Press Enter.
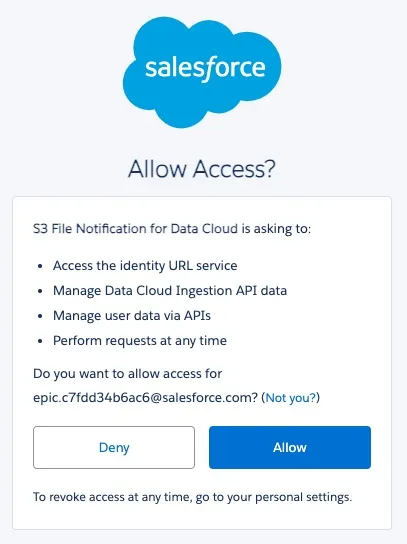
In the installation dialog click Allow.
Step 4: Authorize the connected app
For security reasons the connected app needs to be authorized after installation.
In Setup, enter "connected apps" in Quick Find, and select Connected Apps OAuth Usage.
Click Install for the entry S3 File Notification for Data Cloud.
In the installation dialog click Install.
Step 5: Trigger an S3 file notification
Since we're using a file in a shared S3 bucket, we'll simulate a file change, which will then trigger the ingestion process in your Data Cloud instance.
To simulate a file change, enter your workshop's org username (not email address) in the field below, then click Authenticate.
Once the file notification is successfully triggered, it will take a few minutes for the data to be ingested into your Data Cloud instance.
Step 6: Validate unstructured data ingestion
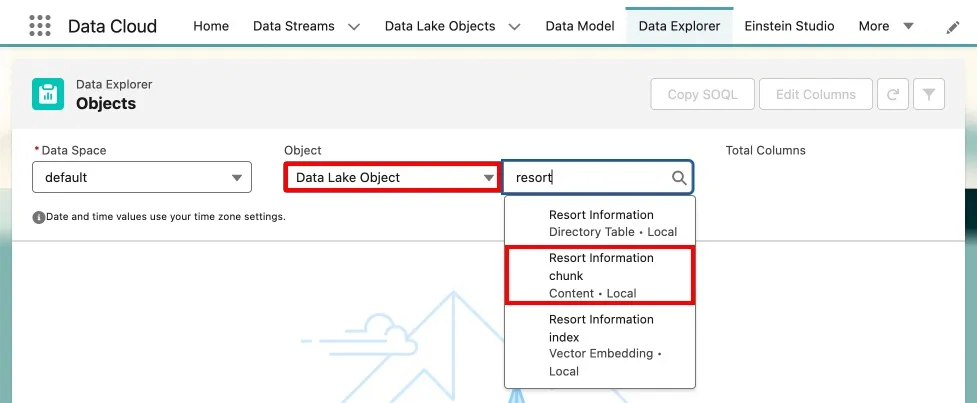
In the Data Cloud app, click Data Explorer.
In the Object dropdown, select Data Lake Object, then select Resort Information chunk.
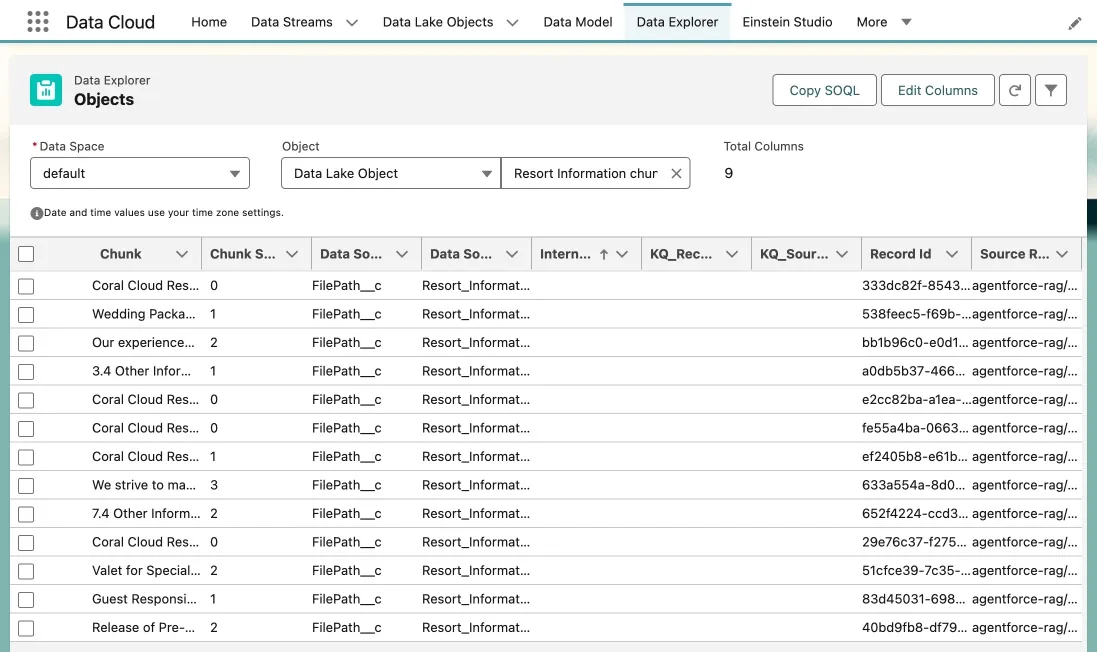
The list of ingested chunks from the PDF files appears.
Summary
In this exercise, you ingested unstructured data from PDFs stored in Amazon S3 into Data Cloud. This unstructured data is now available for search use cases, for example, in prompt templates or via the Data Cloud Query API.